Editor’s note: All papers referenced here represent collaborations throughout Microsoft and across academia and industry that include authors who contribute to Aether, the Microsoft internal advisory body for AI ethics and effects in engineering and research.

A surge of generative AI models in the past year has fueled much discussion about the impact of artificial intelligence on human history. Advances in AI have indeed challenged thinking across industries, from considering how people will function in creative roles to effects in education, medicine, manufacturing, and more. Whether exploring impressive new capabilities of large language models (LLMs) such as GPT-4 or examining the spectrum of machine learning techniques already embedded in our daily lives, researchers agree on the importance of transparency. For society to appropriately benefit from this powerful technology, people must be given the means for understanding model behavior.
Transparency is a foundational principle of responsible, human-centered AI and is the bedrock of accountability. AI systems have a wide range of stakeholders: AI practitioners need transparency for evaluating data and model architecture so they can identify, measure, and mitigate potential failures; people using AI, expert and novice, must be able to understand the capabilities and limitations of AI systems; people affected by AI-assisted decision-making should have insights for redress when necessary; and indirect stakeholders, such as residents of cities using smart technologies, need clarity about how AI deployment may affect them.
Providing transparency when working with staggeringly complex and often proprietary models must take different forms to meet the needs of people who work with either the model or the user interface. This article profiles a selection of recent efforts for advancing transparency and responsible AI (RAI) by researchers and engineers affiliated with Aether, the Microsoft advisory body for AI ethics and effects in engineering and research. This work includes investigating LLM capabilities and exploring strategies for unlocking specialized-domain competencies of these powerful models while urging transparency approaches for both AI system developers and the people using these systems. Researchers are also working toward improving identification, measurement, and mitigation of AI harms while sharing practical guidance such as for red teaming LLM applications and for privacy-preserving computation. The goal of these efforts is to move from empirical findings to advancing the practice of responsible AI.

Toward user-centered algorithmic recourse
In this demo of GAM Coach, an example of an AI transparency approach, an interactive interface lets stakeholders in a loan allocation scenario understand how a model based its prediction and what factors they can change to meet their goals.
Related papers
- GAM Coach: Towards Interactive and User-centered Algorithmic Recourse
- Understanding People’s Concerns and Attitudes Toward Smart Cities
- Sparks of Artificial General Intelligence: Early experiments with GPT-4
- Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
- AI Transparency in the Age of LLMs: A Human-Centered Research Roadmap
- UN Handbook on Privacy-Preserving Computation Techniques
Identifying harms in LLMs and their applications
The sociotechnical nature of AI is readily apparent as product teams sprint to integrate the power and appeal of LLMs into conversational agents and productivity tools across domains. At the same time, recent accounts, such as a lawyer unwittingly submitting generative AI’s fictitious legal citations in a brief to the court (opens in new tab) or unsettling demonstrations of deepfakes, reveal the ample opportunity for misunderstanding these models’ capabilities and, worse yet, for deliberately misusing them.
Envisioning what could go wrong with an AI system that has not yet been deployed is the first step toward responsible AI. Addressing this challenge, researchers introduce AHA! (anticipating harms of AI), a human-AI collaboration for systematic impact assessment. This framework enables people to make judgments about the impact of potential deployment on stakeholders. It uses an LLM to generate vignettes, or fictional scenarios, that account for an ethical matrix of problematic AI behaviors or harms. Evaluation of this framework in a variety of decision-making contexts found it surfaced a broader range of potential harmful outcomes than either people or LLMs could singly envision.

AI practitioners can follow this planning guide to help them set up and manage red teaming for large language models (LLMs) and their applications. Based on firsthand experience of testing LLMs to identify potentially harmful outputs and plan for mitigation strategies, this guide provides tips for who should test, what to test, and how to test, plus pointers for recording the red-teaming data.
Responsible AI red teaming, or probing models and their applications to identify undesirable behaviors, is another method of harm identification. Microsoft has shared a practical guide for the RAI red teaming of LLMs and their applications, and automated tools for RAI red teaming are beginning to emerge. Although the vital task of impact assessment and testing for failures can be facilitated by LLMs helping with creative brainstorming, researchers emphasize that for AI to be human centered, such efforts should never be fully automated. To improve human-AI complementarity in red teaming, AdaTest++ builds on an existing tool that uses an LLM to generate test suggestions as it adapts to user feedback. The redesign offers greater human control for testing hypotheses, enabling editing and exploration of counterfactuals, and conducting in-depth testing across a broad diversity of topics.

