

作者:刘树杰
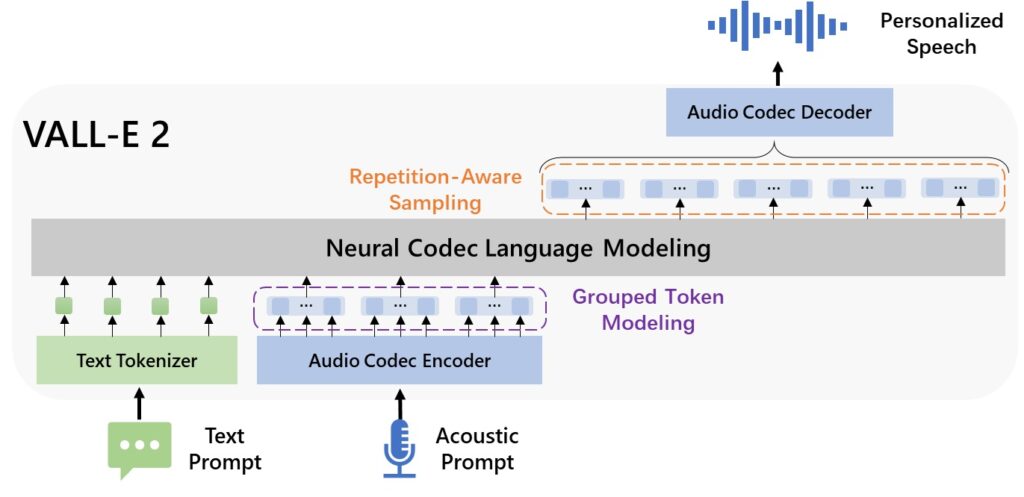
编者按:文本到语音合成(Text-to-Speech,TTS)是一种将书面文字转化为自然语音的技术,在提高无障碍性、增强跨语言交流等方面发挥着重要作用。微软亚洲研究院此前推出了第一个离散编码的语音大模型 VALL-E,并在此基础上通过重复感知采样和分组编码建模技术将其升级为 VALL-E 2 版本。新版本突破了语音稳健性、自然度和说话人相似度方面的界限,让零样本 TTS 性能在 LibriSpeech 和 VCTK 数据集上与人类水平相近。
近年来人工智能技术的飞速发展,不断推动着文本到语音合成(Text-to-Speech,TTS)技术的边界。TTS 技术的持续优化与创新,为人们提供了丰富、便捷的语音交互体验,相关的研究成果在教育、娱乐以及多语言交流等多个领域都有着广泛的应用前景。
传统的 TTS 系统仅仅使用来自录音室的高质量且干净的语音数据进行训练,导致其泛化能力较差。在零样本情境下,对于陌生的说话人,语音相似度和自然度也会显著下降。对此,微软亚洲研究院的研究员们尝试将 LLMs 技术引入语音处理任务,并构建了第一个使用离散编码的语音大模型 VALL-E。这些离散编码来自现成的神经音频编码模型,并将 TTS 视为条件语言模型任务,从而可以展现出强大的上下文学习能力。只需陌生的说话人提供一段3秒的录音作为提示,VALL-E 即可合成高质量的个性化语音。但由于自回归建模和随机采样推断,VALL-E 在鲁棒性和效率方面仍有待提升。
在此基础上,研究员们设计了 VALL-E 2,其利用重复感知采样(repetition aware sampling)和分组编码建模技术,实现了零样本 TTS 的性能在 LibriSpeech 和 VCTK 数据集上可达到与人类水平相媲美的程度。其中,重复感知采样通过考虑解码历史中的标记重复,改进了原始的核(Nucleus)采样过程。它不仅能稳定解码,还能避免在 VALL-E 中遇到的无限循环问题。分组编码建模则将编解码器编码组织成组,有效缩短了序列长度,在提高推理速度的同时,也解决了长序列建模的难题。
通过这两项技术,VALL-E 2 在语音的稳健性、自然度和说话人相似度方面显著超过了以往的系统。即使是在较大复杂性或重复短语这些具有挑战性的句子上,VALL-E 2 也能一致地合成高质量语音。
VALL-E 2 论文:https://arxiv.org/abs/2406.05370 (opens in new tab)
VALL-E 2 演示页面:https://aka.ms/valle2 (opens in new tab)
重复感知采样和分组编码建模,实现模型升级
