

作者:梁傑然
编者按:如今计算机系统承载的服务和算法逻辑日益复杂,理解、设计并改进计算机系统已成为核心挑战。面对系统复杂度和规模的指数级增长,以及新的大模型驱动场景下的分布式系统形态的涌现,人们亟需创新方法与技术来应对。在计算机系统发展的新篇章里,现代系统应当是一个不断自我进化的结果。机器学习和大模型的崛起使得现代计算机系统迎来了新的智能化机遇,即学习增强系统(learning-augmented systems)。微软亚洲研究院创新地从两个核心方向,来思考系统应如何不断自我学习和自我进化:“模块化”机器学习模型,与“系统化”大模型的推理思维。目标在于使得模型能够对齐复杂多变的系统环境和需求,并且推理思维能够对齐计算机系统时间和空间上的行为。相关论文 Autothrottle: A Practical Bi-Level Approach to Resource Management for SLO-Targeted Microservices 获评 NSDI 2024 杰出论文奖。
随着技术的不断进步,计算机系统不仅承担着人们生活中众多服务的重任,还包含着许多复杂的算法逻辑。用户需求的多样化与场景的增加,也使得计算机系统的复杂性和规模持续增长。从搜索、购物、聊天到新闻推荐、串流媒体和人工智能服务,这些系统的复杂性不只是庞大的代码量,更体现在背后成百上千工程师在设计、开发及维护上所付出的巨大工作量。与此同时,新类型的场景(比如大模型驱动 co-pilots 和 AI agents)也带来了新兴的分布式系统形态。如何理解、设计并作出改进成为了现代计算机系统的核心挑战。然而,系统复杂度和规模的指数级增长,使得这些挑战已经无法完全依赖人的直觉和经验去解决。

幸运的是,计算机科学的技术更新迭代为计算机系统带来了新的机遇。其中,学习增强系统(learning-augmented systems)正逐渐成为以智能化来重塑计算机系统的新趋势。学习增强系统通常采用三种不同的实现路径:一是通过机器学习技术来辅助增强现有计算机系统中启发式算法和决策规则的性能;二是利用机器学习技术对启发式算法和决策规则进行优化和重新设计;三是用机器学习模型取代原有的启发式算法和决策规则,进而推动系统的全面智能化升级。
为此,微软亚洲研究院的研究员们开展了一系列学习增强系统的工作。研究重点聚焦于两个关键方面:第一,”模块化”机器学习模型,与计算机系统行为进行对齐;第二,”系统化”大模型推理思维,赋予计算机系统自我进化的能力。
“模块化”机器学习模型,与计算机系统行为对齐
机器学习擅长于从数据中提取规律和模式,并利用这些规律进行建模和数值优化,以驱动预测和决策过程。现代计算机系统普遍具有完善的行为和性能监测机制,因此可以作为模型训练的数据来源。在以往的研究中(Metis [1]和 AutoSys [2]),研究员们曾探讨过如何利用机器学习技术优化计算机系统中的系统参数。但实际经验证明,构建学习增强系统不单单是应用现有的机器学习算法,它还面临着现代计算机系统与机器学习协同设计的关键研究挑战。
