When legendary computer scientist Jim Gray accepted the Turing Award in 1999, he laid out a dozen long-range information technology research goals. One of those goals called for the creation of trouble-free server systems or, in Gray’s words, to “build a system used by millions of people each day and yet administered and managed by a single part-time person.”
Gray envisioned a self-organizing “server in the sky” that would store massive amounts of data, and refresh or download data as needed. Today, with the emergence and rapid advancement of artificial intelligence (AI), machine learning (ML) and cloud computing, and Microsoft’s development of Cloud Intelligence/AIOps, we are closer than we have ever been to realizing that vision—and moving beyond it.
Over the past fifteen years, the most significant paradigm shift in the computing industry has been the migration to cloud computing, which has created unprecedented digital transformation opportunities and benefits for business, society, and human life.
The implication is profound: cloud computing platforms have become part of the world’s basic infrastructure. As a result, the non-functional properties of cloud computing platforms, including availability, reliability, performance, efficiency, security, and sustainability, have become immensely important. Yet the distributed nature, massive scale, and high complexity of cloud computing platforms—ranging from storage to networking, computing and beyond—present huge challenges to building and operating such systems.
What is Cloud Intelligence/AIOps?

Cloud Intelligence/AIOps (“AIOps” for brevity) aims to innovate AI/ML technologies to help design, build, and operate complex cloud platforms and services at scale—effectively and efficiently.
AIOps has three pillars, each with its own goal:
- AI for Systems to make intelligence a built-in capability to achieve high quality, high efficiency, self-control, and self-adaptation with less human intervention.
- AI for Customers to leverage AI/ML to create unparalleled user experiences and achieve exceptional user satisfaction using cloud services.
- AI for DevOps to infuse AI/ML into the entire software development lifecycle to achieve high productivity.
Where did the research on AIOps begin?
