

The use of modeling and simulation in engineering is well recognized as a viable method to build surrogates for real-world systems. Simulation allows for testing and evaluation of large and complex systems in a risk-free environment, helping document failures, reduce costs, and increasing the quality of developed systems. Simulation also plays a key role in AI – either for obtaining training data in an inexpensive manner, or in deep reinforcement learning which requires a large volume of interactions with the environment to learn effective policies. However, traditional simulators often require significant engineering effort and expert knowledge for creation, while also being computationally intensive for complex systems. A more efficient alternative is to learn data-driven simulations, which involves the use of machine learning algorithms to learn system dynamics directly from observations or data traces from existing simulators.
Current efforts in building data-driven simulations have been driven by a class of machine learning models known as “mechanistic models”. Mechanistic models attempt to incorporate well-understood priors, some examples of which are neural differential equations or physics informed neural networks. Although effective, many such data-driven simulations often attempt to learn simulator behavior in an end-to-end manner. This results in monolithic simulation blocks that are only valid for a particular system configuration and cannot easily transfer or generalize to new configurations. On the other hand, most real systems are inherently modular and can be decomposed into reusable subsystems.
In our recent paper Learning Modular Simulations for Homogeneous Systems (opens in new tab), we examine the idea of building data-driven simulations in a modular fashion, which would allow re-use and re-configuration of our individual modules. Such an approach can result in several gains for data-driven simulations, some of which are:
- Creation of reusable pretrained simulation nodes which can be transferred or rapidly finetuned for new scenarios in a data-efficient manner.
- Smaller models that represent individual subsystems whose weights can be shared across a network, instead of a large graph – reducing the overall computational efforts required in training.
- Enhanced adaptability of our simulation system for new configurations.
A large amount of literature on data-driven simulations has explored the idea of building simulations through graph neural networks, such as the method in Learning to Simulate Complex Physics with Graph Networks (opens in new tab). Such networks attempt to model the entire graph, processing state and control inputs at every timestep into graph embeddings and computing the evolution of the graph through a hidden representation. Learning the entire graph in this fashion runs the risk of creating simulation nodes which are not independent, but rather the hidden representation is a function of the exact arrangement of neighbors in the graph. Within the hidden state, the entire graph needs to be communicated as it evolves through time, creating a large overhead. Finally, such approaches lack generalizability.
Given the inherent modularity of several real-life systems, we propose a method which places focus on individual nodes instead of the full graph. Our approach uses Neural Ordinary Differential Equations (opens in new tab) (NODE) to model a single dynamic entity. The primary function of the NODE is to ingest the current state & control action and predict the future state after a given amount of elapsed time.

To enable interaction between neighboring nodes, we augment this NODE with “message variables”, thus creating a message-passing neural ODE (MP-NODE). The MP-NODE has an additional output along with the next state prediction, representing a continuous-valued message which is sent to other simulation nodes for coordination. Similarly, each MP-NODE also has a message input, through which it consumes aggregated messages from its neighboring nodes. This forms the basic unit of our overall simulation learning framework. Because the message passing happens in parallel to the individual simulation node, the nodes can continue focusing on learning the dynamics rules for the single entity. Based on the messages obtained at every node/timestep, they can tweak their internal predictions so that the overall system simulation works correctly.
