Editor’s note: All papers referenced here represent collaborations throughout Microsoft and across academia and industry that include authors who contribute to Aether, the Microsoft internal advisory body for AI Ethics and Effects in Engineering and Research.

-
 Video
A human-centered approach to AI
Video
A human-centered approach to AI
Learn how considering potential benefits and harms to people and society helps create better AI in the keynote “Challenges and opportunities in responsible AI” (2022 ACM SIGIR Conference on Human Information Interaction and Retrieval).
Artificial intelligence, like all tools we build, is an expression of human creativity. As with all creative expression, AI manifests the perspectives and values of its creators. A stance that encourages reflexivity among AI practitioners is a step toward ensuring that AI systems are human-centered, developed and deployed with the interests and well-being of individuals and society front and center. This is the focus of research scientists and engineers affiliated with Aether, the advisory body for Microsoft leadership on AI ethics and effects. Central to Aether’s work is the question of who we’re creating AI for—and whether we’re creating AI to solve real problems with responsible solutions. With AI capabilities accelerating, our researchers work to understand the sociotechnical implications and find ways to help on-the-ground practitioners envision and realize these capabilities in line with Microsoft AI principles.
The following is a glimpse into the past year’s research for advancing responsible AI with authors from Aether. Throughout this work are repeated calls for reflexivity in AI practitioners’ processes—that is, self-reflection to help us achieve clarity about who we’re developing AI systems for, who benefits, and who may potentially be harmed—and for tools that help practitioners with the hard work of uncovering assumptions that may hinder the potential of human-centered AI. The research discussed here also explores critical components of responsible AI, such as being transparent about technology limitations, honoring the values of the people using the technology, enabling human agency for optimal human-AI teamwork, improving effective interaction with AI, and developing appropriate evaluation and risk-mitigation techniques for multimodal machine learning (ML) models.
Considering who AI systems are for
The need to cultivate broader perspectives and, for society’s benefit, reflect on why and for whom we’re creating AI is not only the responsibility of AI development teams but also of the AI research community. In the paper “REAL ML: Recognizing, Exploring, and Articulating Limitations of Machine Learning Research (opens in new tab),” the authors point out that machine learning publishing often exhibits a bias toward emphasizing exciting progress, which tends to propagate misleading expectations about AI. They urge reflexivity on the limitations of ML research to promote transparency about findings’ generalizability and potential impact on society—ultimately, an exercise in reflecting on who we’re creating AI for. The paper offers a set of guided activities designed to help articulate research limitations (opens in new tab), encouraging the machine learning research community toward a standard practice of transparency about the scope and impact of their work.

Walk through REAL ML’s instructional guide and worksheet that help researchers with defining the limitations of their research and identifying societal implications these limitations may have in the practical use of their work.
Despite many organizations formulating principles to guide the responsible development and deployment of AI, a recent survey highlights that there’s a gap between the values prioritized by AI practitioners and those of the general public. The survey, which included a representative sample of the US population, found AI practitioners often gave less weight than the general public to values associated with responsible AI. This raises the question of whose values should inform AI systems and shifts attention toward considering the values of the people we’re designing for, aiming for AI systems that are better aligned with people’s needs.
Related papers
- REAL ML: Recognizing, Exploring, and Articulating Limitations of Machine Learning Research
- How Different Groups Prioritize Ethical Values for Responsible AI
Creating AI that empowers human agency
Supporting human agency and emphasizing transparency in AI systems are proven approaches to building appropriate trust with the people systems are designed to help. In human-AI teamwork, interactive visualization tools can enable people to capitalize on their own domain expertise and let them easily edit state-of-the-art models. For example, physicians using GAM Changer can edit risk prediction models for pneumonia and sepsis to incorporate their own clinical knowledge and make better treatment decisions for patients.
A study examining how AI can improve the value of rapidly growing citizen-science contributions found that emphasizing human agency and transparency increased productivity in an online workflow where volunteers provide valuable information to help AI classify galaxies. When choosing to opt in to using the new workflow and receiving messages that stressed human assistance was necessary for difficult classification tasks, participants were more productive without sacrificing the quality of their input and they returned to volunteer more often.