Gartner, a leading industry analyst firm, first coined the term AIOps (opens in new tab) (Artificial Intelligence for IT Operations) in 2017. According to Gartner, AIOps is the application of machine learning and data science to IT operation problems. (opens in new tab) While Gartner’s AIOps concept focuses only on DevOps, Microsoft’s Cloud Intelligence/AIOps research has a much broader scope, including AI for Systems and AI for Customers.
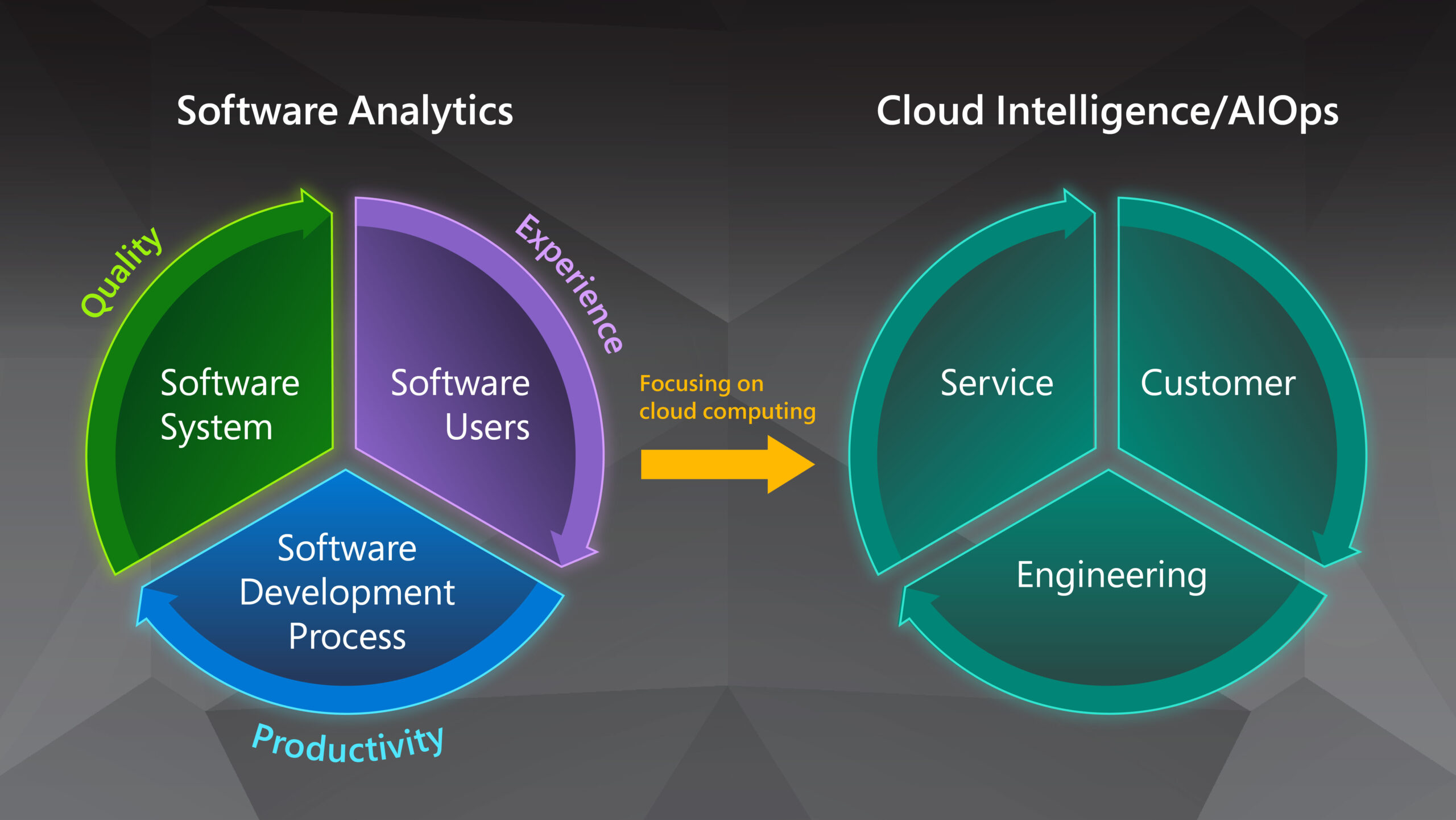
The broader scope of Microsoft’s Cloud Intelligence/AIOps stems from the Software Analytics research we proposed in 2009, which seeks to enable software practitioners to explore and analyze data to obtain insightful and actionable information for data-driven tasks related to software and services. We started to focus our Software Analytics research on cloud computing in 2014 and named this new topic Cloud Intelligence (Figure 1). In retrospect, Software Analytics is about the digital transformation of the software industry itself, such as empowering practitioners to use data-driven approaches and technologies to develop software, operate software systems, and engage with customers.

What is the AIOps problem space?
There are many scenarios around each of the three pillars of AIOps. Some example scenarios include predictive capacity forecasting for efficient and sustainable services, monitoring service health status, and detecting health issues in a timely manner in AI for Systems; ensuring code quality and preventing defective build deployed into production in AI for DevOps; and providing effective customer support in AI for Customers. Across all these scenarios, there are four major problem categories that, taken together, constitute the AIOps problem space: detection, diagnosis, prediction, and optimization (Figure 2). Specifically, detection aims to identify unexpected system behaviors (or anomalies) in a timely manner. Given the symptom and associated artifacts, the goal of diagnosis is to localize the cause of service issues and find the root cause. Prediction attempts to forecast system behaviors, customer workload patterns, or DevOps activities, and so on. Lastly, optimization tries to identify the optimal strategies or decisions required to achieve certain performance targets related to system quality, customer experience and DevOps productivity.
