

作者:系统智能组
编者按:大语言模型的推理能力一直是人工智能领域的研究热点,但传统依赖大规模数据和参数扩展的预训练方式在提升模型推理能力上逐渐遇到了瓶颈。微软亚洲研究院的最新研究关键计划步骤学习 CPL(Critical Plan Step Learning),旨在将强化学习扩展到更广泛、更复杂的问题场景,并取得了突破性进展。CPL 通过在自我生成的高层次抽象计划上进行强化学习,不仅提升了模型在数学推理任务上的表现,还在多个跨领域推理任务上展现出了卓越的泛化能力。
通过大规模预训练,大语言模型(LLMs)在自然语言处理、数学推理等任务中取得了显著进展。然而,传统依赖大规模数据和参数进行扩展的预训练方式在提升模型推理能力上面临着新的挑战。科研人员相信 LLMs 的能力不止于此,在后训练阶段学习人类的慢思考,特别是通过在自我生成的数据上进行大规模强化学习(Reinforcement Learning, RL)训练,对问题进行全面的分析和推理是实现 LLMs 智能的关键。这种新的强化学习范式在复杂任务上的推理表现取得了前所未有的突破,也为未来的超级智能奠定了技术基础。
但想将强化学习扩展到更广泛、更复杂的问题场景仍面临诸多挑战。传统的强化学习方法,由于其特定的动作空间限制了模型的泛化能力,因此,如何将强化学习对推理能力的提升泛化到更广泛的推理任务丞待解决。此外,与传统强化学习不同,LLMs 的复杂问题推理涵盖了巨大的搜索空间。考虑到 LLMs 推理的高成本,如何在如此庞大的搜索空间中高效且有效地找到正确的解决方案也是一个关键挑战。
为了解决这些问题,微软亚洲研究院的研究员们推出了关键计划步骤学习 CPL (Critical Plan Step Learning),作为扩展强化学习以开发通用推理模型的重要一步。具体来说,该方法提出了一种在高层次抽象计划的动作空间中进行搜索的新方法,以提升模型的泛化能力。通过使用蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)探索多样化的计划步骤,并引入步骤级优势偏好优化算法(Step-level Advantage Preference Optimization, Step-APO)来学习解题中的关键步骤,CPL 帮助模型聚焦于推理过程中的重要决策,显著提升了模型的推理能力和泛化性。
CPL 不仅在数学推理任务中表现突出,还在 HumanEval、GPQA、ARC-C 等跨领域推理基准任务上取得了优异成绩,为大语言模型提升推理能力的泛化性开辟了新的方向。这一工作成功提高了模型在多种跨领域任务中的迁移表现,并为未来强化学习扩展方向的研究做出了一定的贡献。
CPL: Critical Plan Step Learning Boosts LLM Generalization in Reasoning Tasks
https://arxiv.org/pdf/2409.08642 (opens in new tab)
在抽象计划中寻找推理的钥匙
CPL 的核心由两个关键步骤组成——计划搜索和关键计划步骤学习。这些方法旨在有效提升模型在多步推理任务中的推理能力和泛化能力。
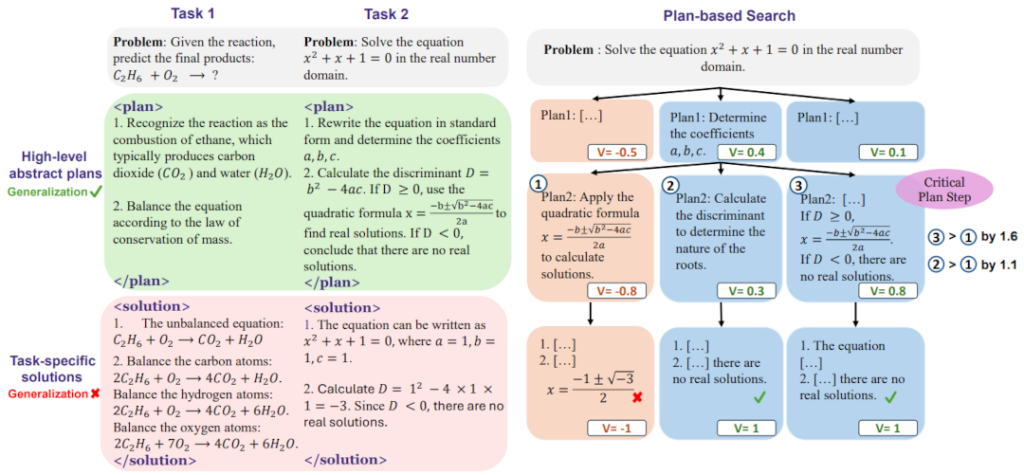
研究员们提出了基于计划的 MCTS(Plan-based MCTS),主要在高层次抽象计划的搜索中帮助 LLMs 探索多样化的解题策略,以应对广阔的搜索空间。不同于传统方法只专注于具体执行步骤的探索,CPL 还强调解决问题的整体思路和策略探索,从而帮助其学习更通用的任务无关技能,显著提升模型在各种推理任务中的泛化能力。具体来说,CPL 通过逐步创建解决问题的计划,并最终给出完整的解答;MCTS 迭代构建出计划树,并生成高质量的计划步骤监督信号。此外在 MCTS 中,研究员们会使用价值模型来评估每个部分推理路径的预期回报,这使得模型在面对复杂推理任务时能够有效选择最优路径,最大限度地减少无效搜索的影响。