具体而言,由于现代计算机系统具有高度的规模性(例如,有着上百个分布式微服务的集群)和动态性(例如,集群里的微服务可以被独立开发、部署和扩容),在未来,利用强大的模型来学习整个系统是否还能成为一个可持续的方法?当系统部署与环境发生变化(例如,系统扩容导致集群规模改变),机器学习模型对于任务之前的一些假设可能不再成立。因此,如果不重新训练模型,模型驱动决策的正确性就会受到影响。但现代计算机系统的高动态性和高复杂度,又会使得机器学习在持续学习复杂任务上仍面临着昂贵的数据采集和资源开销成本。
“模块化”是将机器学习融入计算机系统基础的一大关键。虽然现代计算机系统具有高度的规模性和复杂度,但它们实际上是由多个子组件或服务组合而成,其动态性也就有规律可循。以一个由多个微服务组成的云系统为例,如果更新了其中的一个微服务,那么可能会影响到整个系统的端到端性能。但是,从系统架构上来看,这种更新只是更改了某个独立服务的编码配置。同理,系统的扩容,即系统里的某个服务被独立复制并部署了多份,也是如此。因此,如果机器学习模型也只需要相应地修改变化部分,那相比于持续训练整个模型,就将大大地减少学习增强系统的维护成本。
研究员们提出的利用模块化学习模拟端到端系统延迟的框架 Fluxion [3],是在学习增强系统中应用模块化学习(modularized learning)的第一步。在预测微服务系统延迟的任务上,随着个别服务的持续扩容和部署,Fluxion 显著减低了延迟预测模型的维护成本。通过引入新的学习抽象,Fluxion 允许对单个系统子组件进行独立建模,并且通过操作可将多个子组件的模型组合成一个推理图。推理图的输出即为系统的端到端延迟。此外,推理图可以动态地被调整,进而与计算机系统的实际部署进行对齐。这一做法与直接对整个系统进行端到端延迟建模的方法有显著区别。相关论文 On Modular Learning of Distributed Systems for Predicting End-to-End Latency 发表于 NSDI 2023。
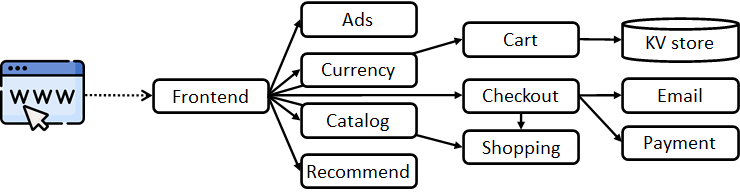
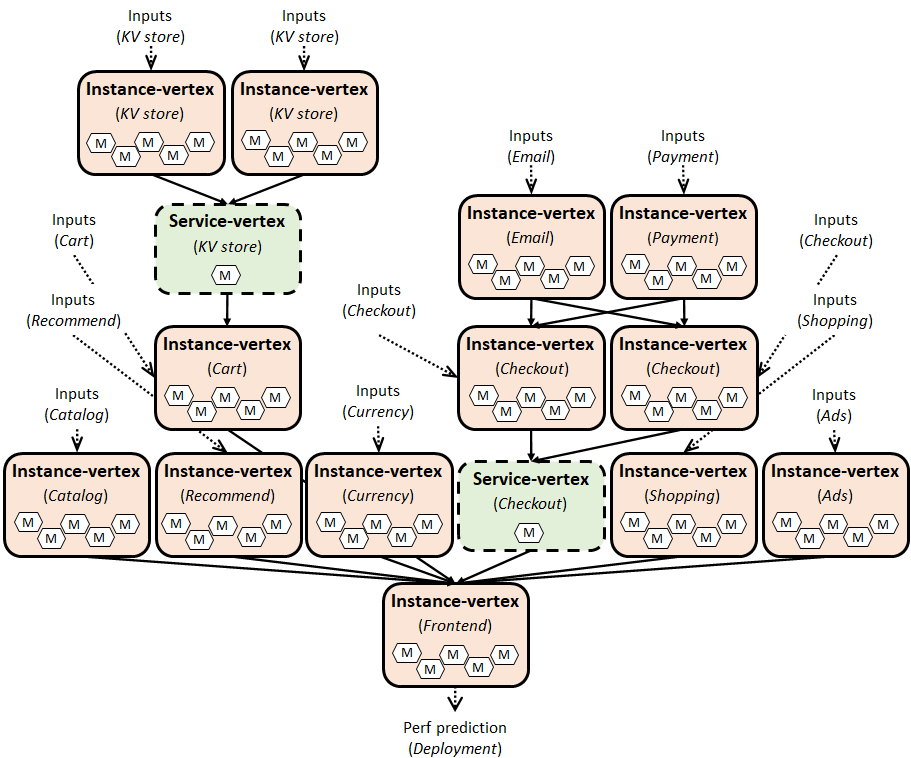
在 Fluxion 框架的基础上,研究员们又提出了针对具有系统延迟目标的微服务的双级资源管理框架 Autothrottle [4],将“模块化”的理念引入到系统资源管理中,特别是自动扩容这一重要任务。自动扩容旨在为每个微服务自动分配适当的资源,以满足用户设定的系统延迟目标(service-level objective)。简单来说,当每秒的用户需求增加时,系统资源也应该相应地自动增加来满足延迟目标。反之,当每秒的用户需求减少时,系统资源也应该相应地自动减少。这种自动扩容机制能够平衡资源分配额度与系统性能。目前,业界常见的作法是使用启发式算法,比如 Kubernetes 的 HPA 和 VPA,但这些算法需要运维人员手动设定阈值并持续调整。
