
The emergence of large language models (LLMs) has revolutionized the way people create text and interact with computing. However, these models are limited in ensuring the accuracy of the content they generate and enforcing strict compliance with specific formats, such as JSON and other computer programming languages. Additionally, LLMs that process information from multiple sources face notable challenges in preserving confidentiality and security. In sectors like healthcare, finance, and science, where information confidentiality and reliability are critical, the success of LLMs relies heavily on meeting strict privacy and accuracy standards. Current strategies to address these issues, such as constrained decoding and agent-based approaches, pose practical challenges, including significant performance costs or the need for direct model integration, which is difficult.
The AI Controller Interface and program
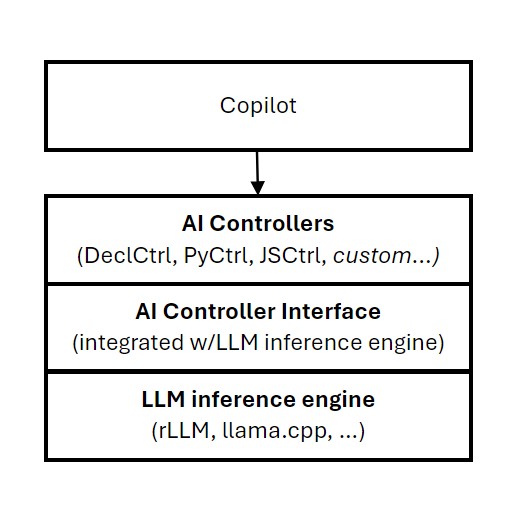
To make these approaches more feasible, we created the AI Controller Interface (AICI). The AICI goes beyond the standard “text-in/text-out” API for cloud-based tools with a “prompt-as-program” interface. It’s designed to allow user-level code to integrate with LLM output generation seamlessly in the cloud. It also provides support for existing security frameworks, application-specific functionalities, fast experimentation, and various strategies for improving accuracy, privacy, and adherence to specific formats. By providing granular-level access to the generative AI infrastructure, AICI allows for customized control over LLM processing, whether it’s run locally or in the cloud.
A lightweight virtual machine (VM), the AI Controller, sits atop this interface. AICI conceals the LLM processing engine’s specific implementation, providing the right mechanisms to enable developers and researchers to agilely and efficiently work with the LLM, allowing them to more easily develop and experiment. With features that allow for adjustments in decision-making processes, efficient memory use, handling multiple requests at once, and coordinating tasks simultaneously, users can finely tune the output, controlling it step by step.
Spotlight: Blog post

Eureka: Evaluating and understanding progress in AI
How can we rigorously evaluate and understand state-of-the-art progress in AI? Eureka is an open-source framework for standardizing evaluations of large foundation models, beyond single-score reporting and rankings. Learn more about the extended findings.
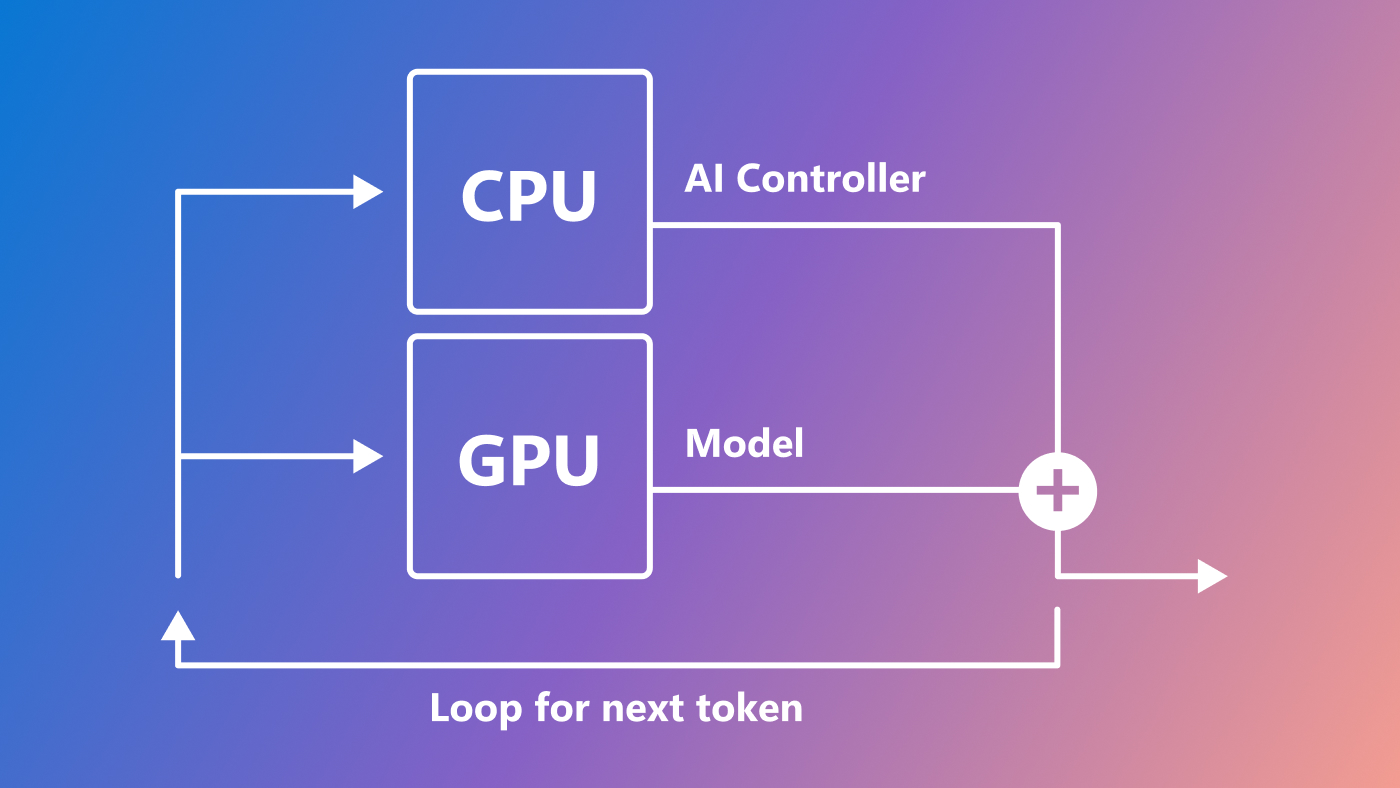
An individual user, tenant, or platform can develop the AI Controller program using a customizable interface designed for specific applications or prompt-completion tasks. The AICI is designed for the AI Controller to run on the CPU in parallel with model processing on the GPU, enabling advanced control over LLM behavior without impacting its performance. Additionally, multiple AI Controllers can run simultaneously. Figure 1 illustrates the AI Controller architecture.