In AI privacy, researchers demonstrate how prompt-tuning can be used to infer private information from an email system using a language model to provide autocompleted replies. In sharing their red-teaming technique, they encourage privacy-enhancing efforts for applications using language models and take the stance that transparency of publicly detailing a model’s vulnerability is an essential step toward adversarial robustness.
Identifying and exposing security vulnerabilities is a top concern, especially when these can seep into AI-generated code. The integration of LLMs for AI-assisted coding has reduced the entry barrier for novice programmers and increased productivity for veteran coders. But it is important to examine the reliability and safety of AI-assisted coding. Although static analysis tools can detect and remove insecure code suggestions caused by the adversarial manipulation of training data, researchers introduce two novel techniques for poisoning code-suggestion models that bypass static analysis mitigation: Covert inserts malicious code in docstrings and comments, while TrojanPuzzle tricks the transformer-based model into substituting tokens, giving the programmer harmless-looking but insecure code. Exposing these vulnerabilities, researchers call for new methods for training code-suggestion models and for processes to ensure code suggestions are secure before programmers ever see them.
Related papers
- AHA! Facilitating AI Impact Assessment by Generating Examples of Harms
- Supporting Human-AI Collaboration in Auditing LLMs with LLMs
- Does Prompt-Tuning Language Model Ensure Privacy?
- TROJANPUZZLE: Covertly Poisoning Code-Suggestion Models
- Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions
Transparency for improving measurement and its validity
We can’t begin to mitigate for the possibility of AI failures without first identifying and then measuring the potential harms of a model’s outputs, transparently examining who may or may not benefit or what could go wrong and to what extent.
A framework for automating the measurement of harms at speed and scale has two LLMs simulate product- or end-user interaction and evaluate outputs for potential harms, using resources created by relevant sociotechnical-domain experts. As researchers stress, the validity and reliability of such evaluation rely strictly on the quality of these resources—the templates and parameters for simulating interactions, the definition of harms, and their annotation guidelines. In other words, sociotechnical-domain expertise is indispensable.
Measurement validity—ensuring metrics align with measurement goals—is central to the practice of responsible AI. Model accuracy in and of itself is not an adequate metric for assessing sociotechnical systems: for example, in the context of productivity applications, capturing what is valuable to an individual using an AI system should also be taken into account. How do we identify metrics appropriate for context-dependent models that are deployed across domains to serve a variety of populations and purposes? Teams need methods to address measurement and mitigation for every deployment scenario.
Language models illustrate the maxim “context is everything.” When it comes to measuring and mitigating fairness-related harms that are context-dependent in AI-generated text, there’s generally not enough granularity in dataset labeling. Lumping harms under generalized labels like “toxic” or “hate speech” doesn’t capture the detail needed for measuring and mitigating harms specific to various populations. FairPrism is a new dataset for detecting gender- and sexuality-related harms that makes a case for greater granularity in human annotation and transparency in dataset documentation, including identifying groups of people that may be targeted. Researchers situate FairPrism as “a recipe” for creating better-detailed datasets for measuring and mitigating AI harms and demonstrate how the new dataset’s 5,000 examples of English text can probe for fairness-related harms to a specific group.

Similarly, researchers deepen the conversation around representational harms in automated image-tagging systems, voicing the need for improved transparency and specificity in taxonomies of harms for more precision in measurement and mitigation. Image tagging is generally intended for human consumption, as in alt text or online image search, differentiating it from object recognition. Image tagging can impute fairness-related harms of reifying social groups as well as stereotyping, demeaning, or erasure. Researchers identify these four specific representational harms and map them to computational measurement approaches in image tagging. They call out the benefits of increased granularity but note there is no silver bullet: efforts to mitigate by adding or removing particular tags to avoid harms may in fact introduce or exacerbate these representational harms.
Related papers
- A Framework for Automated Measurement of Responsible AI Harms in Generative AI Applications
- Aligning Offline Metrics and Human Judgments of Value for Code Generation Models
- FairPrism: Evaluating Fairness-Related Harms in Text Generation
- Taxonomizing and Measuring Representational Harms: A Look at Image Tagging
Transparency and UX-based mitigations: What designers need and end users want
Prioritizing what people value and designing for the optimal user experience (UX) is a goal of human-centered, responsible AI. Unfortunately, UX design has often been viewed as a secondary consideration in engineering organizations. But because AI is a sociotechnical discipline, where technical solutions must converge with societal perspectives and social science theory, AI not only brings UX expertise to the foreground but also positions designers as potential innovators, well situated to mitigate some harms and model failures with UX interventions. To realize this, UX designers need transparency—visibility into how models work—so they can form “designerly understanding of AI” to help them ideate effectively. A study of 23 UX designers completing a hands-on design task illustrates their need for better support, including model documentation that’s easier to understand and interactive tools to help them anticipate model failures, envision mitigations, and explore new uses of AI.