步骤级优势偏好优化(Step-APO)是 CPL 的第二个关键组成部分,旨在学习和强化推理过程中的关键步骤。Step-APO 建立在直接偏好优化(Direct Preference Optimization, DPO)的基础之上,进一步结合了 MCTS 中获得的步骤级优势估计,用于更精细地比较不同步骤之间的偏好。传统的偏好学习方法通常通过标记第一个错误步骤为不优来指导模型,但这种启发式方法限制了模型对自生成数据的充分利用。相比之下,Step-APO 可以为每个推理步骤计算其相对于同层其他步骤的“优势值”,从而使得模型能够识别出对最终推理结果至关重要的步骤,并赋予这些关键步骤更高的优化权重。通过这种方式,模型能够更好地识别并强化关键步骤,实现更高效的计划优化与泛化。
结合计划搜索与关键步骤学习让 CPL 有效实现了模型推理能力的全面提升。实验结果表明,即便只在 GSM8K 和 MATH 数据集上进行训练,CPL 依然在多个跨领域推理任务中取得了明显的性能提升,例如 HumanEval、GPQA 和 ARC-C 等跨领域基准任务,充分验证了该方法在大模型推理与泛化方面的显著优势。
CPL的实验性能
研究员们在多个推理基准上对 CPL 方法进行了详尽的实验评估,以验证其在推理能力和泛化性上的表现。整个实验评估从以下三个方面展开:域内推理任务的表现、跨领域推理任务的泛化性,以及不同优化策略的效果。
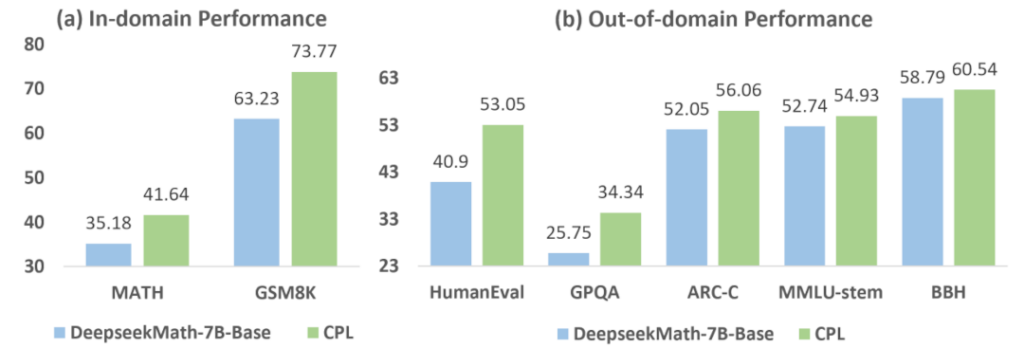
首先,研究员们在数学推理任务 MATH 和 GSM8K 数据集上评估了 CPL 在域内推理任务中的表现。MATH 数据集包含5000个复杂的竞赛级问题,旨在评估模型对高难度数学推理的能力,而 GSM8K 数据集则包含1320道小学数学题目,用以测试基础算术和推理技能。与基准模型 DeepSeekMath-Base 相比,CPL 在这两个数据集上均展示了显著的性能提升。在 MATH 数据集上,CPL 最终取得了41.64%的准确率,相较于基准提升了6.5%;在 GSM8K 上,CPL 的准确率达到了73.77%,比基准提升了10.5%。这表明 CPL 通过高层次计划的学习和关键步骤优化,有效增强了模型在数学推理方面的能力。
其次,研究员们重点评估了 CPL 在五个跨领域推理任务上的泛化能力,分别是 HumanEval、ARC-C、GPQA、BBH 和 MMLU-STEM。这些任务涵盖代码生成、科学知识问答、生物与化学领域的复杂推理等,旨在验证 CPL 在应对不同领域推理任务时的适应性。结果表明,相较于学习特定任务解决方案的模型在跨领域推理任务上表现不佳(如 AlphaMath 在 BBH 任务上出现了2.2%的性能下降),CPL 极大提升了跨领域推理任务的性能。例如,在代码生成的 HumanEval 任务中,CPL 相比基准提升了12.2%;在科学问答的 GPQA 上,CPL 的表现提升了8.6%;在 ARC-C 和 BBH 等任务中,CPL 也展现了优于基准模型的表现。对比基于执行步骤的搜索方法如 AlphaMath 和 Self-Explore,CPL 通过高层次计划的探索与学习,显著增强了模型的泛化能力,使其在面对不同类型的推理任务时表现得更加稳定和优越。
最后,研究员们对比了不同优化策略的效果,包括传统的实例级 DPO(Instance-DPO)、步骤级 DPO(Step-DPO)和 CPL 所使用的步骤级优势偏好优化(Step-APO)。实验结果表明,Step-DPO 相较于 Instance-DPO 在部分任务上有小幅度的性能提升,而 CPL 的 Step-APO 通过更精细的关键步骤学习大大提升了模型的推理性能。在跨领域任务中,Step-APO 的优化效果尤为明显。这说明通过有效识别和学习推理中的关键步骤,CPL 能够显著增强模型的泛化性和推理能力。
构建更智能的通用推理模型
扩展强化学习(Scaling RL)以开发一个通用的推理模型依然是一个开放且重要的研究课题。研究员们提出的 CPL 利用高层次抽象计划的搜索以及关键步骤的优势偏好优化,增强了 LLMs 在推理任务上的泛化能力。
未来,研究员们将增加计划策略多样性,并且结合测试时搜索(test-time search)进一步提升模型的整体推理效果。研究员们也将继续探索如何有效学习推理中的关键步骤,以实现更高效的搜索,为构建更加智能化、具备通用推理能力的语言模型奠定坚实基础。