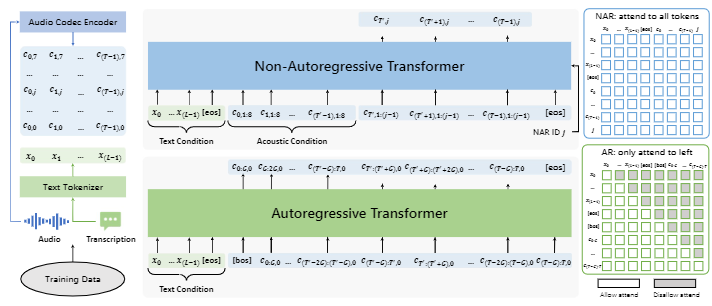
VALL-E 2 采用了同 VALL-E 类似的层次结构:一个自回归(AR)编码语言模型和一个非自回归(NAR)编码语言模型。AR 模型以自回归方式生成每帧的第一个编码序列,而 NAR 模型则基于之前的编码序列以非自回归方式生成每个剩余的编码序列。两个模型都使用相同的 Transformer 架构,包含一个文本嵌入层、一个编码嵌入层、Transformer 层和一个编码预测层。但 AR 模型和 NAR 模型有不同的注意力掩码策略:AR 模型使用因果注意力策略,而 NAR 模型使用全注意力策略。
基于过往经验,研究员们发现 VALL-E 在推理中使用的随机采样可能会导致输出不稳定。尽管错误编码(图3中的红色方块)的概率很低,但由于采样步骤太多,它们仍然不可避免地会被采样到。为了稳定推理过程,通常会利用 Nucleus 采样来从累积概率低于预设阈值的最可能标记集合中进行采样。Nucleus 采样方法可以减少说错词的错误,但也可能导致模型为了减少错误而只生成静音。
因此,为了平衡随机采样和 Nucleus 采样,研究员们提出了重复感知采样的方法。在给定 AR 模型预测的概率分布基础上,研究员们首先使用预定义的 top-p 值通过 Nucleus 采样生成目标编码。然后使用固定的窗口大小来计算预测编码在前面的编码序列中的重复比例。如果重复比例超过预定义的重复阈值,研究员们就会使用随机采样从原始概率分布中获得新的预测结果来替换原来的目标编码。通过这种重复感知采样的方法,解码过程既可以受益于 Nucleus 采样的稳定性,还可以借助随机采样避免陷入静音的无限循环。
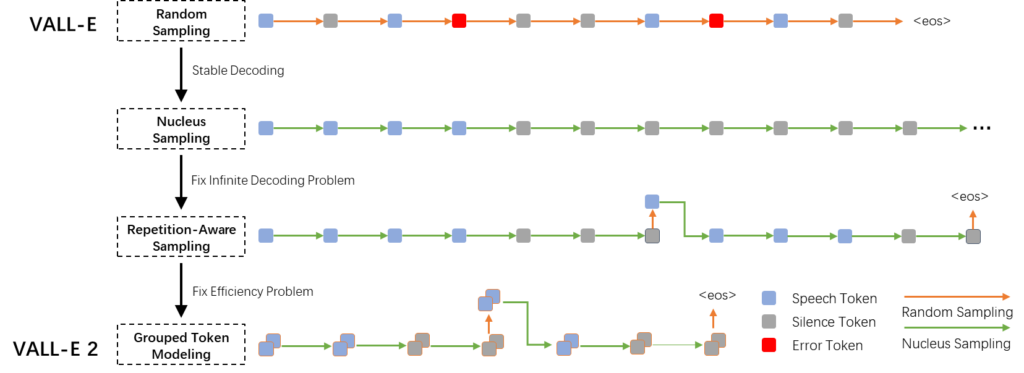
同时,研究员们发现,VALL-E 的自回归架构受限于现成音频编码模型的高帧率,从而导致推理速度缓慢,特别是在自回归模型的推理过程中尤为显著。为了加速推理过程,研究员们在 VALL-E 2 中采用了分组编码建模方法,将编码序列划分为一定大小的分组,并将每组编码建模为一步。在自回归模型中,研究员们利用分组嵌入层将编码嵌入结果映射到分组嵌入并作为网络的输入,并在输出层使用分组预测层对一组中的编码进行预测。通过这种方式,现有神经音频编码模型的帧率限制得以摆脱,帧率成倍数地降低得到实现。这不仅有利于推理效率的提高,还可以缓解长上下文建模的问题并提升整体语音质量。
稳健性、自然度和相似度的大幅提升
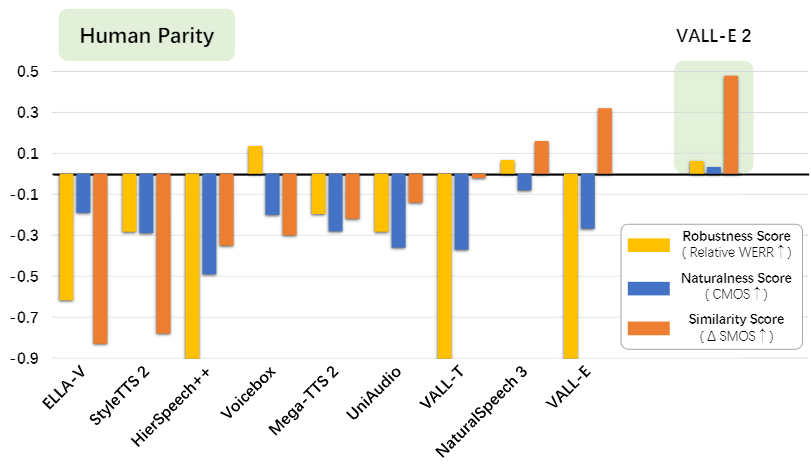