Failures are inevitable in AI because no model that interacts with the ever-changing physical world can be complete. Human input and feedback are essential to reducing risks. Investigating reliability and safety mitigations for systems such as robotic box pushing and autonomous driving, researchers formalize the problem of negative side effects (NSEs), the undesirable behavior of these systems. The researchers experimented with a framework in which the AI system uses immediate human assistance in the form of feedback—either about the user’s tolerance for an NSE occurrence or their decision to modify the environment. Results demonstrate that AI systems can adapt to successfully mitigate NSEs from feedback, but among future considerations, there remains the challenge of developing techniques for collecting accurate feedback from individuals using the system.
The goal of optimizing human-AI complementarity highlights the importance of engaging human agency. In a large-scale study examining how bias in models influences humans’ decisions in a job recruiting task, researchers made a surprising discovery: when working with a black-box deep neural network (DNN) recommender system, people made significantly fewer gender-biased decisions than when working with a bag-of-words (BOW) model, which is perceived as more interpretable. This suggests that people tend to reflect and rely on their own judgment before accepting a recommendation from a system for which they can’t comfortably form a mental model of how its outputs are derived. Researchers call for exploring techniques to better engage human reflexivity when working with advanced algorithms, which can be a means for improving hybrid human-AI decision-making and mitigating bias.
How we design human-AI interaction is key to complementarity and empowering human agency. We need to carefully plan how people will interact with AI systems that are stochastic in nature and present inherently different challenges than deterministic systems. Designing and testing human interaction with AI systems as early as possible in the development process, even before teams invest in engineering, can help avoid costly failures and redesign. Toward this goal, researchers propose early testing of human-AI interaction through factorial surveys, a method from the social sciences that uses short narratives for deriving insights about people’s perceptions.
But testing for optimal user experience before teams invest in engineering can be challenging for AI-based features that change over time. The ongoing nature of a person adapting to a constantly updating AI feature makes it difficult to observe user behavior patterns that can inform design improvements before deploying a system. However, experiments demonstrate the potential of HINT (Human-AI INtegration Testing), a framework for uncovering over-time patterns in user behavior during pre-deployment testing. Using HINT, practitioners can design test setup, collect data via a crowdsourced workflow, and generate reports of user-centered and offline metrics.

Check out the 2022 anthology of this annual workshop that brings human-computer interaction (HCI) and natural language processing (NLP) research together for improving how people can benefit from NLP apps they use daily.
Related papers
- Assessing Human-AI Interaction Early through Factorial Surveys: A Study on the Guidelines for Human-AI Interaction
- Avoiding Negative Side Effects of Autonomous Systems in the Open World
- Interpretability, Then What? Editing Machine Learning Models to Reflect Human Knowledge and Values
- Investigations of Performance and Bias in Human-AI Teamwork in Hiring
- A new Workflow for Human-AI Collaboration in Citizen Science
- HINT: Integration Testing for AI-based Features with Humans in the Loop
Building responsible AI tools for foundation models
Although we’re still in the early stages of understanding how to responsibly harness the potential of large language and multimodal models that can be used as foundations for building a variety of AI-based systems, researchers are developing promising tools and evaluation techniques to help on-the-ground practitioners deliver responsible AI. The reflexivity and resources required for deploying these new capabilities with a human-centered approach are fundamentally compatible with business goals of robust services and products.
Natural language generation with open-ended vocabulary has sparked a lot of imagination in product teams. Challenges persist, however, including for improving toxic language detection; content moderation tools often over-flag content that mentions minority groups without respect to context while missing implicit toxicity. To help address this, a new large-scale machine-generated dataset, ToxiGen, enables practitioners to fine-tune pretrained hate classifiers for improving detection of implicit toxicity for 13 minority groups in both human- and machine-generated text.

Download the large-scale machine-generated ToxiGen dataset and install source code for fine-tuning toxic language detection systems for adversarial and implicit hate speech for 13 demographic minority groups. Intended for research purposes.