AI Controllers are implemented as WebAssembly VMs, most easily written as Rust programs. However, they can also be written in any language that can be compiled into or interpreted as WebAssembly. We have already developed several sample AI Controllers, available as open source (opens in new tab). These features provide built-in tools for controlled text creation, allowing for on-the-fly changes to initial instructions and the resulting text. They also enable efficient management of tasks that involve multiple stages or batch processing.
High-level execution flow
Let’s take an example to illustrate how the AI Controller impacts the output of LLMs. Suppose a user requests the completion of a task, such as solving a mathematical equation, with the expectation of receiving a numeric answer. The following program ensures the the LLM’s response is numeric. The process unfolds as follows:
1. Setup. The user or platform owner first sets up the AICI-enabled LLM engine and then deploys the provided AI Controller, DeclCtrl, to the cloud via a REST API.
2. Request. The user initiates LLM inference with a REST request specifying the AI Controller (DeclCtrl), and a JSON-formatted declarative program, such as the following example.
{"steps": [
{"Fixed":{"text":"Please tell me what is 122.3*140.4?"}},
{"Gen": {"rx":" ^(([1-9][0-9]*)|(([0-9]*)\.([0-9]*)))$"}}
]}Once the server receives this request, it creates an instance of the requested DeclCtrl AI Controller and passes the declarative program into it. The AI Controller parses its input, initializes its internal state, and LLM inference begins.
3. Token generation. The server generates tokens sequentially, with the AICI making calls to the DeclCtrl AI Controller before, during, and after each token generation.
pre_process()is called before token generation. At this point, the AI Controller may stop generating (e.g., if it is complete), fork parallel generations, suspend, or continue.mid_process()is called during token generation and is the main entry point for computation in the AI Controller. During this call, the AI Controller can return logit biases to constrain generation, backtrack in the generation, or fast forward through a set of fixed or zero-entropy tokens. Themid_process()function runs in parallel with model inference on the GPU and its computation (e.g., of logit biases) is incorporated into the model’s token sampling on the GPU.post_process()is called once the model has generated the next token. Here, the AI Controller may, for example, perform simple bookkeeping, updating its state based on the sampled token.
During these calls, the DeclCtrl AI Controller executes the necessary logic to ensure that the LLM generation conforms to the declarative program provided by the user. This ensures the LLM response is a numeric solution to the math problem.
4. Response. Once DeclCtrl completes its program, it assembles the results, which might include intermediate outputs, debug information, and computed variables. These can be returned as a final response or streamed to show progress. Finally, the AI Controller is deallocated.
Use cases
Efficient constrained decoding
For Rust-based AI Controllers, we’ve developed an efficient way to check and enforce formatting rules (constraints) during text creation within the aici_abi library. This method involves using a special kind of search tree (called a trie) and checks based on patterns (regular expressions) or rules (context-free grammar) to ensure each piece of text follows specified constraints. This efficiency ensures rapid compliance-checking, enabling the program to seamlessly integrate with the GPU’s process without affecting performance.
While AI Controllers currently support mandatory formatting requirements, such as assigning negative infinity values to disallow invalid tokens, we anticipate that future versions will support more flexible guidance.
Information flow constraints
Furthermore, the AI Controller VM gives users the power to control the timing and manner by which prompts, background data, and intermediate text creations affect subsequent outputs. This is achieved through backtracking, editing, and prompt processing.
This functionality can be useful in a number of scenarios. For example, it allows users to selectively influence one part of a structured chain-of-thought process but not another. It can also be applied to preprocessing background data to remove irrelevant or potentially sensitive details before starting an LLM analysis. Currently, achieving this level of control requires multiple independent calls to LLMs.
Looking ahead
Our work with AICI has led to a successful implementation on a reference LLM serving engine (rLLM) and integrations with LLaMa.cpp. Currently, we’re working to provide a small set of standard AI Controllers for popular libraries like Guidance. In the near future, we plan to work with a variety of LLM infrastructures, and we’re excited to use the open-source ecosystem of LLM serving engines to integrate the AICI, providing portability for AI Controllers across environments.
Resources
Code, detailed descriptions of the AICI, and tutorials are available on GitHub (opens in new tab). We encourage developers and researchers to create and share their own custom AI Controllers.