基于这一痛点,机器学习可以作为驱动自动扩容的一个新方法。相关工作结合了深度学习模型(如卷积神经网络和图神经网络)和方法(如强化学习),以对整个系统的全局资源与效能的关系进行建模。虽然复杂的模型能学习到系统全局的复杂关系,但训练这些模型仍需昂贵的数据采集和资源开销成本。
在模块化的设计理念下,Autothrottle 将自动扩容分解为一系列简单的子学习问题,类似于Fluxion,每个问题对应系统中的一个微服务。虽然每个微服务的资源分配都是独立的,但 Autothrottle 的设计考虑到了微服务的局部延迟会共同影响系统的全局延迟。所以,当系统的全局延迟过高(或过低)时,Autothrottle 可以预测每个微服务需要同等增加(或降低)多少的局部延迟目标。基于这些目标,每个微服务再自主根据自己的当前负载,来预测所需的资源分配(如 CPU)。
研究员们发现,CPU throttle 指标(在特定时间段内,一个进程的 CPU 额度被用尽的次数)很适合作为局部延迟目标。所以,如果一个微服务的负载较重,应增加该微服务的 CPU 资源分配,以满足指定的 CPU throttle 目标。反之,当负载较轻时,应减少 CPU 资源,来满足指定的 CPU throttle 目标。
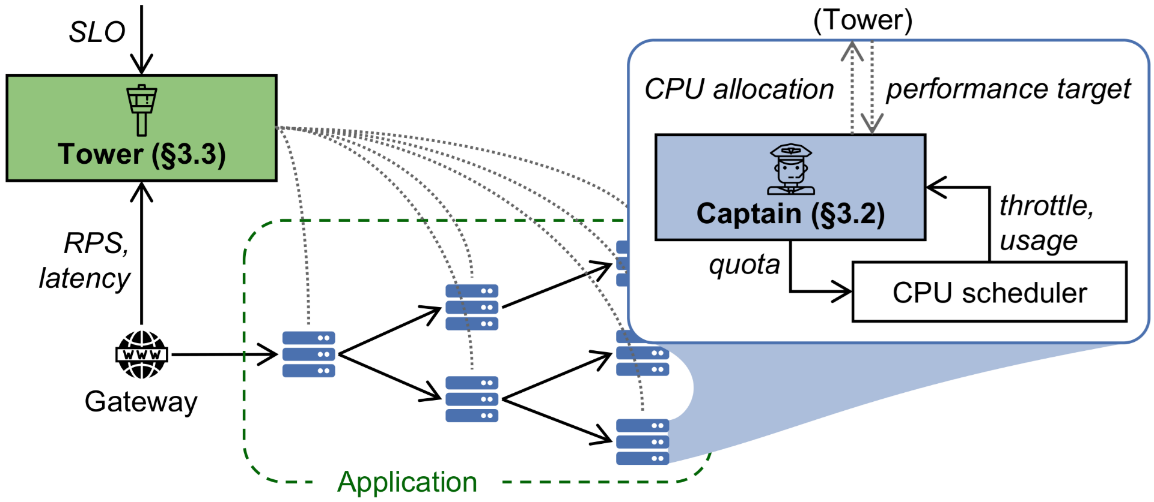
基于系统的全局延迟历史,Autothrottle 的 Tower 组件使用 contextual bandit 算法来计算局部延迟目标,而 Autothrottle 的 Captain 组件则在每个微服务上使用反馈控制回路来快速调整 CPU 资源分配。这种模块化的设计方法为系统资源管理提供了更加高效和精准的解决方案。相关论文 Autothrottle: A Practical Bi-Level Approach to Resource Management for SLO-Targeted Microservices 获评 NSDI 2024 杰出论文奖。
“系统化”大模型推理思维,赋予计算机系统自我进化的能力
大模型的崛起给学习增强系统带来了新的智能化机遇。在学术界和工业界,众多研究正利用大语言模型,来理解并分析计算机系统的长文档、日志、代码等。同时,许多研究也在致力于帮助工程师生成程序代码和运维指令。这些研究共同展示了大模型在人类和计算机系统交互中的潜力。
微软亚洲研究院的研究员们认为,大模型的更大价值在于赋予现代计算机系统自我进化的能力。如同传统机器学习的数值优化能力,大模型的推理思维能力也令人着迷。如果计算机系统能够思考自己(时间和空间上)的行为是否合理,并用思维链来推理自己的行为应该如何变化,那么计算机系统则能自我进化。研究员们相信,自我进化会是计算机系统发展的一个重大范式转变。