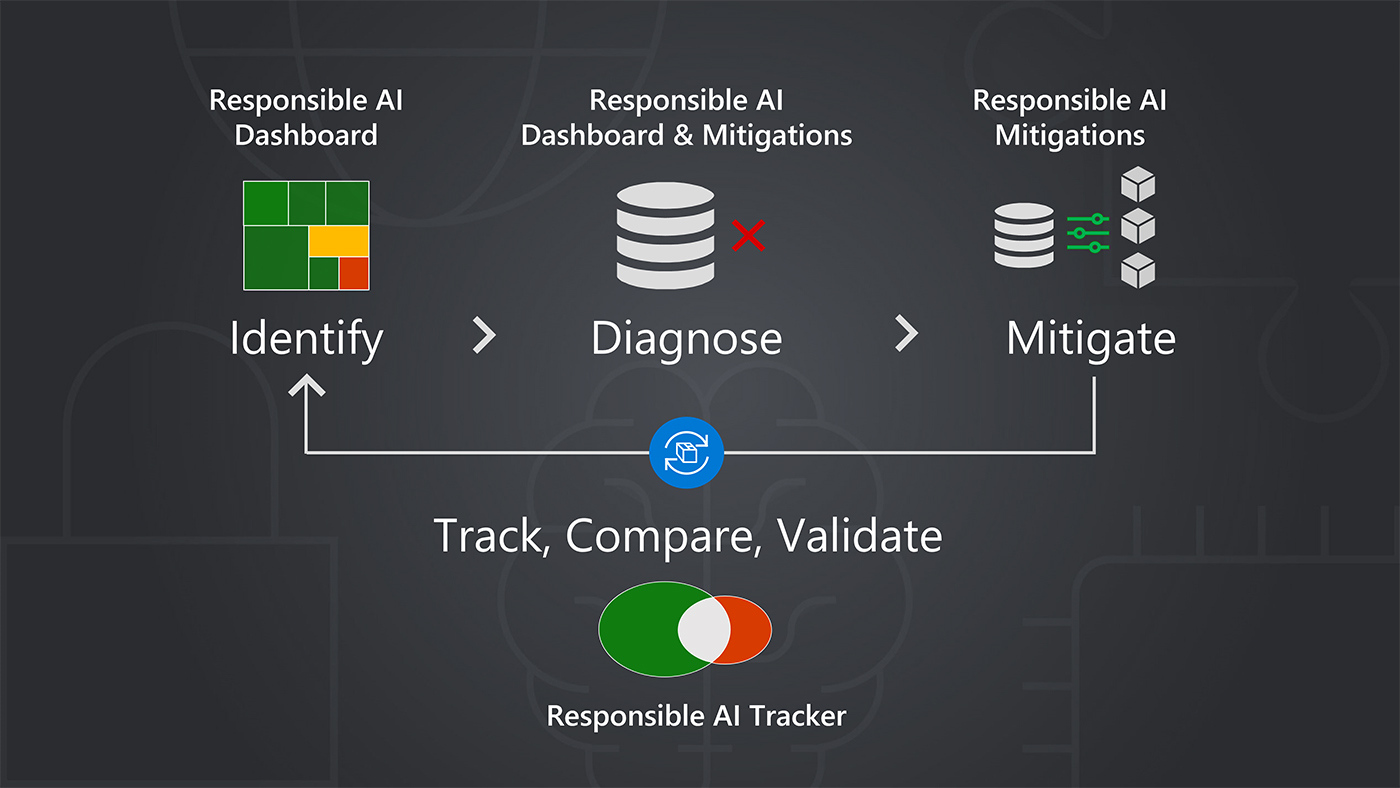
Multimodal models are proliferating, such as those that combine natural language generation with computer vision for services like image captioning. These complex systems can surface harmful societal biases in their output and are challenging to evaluate for mitigating harms. Using a state-of-the-art image captioning service with two popular image-captioning datasets, researchers isolate where in the system fairness-related harms originate and present multiple measurement techniques for five specific types of representational harm: denying people the opportunity to self-identify, reifying social groups, stereotyping, erasing, and demeaning.