为了展示 VALL-E 2 的性能,研究员们在 LibriSpeech 和 VCTK 数据集上进行了实验,并在稳健性、自然度和音色相似度评分方面与多个基线模型进行了比较。这些评分是根据原始论文中报告的结果计算得到的相对数值,不考虑模型架构和训练数据的差异。
从图4中可以看到,VALL-E 2 相比以前的方法显著提升了各个指标的性能,并且首次实现了与人类同等水平相近的零样本 TTS。与人类水平相近指的是 VALL-E 2 的稳健性、自然度和相似度指标超越了真实样本,即 WER(GroundTruth)-WER(VALL-E 2)>0,CMOS(VALL-E 2)-CMOS(GroundTruth)>0 和 SMOS(VALL-E 2)-SMOS(GroundTruth)>0,这意味着 VALL-E 2 能够生成与原始说话人声音较为一致的准确自然的语音。但需要注意,这一结论仅仅基于 LibriSpeech 和 VCTK 数据集的实验结果。
重复感知采样和分组编码建模两种方法的引入,使得 VALL-E 2 能够可靠地合成复杂句子的语音,包括那些难以阅读或包含大量重复短语的句子。VALL-E 2 的技术优势,可以为人工智能向善的场景做出贡献,例如为失语症患者或肌萎缩侧索硬化症的患者生成语音等。
注:VALL-E 2 是一个纯粹的研究项目,目前没有计划纳入产品或向公众开放。VALL-E 2 可以合成保持说话者音色的语音,可用于教育学习、娱乐、新闻、自创内容、无障碍功能、互动语音应答系统、翻译、聊天机器人等。虽然 VALL-E 2 可以生成媲美真人声音的语音,但其相似度和自然度仍取决于语音提示的长度和质量、背景噪音以及其他因素。该模型可能在误用方面存在潜在风险,例如伪造语音识别或冒充特定说话者。在语音合成研究中,我们已经获得用户的授权,将其作为实验的目标说话者,如果该模型需要推广到现实世界中的未见过的说话者,应确保说话者同意使用其声音的协议和合成语音检测模型。如果您发现 VALL-E 2 被滥用、非法使用或侵犯了您的权利或他人的权利,可以在微软的滥用报告门户网站(https://msrc.microsoft.com/report/)进行举报。
随着人工智能技术的快速发展,确保相关技术能被人们信赖是一个需要攻坚的问题。微软主动采取了一系列措施来预判和降低人工智能技术所带来的风险。微软致力于依照以人为本的伦理原则推进人工智能的发展,早在2018年就发布了“公平、包容、可靠与安全、透明、隐私与保障、负责”六个负责任的人工智能原则(Responsible AI Principles),随后又发布了负责任的人工智能标准(Responsible AI Standards)将各项原则实施落地,并设置了治理架构确保各团队把各项原则和标准落实到日常工作中。微软也持续与全球的研究人员和学术机构合作,不断推进负责任的人工智能的实践和技术。