People with varying levels of AI experience or subject-matter expertise are suddenly harnessing commercially available generative AI copilots for productivity gains and decision-making support across domains. But generative AI can make mistakes, and the impact of these failures can differ greatly depending on the use case: for example, poor performance in a creative-writing task has a very different impact than an error in a health care recommendation. As the stakes rise, so does the call for mitigating these failures: people need tools and mechanisms that help them audit AI outputs. UX interventions are well suited for mitigating this type of harm. To begin, researchers propose a taxonomy of needs that co-auditing systems should address when helping people double-check generative AI model responses. Basic considerations should include how easy it is for individuals to detect an error, what their skill level is, and how costly or consequential an error may be in a given scenario. A prototype Excel add-in illustrates these considerations, helping the nonprogrammer inspect the accuracy of LLM-generated code.
There are productivity dividends to paying attention to people’s need and desire for transparency. A central problem people encounter with language models is crafting prompts that lead to useful output. Advancing a solution for this in LLM-based code generation, researchers demonstrate an interface that gives people visibility into how the model maps their natural language query to system action. This transparency approach helps people adapt their mental model of the code generator’s capabilities and modify their queries accordingly. Findings of the user study, which included participants with low expertise in coding, showed this transparency approach promoted user confidence and trust while facilitating explanation and debugging. Similarly, human-centered efforts such as modeling the timing of when a programmer finds it most valuable to receive a code suggestion emphasize the primacy of end users’ needs when addressing productivity.
“What It Wants Me To Say”
This transparency approach provides nonexpert programmers with an interface that gives visibility into how a language model maps their natural language query to system action, helping them adapt their mental model and modify their prompts.
For experienced coders to be confident and benefit from AI-assisted code completion, they need to be able to easily spot and correct errors and security vulnerabilities. In the first empirical study of the effectiveness of token highlighting for communicating uncertainty of an AI prediction, researchers examine a UX technique that draws programmers’ attention in a way similar to a spell checker. Highlighting tokens that had the highest predicted likelihood of being edited resulted in programmers being able to complete tasks faster with better-targeted edits. Participants also desired more transparency in the form of explanations to help with diagnosing uncertainty and suggested interaction designs that would improve their efficiency and give them control.
Communicating the uncertainty of AI predictions in a way that is meaningful is a design challenge in every deployment context. How to provide transparency via explanations remains a conundrum—studies have shown that the mere presence of explanations can increase overreliance on AI. Designing UX that helps people meet their decision-making goals with confidence requires understanding their perceptions of how a given system works. But little is actually known about the processes decision-makers go through when debating whether to rely on an AI system’s output versus their own intuition. Conducting a think-aloud study for insights into the role of human intuition in reliance on AI predictions in AI-assisted decision making, researchers identified three types of intuition people use in deciding to override the system. While performing brief tasks of income prediction and biography classification with AI support, participants expressed “gut feel” about the decision outcome; how specific data characteristics, or features, may impact explanations; and the limitations of the AI system. Findings suggested what the authors call “intuition-driven pathways” to understanding the effect of different types of explanations on people’s decision to override AI. Results showed that example-based explanations, which were textual narratives, better aligned with people’s intuition and reasoning about a prediction than feature-based explanations, which conveyed information with bar charts and other visual tools. At the same time, participants echoed the familiar desire for help with understanding AI systems’ limitations. Suggestions included interface designs to better support transparency and user understanding—for example, interactive explanations that enable people to change attributes to explore the effect on the model’s prediction.
Accommodating varying levels of user expertise is a growing AI UX design challenge across domains and applications. For example, in business, people with limited knowledge of AI or statistics must increasingly engage AI visual-analytic systems to create reports and inform recommendations. While research seeks to address gaps in knowledge for improving user interaction with AI, some practical and evidence-driven tools are already available. A case study of business experts with varying levels of AI proficiency demonstrates the effectiveness of applying existing guidelines for human-AI interaction for transparency cues. Visual explanations improved participants’ ability to use a visual AI system to make recommendations. At the same time, researchers noted a high level of trust in outputs regardless of participants’ understanding of AI, illustrating the complexity of AI transparency for appropriate trust.