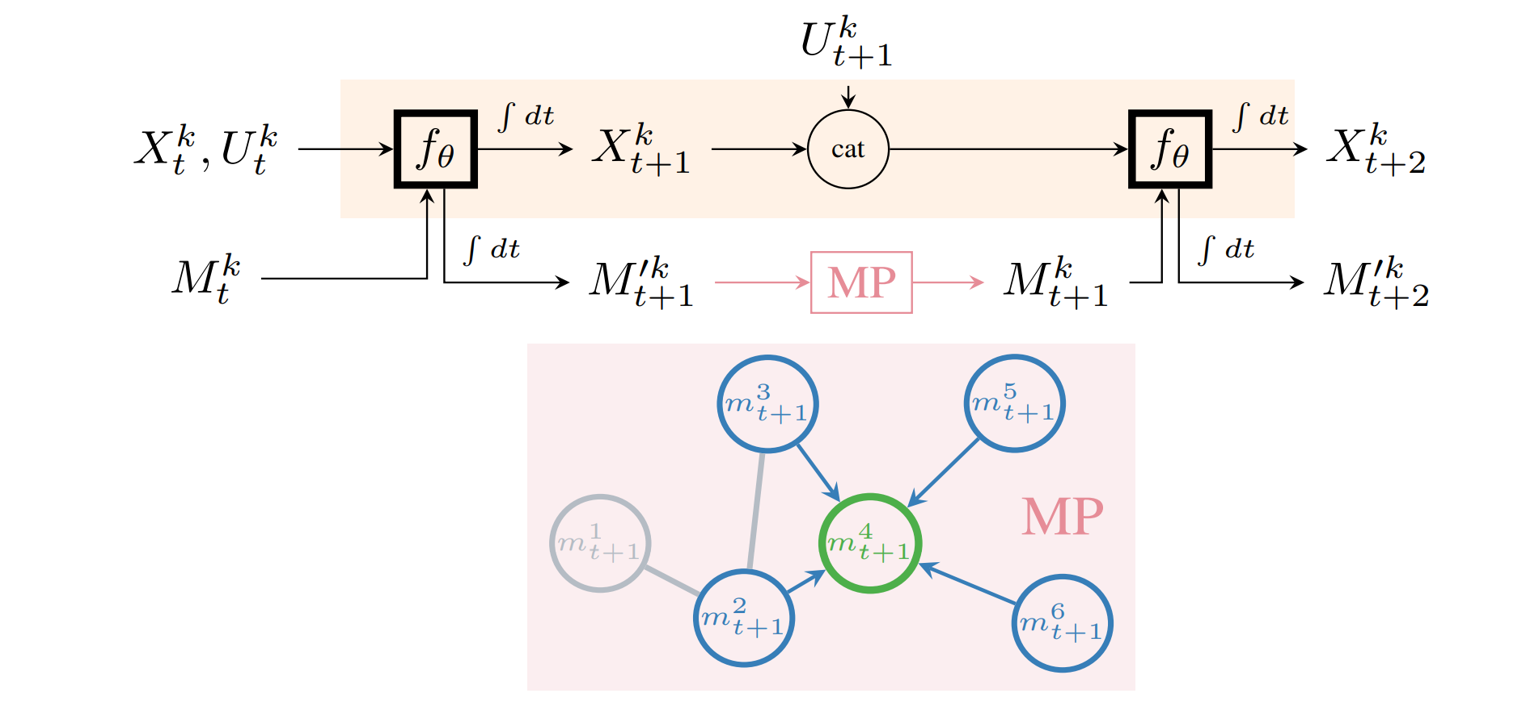
We apply our proposed method to several multi-node homogeneous systems. As a toy example, we investigate the case of a coupled pendulum where two simple pendula are attached by a string. We notice that the inclusion of messages helps with long horizon state predictions. Furthermore, we perform an experiment where we take a trained MP-NODE and use it for inference with both messages turned on and turned off. When the messages are disabled, each node in the system behaves similar to an unconnected pendulum. This shows that messages implicitly learn to encode relevant details about interaction.