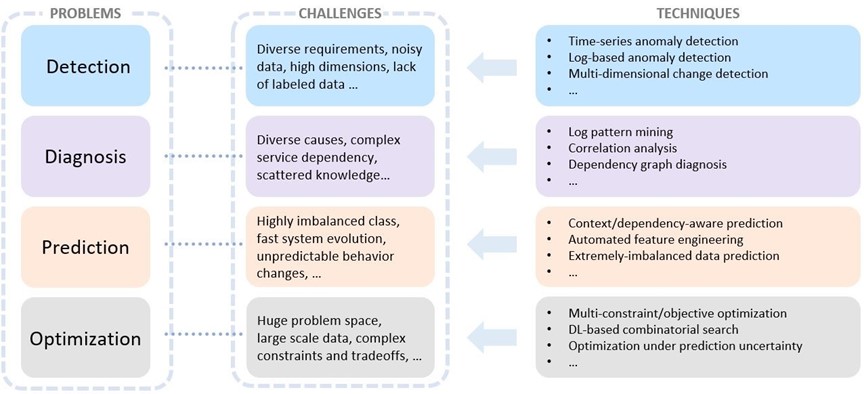
Each problem has its own challenges. Take detection as an example. To ensure service health at runtime, it is important for engineers to continuously monitor various metrics and detect anomalies in a timely manner. In the development process, to ensure the quality of the continuous integration/continuous delivery (CI/CD) practice, engineers need to create mechanisms to catch defective builds and prevent them from being deployed to other production sites.
Both scenarios require timely detection, and in both there are common challenges for conducting effective detection. For example, time series data and log data are the most common data forms. Yet they are often multi-dimensional, there may be noise in the data, and they often have different detection requirements—all of which can pose significant challenges to reliable detection.
Microsoft Research: Our AIOps vision
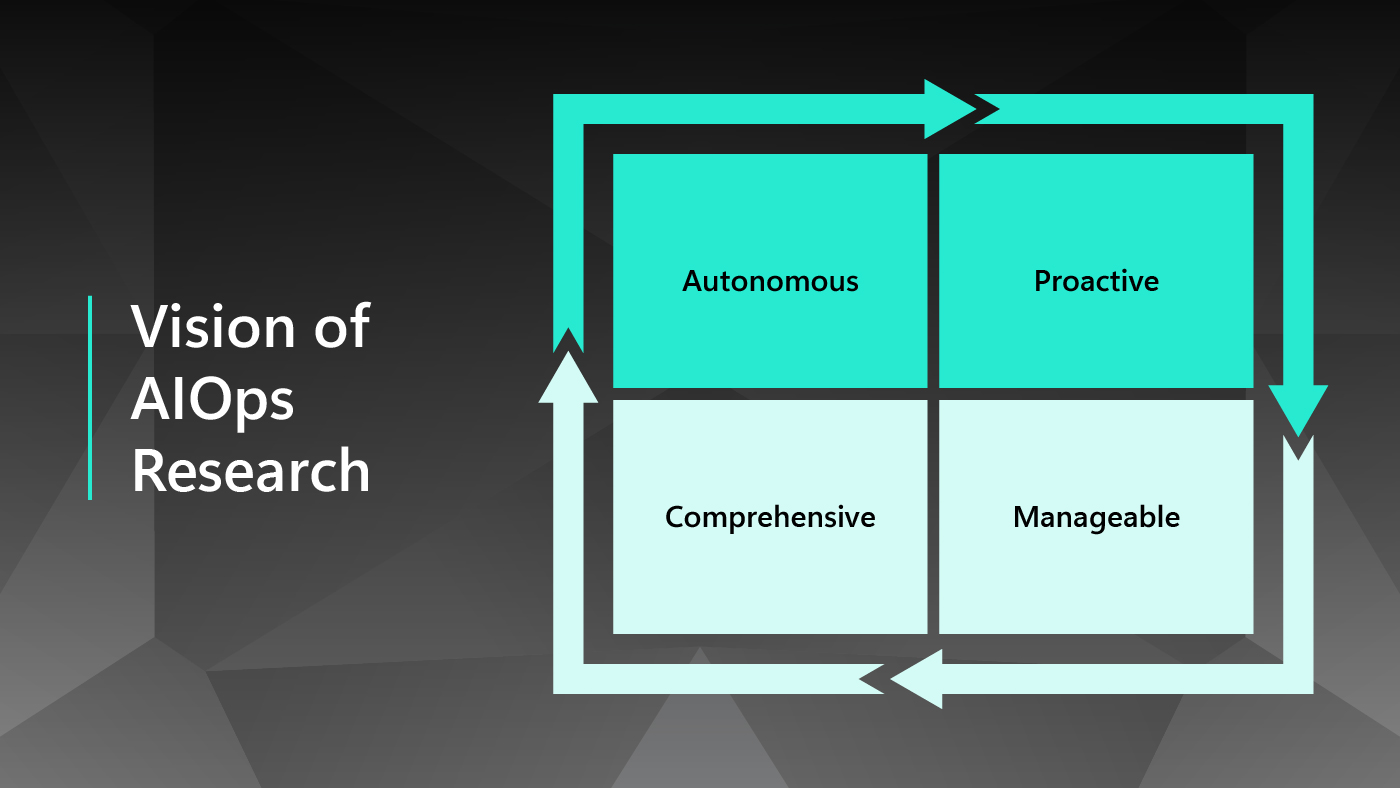
Microsoft is conducting continuous research in each of the AIOps problem categories. Our goal for this research is to empower cloud systems to be more autonomous, more proactive, more manageable, and more comprehensive across the entire cloud stack.