Related papers
- Designerly Understanding: Information Needs for Model Transparency to Support Design Ideation for AI-Powered User Experience
- Co-audit: tools to help humans double-check AI-generated content
- ColDeco: An End User Spreadsheet Inspection Tool for AI-Generated Code
- “What It Wants Me To Say”: Bridging the Abstraction Gap Between End-User Programmers and Code-Generating Large Language Models
- When to Show a Suggestion? Integrating Human Feedback in AI-Assisted Programming
- Generation Probabilities Are Not Enough: Exploring the Effectiveness of Uncertainty Highlighting in AI-Powered Code Completions
- Understanding the Role of Human Intuition on Reliance in Human-AI Decision-Making with Explanations
- Surfacing AI Explainability in Enterprise Product Visual Design to Address User Tech Proficiency Differences
Transparency: A means for accountability in a new era of AI
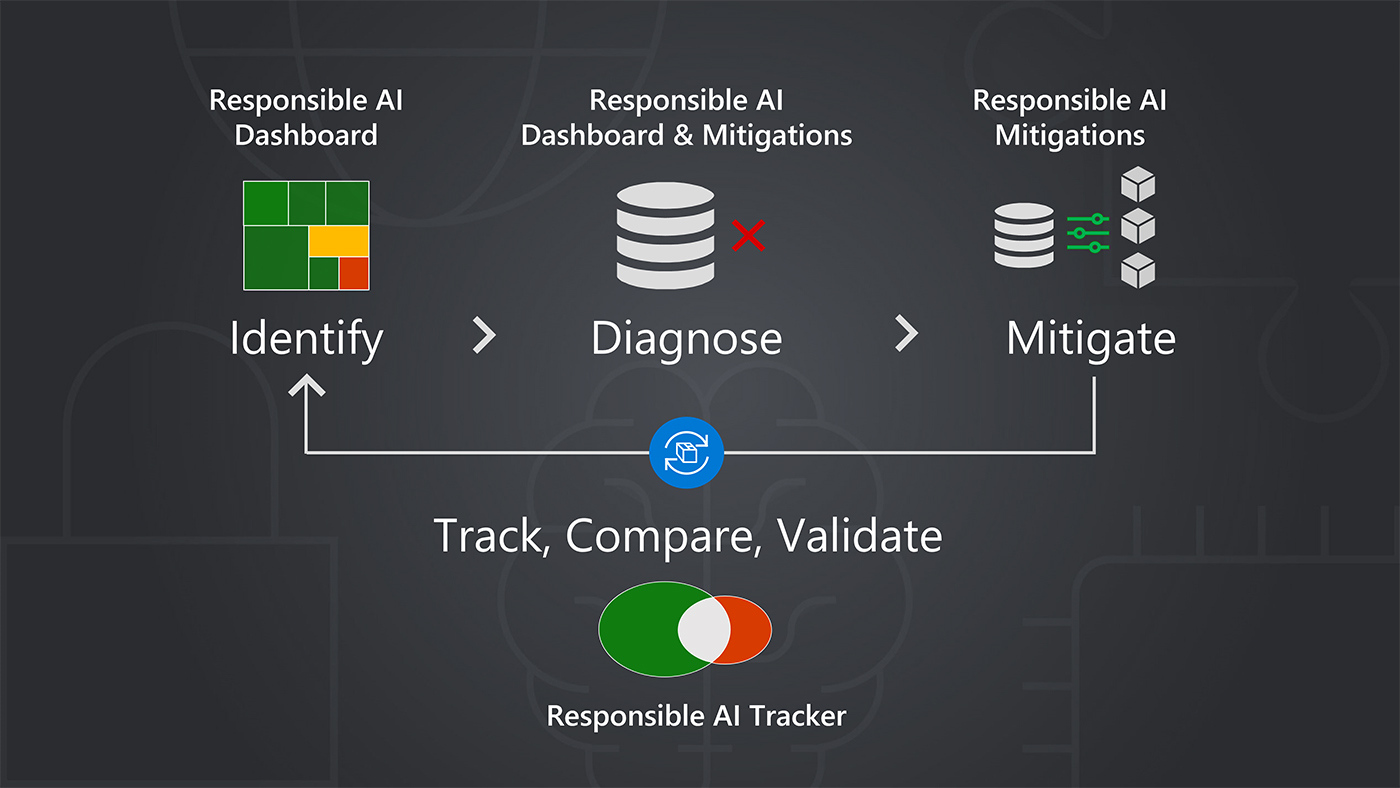
This research compilation highlights that transparency is fundamental to multiple components of responsible AI. It requires, among other things, the understanding and communication of datasets and their composition and of model behaviors, capabilities, and limitations. Transparency also touches every aspect of the responsible AI harm mitigation framework: identify, measure, mitigate. Furthermore, this research establishes a primary role for UX in mitigating harms as AI integrates into the apps people rely on every day in their personal and professional lives.