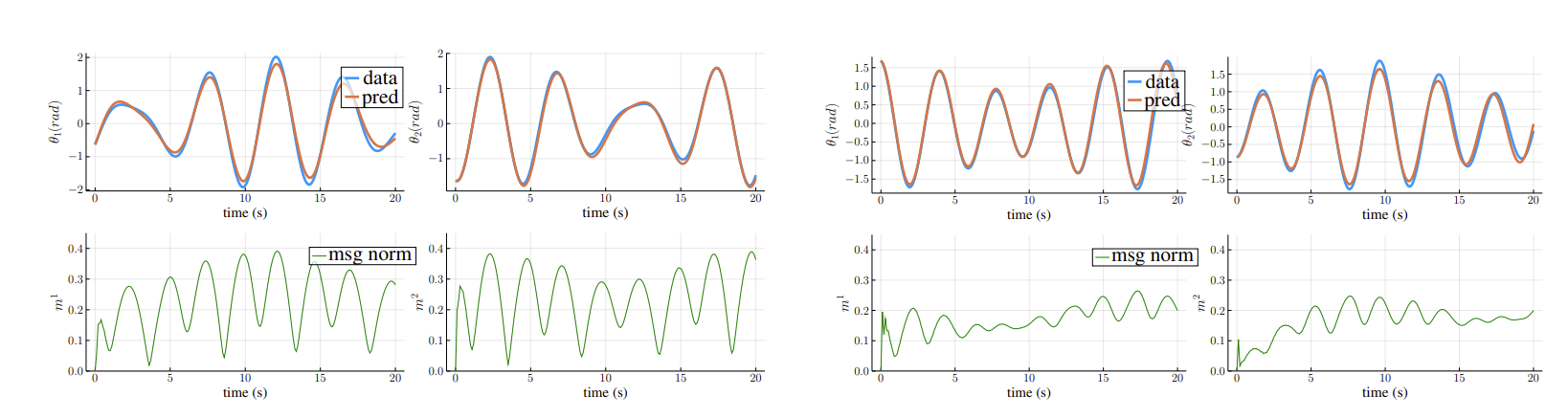
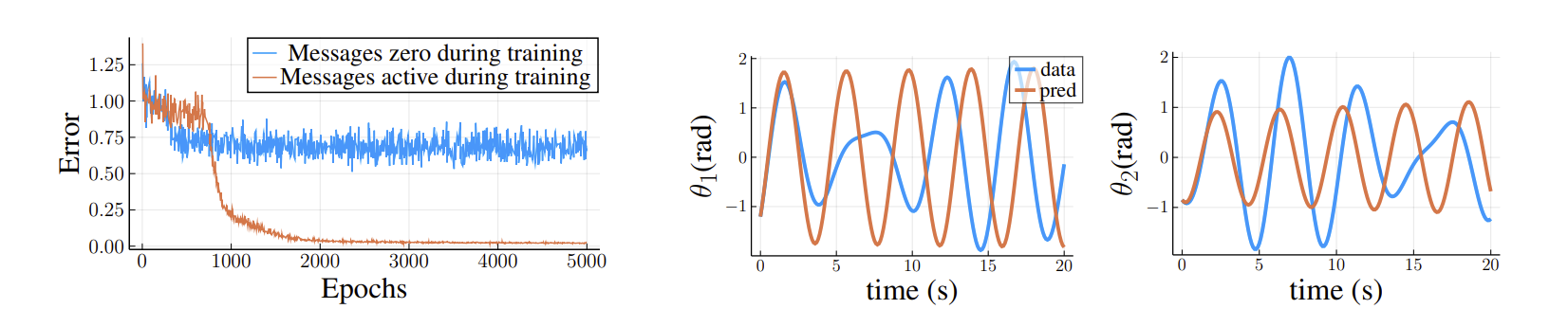
Left: The trend of errors during training shows that when messages are not used, the ability to model interactions is lost, resulting in bad predictions.
Right: When messages are deliberately turned off during inference, the simulation nodes evolve independently, i.e., similar to a single pendulum.
We also use MP-NODE to model several other systems of interest. These include
a) Coupled Lorenz attractors
b) Gene dynamics over a spatial grid modeled using the Michelis-Menten equation
c) Kuramoto system, a model for the behavior of a large set of coupled oscillators
d) A swarm of quadrotors performing cooperative assembly
Through these experiments, we validate two primary hypotheses.
The modular nature of the MP-NODE allows for easy transfer to different configurations of systems.