The commercial advent of AI-powered code generators has introduced novice developers alongside professionals to large language model (LLM)-assisted programming. An overview of the LLM-assisted programming experience reveals unique considerations. Programming with LLMs invites comparison to related ways of programming, such as search, compilation, and pair programming. While there are indeed similarities, the empirical reports suggest it is a distinct way of programming with its own unique blend of behaviors. For example, additional effort is required to craft prompts that generate the desired code, and programmers must check the suggested code for correctness, reliability, safety, and security. Still, a user study examining what programmers value in AI code generation shows that programmers do find value in suggested code because it’s easy to edit, increasing productivity. Researchers propose a hybrid metric that combines functional correctness and similarity-based metrics to best capture what programmers value in LLM-assisted programming, because human judgment should determine how a technology can best serve us.
Related papers
- What is it like to program with artificial intelligence?
- ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection
- Aligning Offline Metrics and Human Judgments of Value of AI-Pair Programmers
- Measuring Representational Harms in Image Captioning
Understanding and supporting AI practitioners
Organizational culture and business goals can often be at odds with what practitioners need for mitigating fairness and other responsible AI issues when their systems are deployed at scale. Responsible, human-centered AI requires a thoughtful approach: just because a technology is technically feasible does not mean it should be created.
Similarly, just because a dataset is available doesn’t mean it’s appropriate to use. Knowing why and how a dataset was created is crucial for helping AI practitioners decide on whether it should be used for their purposes and what its implications are for fairness, reliability, safety, and privacy. A study focusing on how AI practitioners approach datasets and documentation reveals current practices are informal and inconsistent. It points to the need for data documentation frameworks designed to fit within practitioners’ existing workflows and that make clear the responsible AI implications of using a dataset. Based on these findings, researchers iterated on Datasheets for Datasets and proposed the revised Aether Data Documentation Template.

Use this flexible template to reflect and help document underlying assumptions, potential risks, and implications of using your dataset.
AI practitioners find themselves balancing the pressures of delivering to meet business goals and the time requirements necessary for the responsible development and evaluation of AI systems. Examining these tensions across three technology companies, researchers conducted interviews and workshops to learn what practitioners need for measuring and mitigating AI fairness issues amid time pressure to release AI-infused products to wider geographic markets and for more diverse groups of people. Participants disclosed challenges in collecting appropriate datasets and finding the right metrics for evaluating how fairly their system will perform when they can’t identify direct stakeholders and demographic groups who will be affected by the AI system in rapidly broadening markets. For example, hate speech detection may not be adequate across cultures or languages. A look at what goes into AI practitioners’ decisions around what, when, and how to evaluate AI systems that use natural language generation (NLG) further emphasizes that when practitioners don’t have clarity about deployment settings, they’re limited in projecting failures that could cause individual or societal harm. Beyond concerns for detecting toxic speech, other issues of fairness and inclusiveness—for example, erasure of minority groups’ distinctive linguistic expression—are rarely a consideration in practitioners’ evaluations.
Coping with time constraints and competing business objectives is a reality for teams deploying AI systems. There are many opportunities for developing integrated tools that can prompt AI practitioners to think through potential risks and mitigations for sociotechnical systems.
Related papers
- Deconstructing NLG Evaluation: Evaluation Practices, Assumptions, and Their Implications
- Understanding Machine Learning Practitioners’ Data Documentation Perceptions, Needs, Challenges, and Desiderata
- Assessing the Fairness of AI Systems: AI Practitioners’ Processes, Challenges, and Needs for Support
Thinking about it: Reflexivity as an essential for society and industry goals
As we continue to envision what all is possible with AI’s potential, one thing is clear: developing AI designed with the needs of people in mind requires reflexivity. We have been thinking about human-centered AI as being focused on users and stakeholders. Understanding who we are designing for, empowering human agency, improving human-AI interaction, and developing harm mitigation tools and techniques are as important as ever. But we also need to turn a mirror toward ourselves as AI creators. What values and assumptions do we bring to the table? Whose values get to be included and whose are left out? How do these values and assumptions influence what we build, how we build, and for whom? How can we navigate complex and demanding organizational pressures as we endeavor to create responsible AI? With technologies as powerful as AI, we can’t afford to be focused solely on progress for its own sake. While we work to evolve AI technologies at a fast pace, we need to pause and reflect on what it is that we are advancing—and for whom.