Making cloud systems more autonomous
AIOps strives to make cloud systems more autonomous, to minimize human operations and rule-based decisions, which significantly helps reduce user impact caused by system issues, make better operation decisions, and reduce maintenance cost. This is achieved by automating DevOps as much as possible, including build, deployment, monitoring, and diagnosis. For example, the purpose of safe deployment is to catch a defective build early to prevent it from rolling out to production and resulting in significant customer impact. It can be extremely labor intensive and time consuming for engineers, because anomalous behaviors have a variety of patterns that may change over time, and not all anomalous behaviors are caused by a new build, which may introduce false positives.
At Microsoft Research, we used transfer learning and active learning techniques to develop a safe deployment solution that overcomes these challenges. We’ve been running the solution in Microsoft Azure, and it has been highly effective at helping to catch defective builds – achieving more than 90% precision and near 100% recall in production over a period of 18 months.
Root cause analysis is another way that AIOps is reducing human operations in cloud systems. To shorten the mitigation time, engineers in cloud systems must quickly identify the root causes of emerging incidents. Owing to the complex structure of cloud systems, however, incidents often contain only partial information and can be triggered by many services and components simultaneously, which forces engineers to spend extra time diagnosing the root causes before any effective actions can be taken. By leveraging advanced contrast-mining algorithms, we have implemented autonomous incident-diagnosis systems, including HALO and Outage Scope, to reduce response time and increase accuracy in incident diagnosis tasks. These systems have been integrated in both Azure and Microsoft 365 (M365), which has considerably improved engineers’ ability to handle incidents in cloud systems.
Making cloud systems more proactive
AIOps makes cloud systems more proactive by introducing the concept of proactive design. In the design of a proactive system, an ML-based prediction component is added to the traditional system. The prediction system takes the input signals, does the necessary processing, and outputs the future status of the system. For example, what the capacity status of cluster A looks like next week, whether a disk will fail in a few days, or how many virtual machines (VMs) of a particular type will be needed in the next hour.
Knowing the future status makes it possible for the system to proactively avoid negative system impacts. For example, engineers can live migrate the services on an unhealthy computing node to a healthy one to reduce VM downtime, or pre-provision a certain number of VMs of a particular type for the next hour to reduce the latency of VM provisioning. In addition, AI/ML techniques can enable systems to learn over time which decision to make.
As an example of proactive design, we built a system called Narya, which proactively mitigated potential hardware failures to reduce service interruption and minimize customer impact. Narya, which is in production in Microsoft Azure, performs prediction on hardware failures and uses a bandit algorithm to decide which mitigation action to take.
Making cloud systems more manageable
AIOps makes cloud systems more manageable by introducing the notion of tiered autonomy. Each tier represents a set of operations that require a certain level of human expertise and intervention. These tiers range from the top tier of autonomous routine operations to the bottom tier, which requires deep human expertise to respond to rare and complex problems.