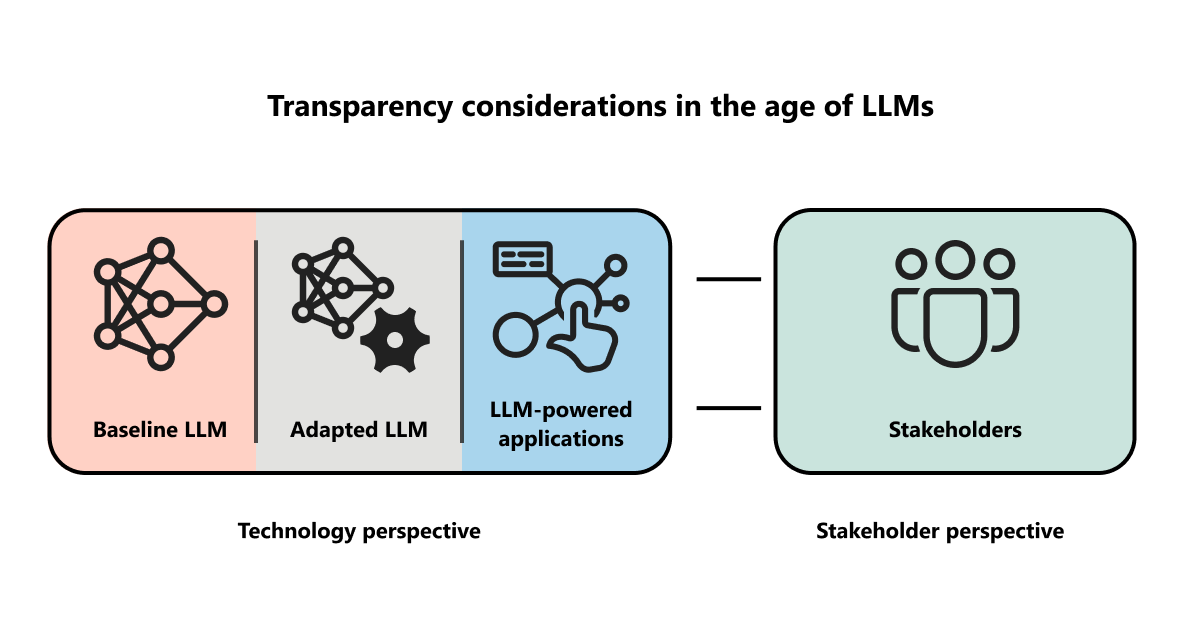
As authors of a research roadmap for transparency in the age of LLMs outline, these complex models’ massive datasets, nondeterministic outputs, adaptability, and rapid evolutionary pace present new challenges for deploying AI responsibly. There’s much work to be done to improve transparency for stakeholders of highly context-dependent AI systems—from improving how we publish the goals and results of evaluations when it comes to model reporting to providing appropriate explanations, communicating model uncertainty, and designing UX-based mitigations.
Prioritizing transparency in the design of our AI systems is to acknowledge the primacy of people, whom the technology is meant to serve. Transparency plays a critical role in respecting human agency and expertise in this new frontier of human-AI collaboration and, ultimately, can hold us accountable for the world we are shaping.

Pathways to deeper human-AI synergy
In his KDD 2023 keynote, Microsoft Chief Scientific Officer Eric Horvitz presents an overview of the power of LLM capabilities and the potential for enriching human-AI complementarity.
Related papers
- AI Transparency in the Age of LLMs: A Human-Centered Research Roadmap
- The Rise of the AI Co-Pilot: Lessons for Design from Aviation and Beyond
Microsoft research podcast

Abstracts: August 15, 2024
Advanced AI may make it easier for bad actors to deceive others online. A multidisciplinary research team is exploring one solution: a credential that allows people to show they’re not bots without sharing identifying information. Shrey Jain and Zoë Hitzig explain.