1) Higher number of nodes
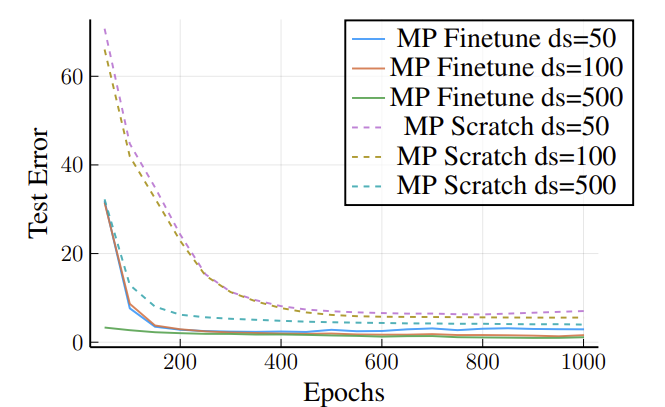
A common use case would be to take a trained MP-NODE module, representing a subsystem, and finetune it for a larger graph than what it was originally trained on. We use the MP-NODE that we trained on a three-node Lorenz attractor, and fine-tune this model for the 10-node configuration. We observe through the test error plot in Figure 5 (Left) that even in low-data regimes, fine-tuning a trained model is far more efficient than training a model from scratch, highlighting the transferability of MP-NODE.
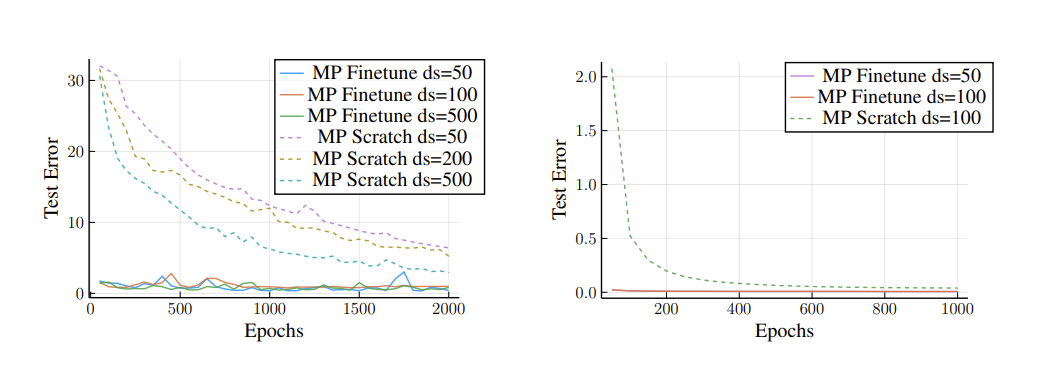
Left: Finetuning an MP-NODE trained on a 3-node Lorenz system for a 10-node Lorenz system.
Right: Finetuning an MO-NODE trained on a 4×4 gene dynamics grid for an 8×8 gene dynamics grid.
We perform a similar experiment on the gene dynamics system, where we first train an MP-NODE model on data from a 4×4 spatial grid, and finetune it for an 8×8 configuration. Similar to above, we see that finetuning a trained MP-NODE allows for accurate predictions faster than training from scratch.
2) New graph structure
We also examine the ability of MP-NODE to be finetuned for different graph structures. To this end, we train an MP-NODE on a Kuramoto10 system connected according to the Barabasi-Albert (BA) network and attempt to finetune it for systems of other network types. As above, we see that finetuning is more efficient at adapting to new network types than training models from scratch.
3) Different system parameters
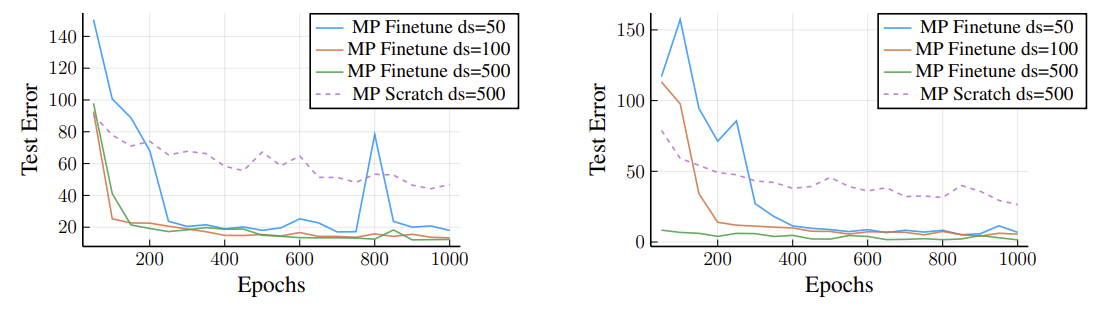
We also evaluate the possibility of finetuning MP-NODEs for different system parameters. As an example, we finetune a MP-NODE model trained on Lorenz3 to Lorenz10 but with different coupling intensity than the original training data and show the results in Figure 7 (left). Similarly, we also try to finetune the MP-NODE model trained on Lorenz3 to Lorenz10 for longer time horizon of 10s in Figure 7 (right). In both cases, we again find that a lot less data is required to achieve better performance than training from scratch.