AI-driven automation often cannot handle such problems. By building AIOps solutions targeted at each tier, we can make cloud platforms easier to manage across the long tail of rare problems that inevitably arise in complex systems. Furthermore, the tiered design ensures that autonomous systems are developed from the start to evaluate certainty and risk, and that they have safe fallbacks when automation fails or the platform faces a previously unseen set of circumstances, such as the unforeseen increase in demand in 2020 due to the COVID-19 pandemic.
As an example of tiered autonomy, we built Safe On-Node Learning (SOL), a framework for safe learning and actuation on server nodes for the top tier. As another example, we are exploring how to predict the commands that operators should perform to mitigate incidents, while considering the associated certainty and risks of those commands when the top-tier automation fails to prevent the incidents.
Making AIOps more comprehensive across the cloud stack
AIOps can also be made more comprehensive by spanning the cloud stack—from the lowest infrastructure layers (such as network and storage) through the service layer (such as the scheduler and database) and on to the application layer. The benefit of applying AIOps more broadly would be a significant increase in the capability for holistic diagnosis, optimization, and management.
Microsoft services built on top of Azure are called first-party (1P) services. A 1P setting, which is often used to optimize system resources, is particularly suited to a more comprehensive approach to AIOps. This is because with the 1P setting a single entity has visibility into, and control over, the layers of the cloud stack, which enables engineers to amplify the AIOps impact. Examples of 1P services at Microsoft include large and established services such as Office 365, relatively new but sizeable services such as Teams, and up and coming services such as Windows 365 Cloud PC. These 1P services typically account for a significant share of resource usage, such as wide-area network (WAN) traffic and compute cores.
As an example of applying a more comprehensive AIOps approach to the 1P setting, the OneCOGS project, which is a joint effort of Azure, M365, and MSR, considers three broad opportunities for optimization:
- Modeling users and their workload using signals cutting across the layers—such as using the user’s messaging activity versus fixed working hours to predict when a Cloud PC user will be active—thereby increasing accuracy to enable enabling appropriate allocation of system resources.
- Jointly optimizing the application and the infrastructure to achieve cost savings and more.
- Tame the complexity of data and configuration (opens in new tab), thereby democratizing AIOps.
The AIOps methodologies, technologies and practices used for cloud computing platforms and 1P services are also applicable to third-party (3P) services on the cloud stack. To achieve this, further research and development are needed to make AIOps methods and techniques more general and/or easily adaptable. For example, when operating cloud services, detecting anomalies in multi-dimensional space and the subsequent fault localization are common monitoring and diagnosis problems.
Motivated by the real-world needs of Azure and M365, we proposed the technique AiDice, which automatically detects anomalies in multi-dimensional space, and HALO, a hierarchy-aware approach to locating fault-indicating combinations that uses telemetry data collected from cloud systems. In addition to deploying AiDice and HALO in Azure and M365, we’re also collaborating with product team partners to make AiDice and HALO AIOps services that can be leveraged by third-party services.
Conclusion
AIOps is a rapidly emerging technology trend and an interdisciplinary research direction across system, software engineering, and AI/ML communities. With years of research on Cloud Intelligence, Microsoft Research has built up rich technology assets in detection, diagnosis, prediction, and optimization. And through close collaboration with Azure and M365, we have deployed some of our technologies in production, which has created significant improvements in the reliability, performance, and efficiency of Azure and M365 while increasing the productivity of developers working on these products. In addition, we are collaborating with colleagues in academia and industry to promote the AIOps research and practices. For example, with the joint efforts we have organized 3 editions of AIOps Workshop at premium academic conferences AAAI 2020 (opens in new tab), ICSE 2021 (opens in new tab), and MLSys2022 (opens in new tab).
Moving forward, we believe that as a new dimension of innovation, Cloud Intelligence/AIOps will play an increasingly important role in making cloud systems more autonomous, more proactive, more manageable, and more comprehensive across the entire cloud stack. Ultimately, Cloud Intelligence/AIOps will help us make our vision for the future of the cloud a reality.