回顾计算机的发展历程,从计算工具如算盘和数据表,到现代计算机系统如大数据和云计算,再到新兴的分布式系统如 AI agents 和具身机器人等,系统迭代的瓶颈主要在于人类的脑力和生产力。而大模型的推理思维有望突破这一瓶颈,加速计算机系统的迭代。
那么,如何才能系统化大模型的推理思维,进而对计算机系统的行为进行思考?微软亚洲研究院的研究员们正积极地从三个方向展开:
(1) 大模型本身对于计算机系统的基础知识储备
(2) 大模型的思维链如何与计算机系统(时间和空间上)的行为对齐
(3) 大模型驱动的学习增强系统的实际应用
未来,微软亚洲研究院将持续致力于学习增强系统的研究与应用,并期待与志同道合的研究者共同解决这些挑战。
相关论文链接:
[1] Metis: Robustly Optimizing Tail Latencies of Cloud Systems. Zhao Lucis Li, Chieh-Jan Mike Liang, Wenjia He, Lianjie Zhu, Wenjun Dai, Jin Jiang, Guangzhong Sun. USENIX ATC ’18.
[2] AutoSys: The Design and Operation of Learning-Augmented Systems. Chieh-Jan Mike Liang, Hui Xue, Mao Yang, Lidong Zhou, Lifei Zhu, Zhao Lucis Li, Zibo Wang, Qi Chen, Quanlu Zhang, Chuanjie Liu, Wenjun Dai. USENIX ATC ’20.
[3] On Modular Learning of Distributed Systems for Predicting End-to-End Latency. Chieh-Jan Mike Liang, Zilin Fang, Yuqing Xie, Fan Yang, Zhao Lucis Li, Li Lyna Zhang, Mao Yang, and Lidong Zhou. USENIX NSDI ’23.
[4] Autothrottle: A Practical Bi-Level Approach to Resource Management for SLO-Targeted Microservices. Zibo Wang, Pinghe Li, Chieh-Jan Mike Liang, Feng Wu, Francis Y. Yan. Outstanding Paper Award of USENIX NSDI ’24.
链接:http://approjects.co.za/?big=en-us/research/publication/autothrottle/