The modular nature of MP-NODE allows for zero-shot transfer of trained modules to new configurations.
MP-NODE operates by training a model for the individual subsystem within a homogeneous network. This allows us to connect an arbitrary number of such trained subsystems together for a given graph structure. We investigate the performance of MP-NODE models on new configurations without explicitly finetuning the model.
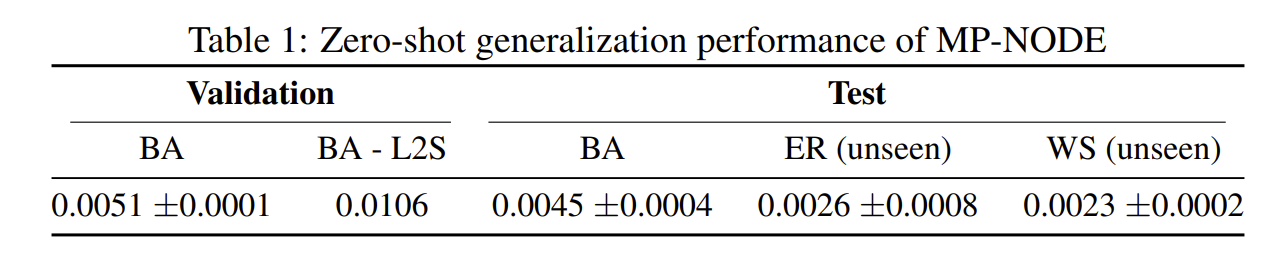
When tested on the Lorenz system, we find that an MP- NODE trained only on Lorenz3 exhibits reasonable zero-shot generalization performance on a higher number of Lorenz attractors, such as Lorenz7 and Lorenz10 without requiring any additional training.
We notice that this ability holds for not only changing numbers of nodes, but also different graph topologies. For the Gene 4×4 system, we generate data from multiple adjacency matrices but all according to the Barabasi-Albert (BA) network topology and train the MP-NODE on this dataset. We observe that this MP-NODE model trained only on BA topology generalizes to other unseen network topologies (Erdos-Renyi (ER), Watts-Strogatz (WS)) as well. We show these results in Table 1.

Left: MP-NODE trained on a 4×4 grid finetuned for an 8×8 grid
Right: MP-NODE trained on a 4×4 grid with one specific topology generalizing to a new topology
In our paper, we present more results that discuss the applications to Kuramoto systems and quadrotor swarms, along with ablation studies and comparisons to existing literature; showcasing the ability of MP-NODE to learn complex dynamics in a modular fashion while outperforming existing methods.
In summary, this modular way of thinking about data-driven simulation of complex systems has the potential to minimize data, compute, and energy requirements. We show through our analysis of finetuning and generalization that our approach of modeling subsystems that are inherently reusable as opposed to specific configurations of systems has the potential to alleviate data and compute requirements. For better ability to adapt to more complex systems, an extension that can handle heterogeneous systems is necessary, which we leave to future work. We are excited to build upon this paradigm of modular composable simulations for learning data-driven surrogates of real systems, helping speed up conventional slow simulations while also being capable of capturing complex real-world phenomena.
This work is being undertaken by a team at Microsoft Autonomous Systems and Robotics Research. The researchers included in this project are: Jayesh K. Gupta, Sai Vemprala, and Ashish Kapoor.