In video games, nonplayer characters, bots, and other game agents help bring a digital world and its story to life. They can help make the mission of saving humanity feel urgent, transform every turn of a corner into a gamer’s potential demise, and intensify the rush of driving behind the wheel of a super-fast race car. These agents are meticulously designed and preprogrammed to contribute to an immersive player experience.
| Join Us |
| This work was undertaken during an internship at Microsoft Research Cambridge. If you’re interested in exploring similar real-world challenges and developing actionable user-focused solutions, visit the lab’s internship page for details on internships in deep RL for games and other research areas. |
| For insights into AI and gaming research, register for the Microsoft AI and Gaming Research Summit 2021 (February 23–24), and for career opportunities in RL, check out the open positions with the Machine Intelligence theme at Microsoft Research Cambridge and other opportunities across Microsoft Research. |
Now, what if these same agents could learn to behave in lifelike and interesting ways without a developer having to hardcode every possible natural behavior in each scenario? Imagine agents in an action game learning a variety of offensive strategies to challenge a protagonist or agents in an adventure game learning how to support the player in unlocking information about an unfamiliar environment. Reinforcement learning (RL), in which agents learn how to act when they must sequentially take actions over time, provides a framework for achieving that. Through RL, agents can be trained to devise their own solutions to tasks, transforming the role of game designers from defining behavior to defining tasks and letting the agents learn. Such a shift has the potential to lead to surprising responses, possibly ones a game designer may not have even imagined, helping to create more engaging characters and worlds.

Reinforcement learning is already showing promising results. For example, we’ve demonstrated agents’ ability to effectively collaborate with each other in the Ninja Theory game Bleeding Edge as part of the Project Paidia research collaboration, which ultimately seeks to enable teamwork between agents and human players (for an RL overview, visit our Project Paidia website and interactive experience). At the same time, many experts feel the use of RL in the commercial game industry is still far below its ultimate potential. The reasons why are numerous, including the need for a certain level of expertise to execute the technology. From our previous research into the experiences of game agent creators, we’ve come to realize that for RL techniques to be used in the game industry, we need to design them with potential users and their existing workflows and requirements in mind. In recent work, we focus on three specific challenges:
- exercising authorial control when it comes to specifying the aesthetic style of game agents
- balancing multiple design constraints, specifically task completion and behaving in a desired style
- developing RL tools and infrastructure that are more meaningful from a designer perspective, allowing designers to make desired changes without formal engineering training
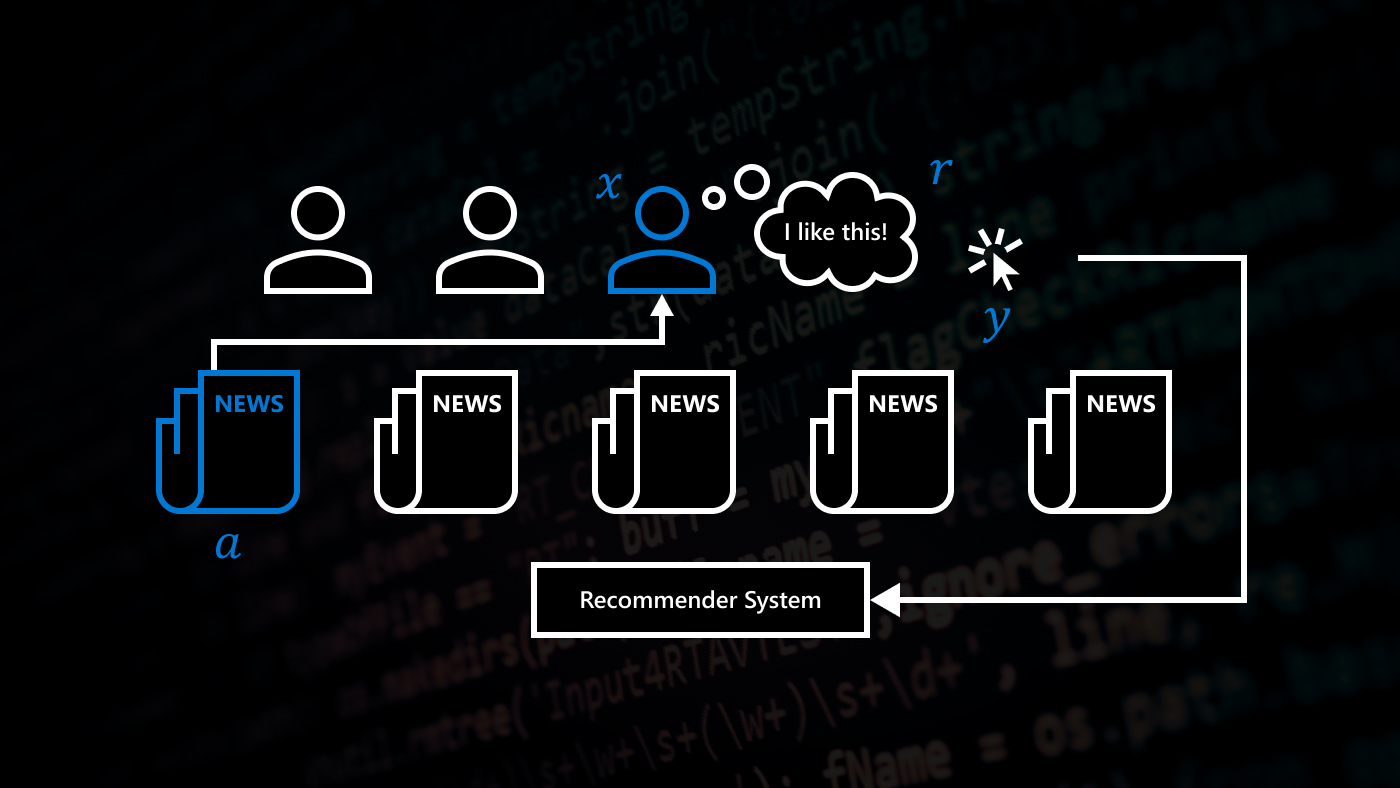
In this work, we establish the first steps toward a designer-centered approach to RL, making it easier for designers to specify an agent’s style through preference learning, automatically, robustly combined reward signals that satisfy varied design constraints, and a contextually meaningful workflow.
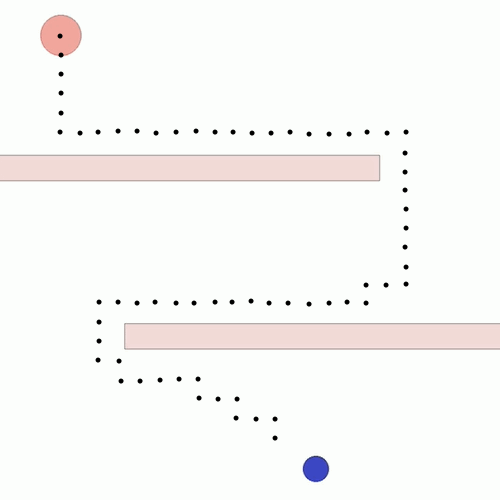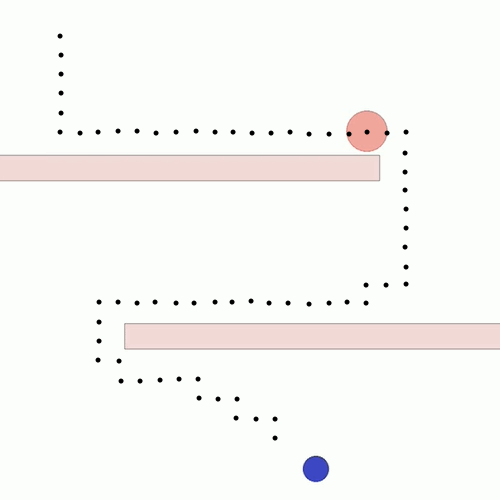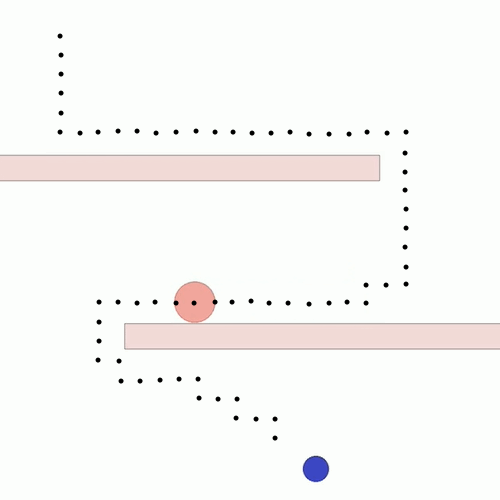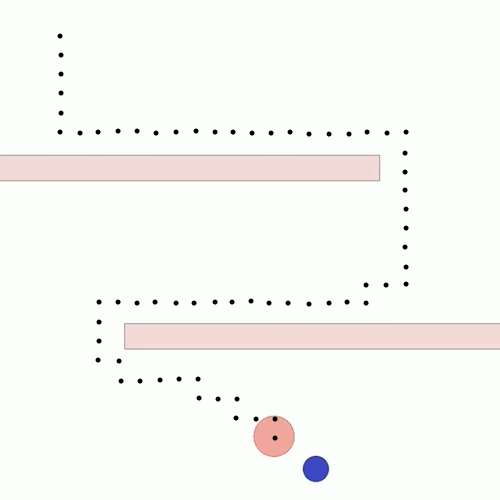
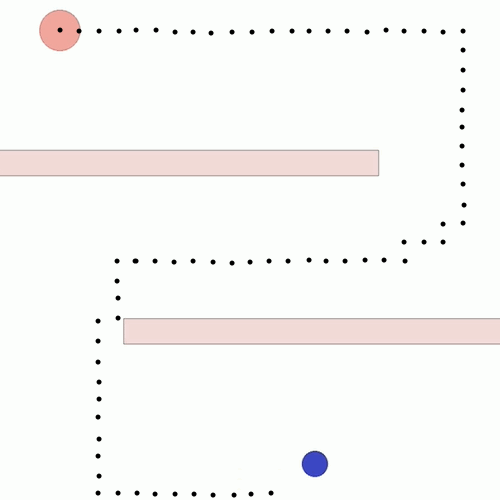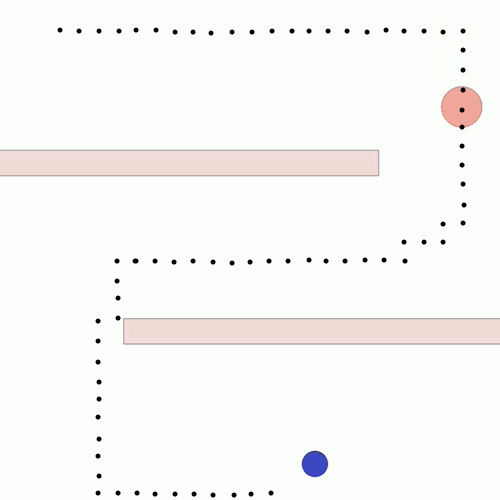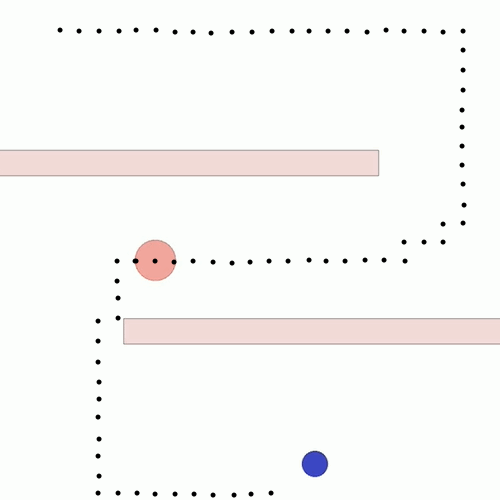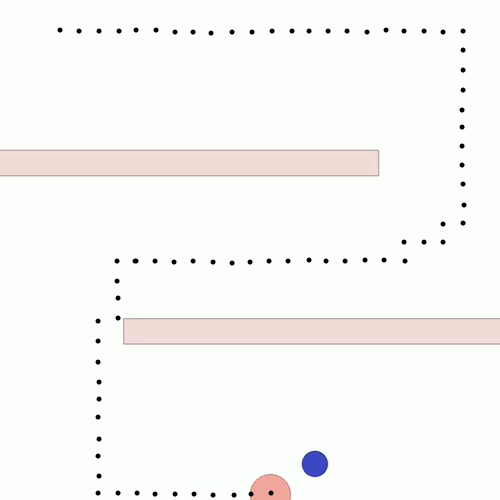
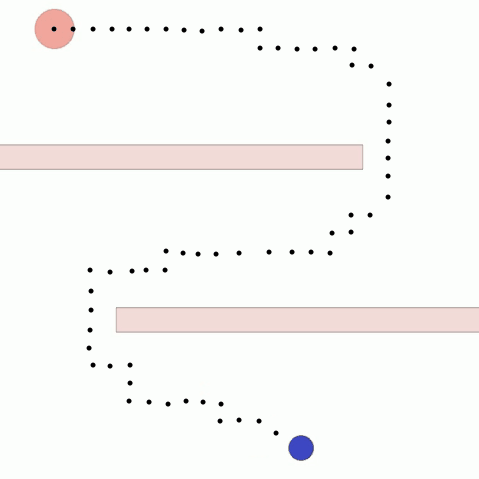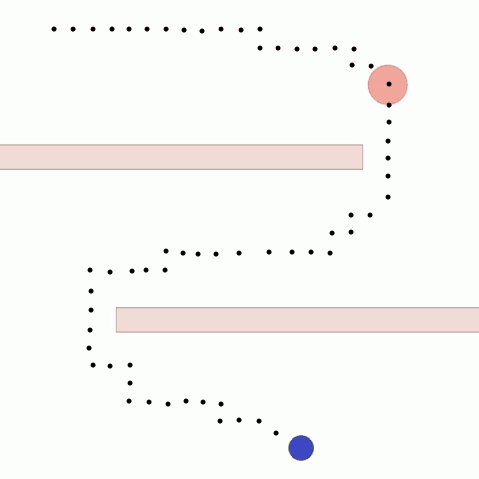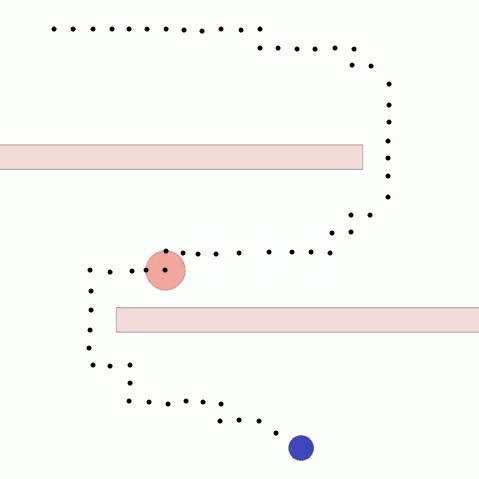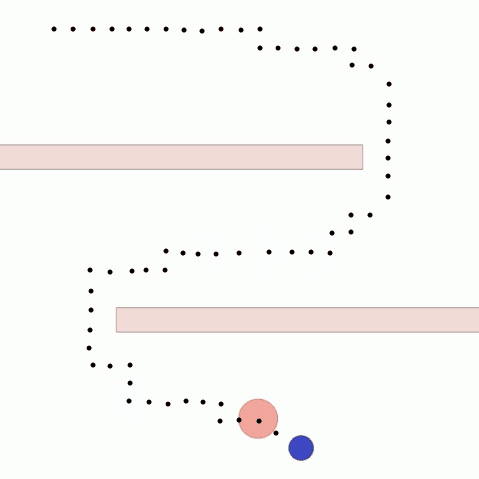
We show our results in a navigation task, as navigation is one of the most fundamental agent capabilities. In our experiments, we start with an agent that’s rewarded for getting closer to a goal as quickly as possible—in our case, a blue circle behind two “walls.” This results in the agent learning to take the shortest path to the blue circle, leading the agent to bump into and drag along the walls on its way. In this exploration, we assume the role of a designer aiming for movements more reflective of how a human player might approach the challenge, by taking a more central path.
Preference learning as a method to specify style rewards
RL algorithms learn through a reward function. Unfortunately, it’s very difficult to computationally specify aesthetic style. If we’re building a stealth game, we might want our agents to creep near building edges, but if we’re making a game about cyborg warriors, we would much prefer them charging through a scene. It’s unclear, though, how one might go about writing an RL style reward for being “stealthy” or “boisterous.” Even if it were, the designers who decide and tweak a game’s aesthetic aspects are often separate from the engineers who implement the underlying AI behavior, requiring that designers become proficient enough in RL to adjust the AI codebase to achieve a desired style. Such an expectation is unrealistic in larger teams and impractical with most designer workflows used today.
The traditional method to achieve our goal of reaching the blue circle as quickly as possible while taking a more central path would be to write an extension to the reward function, also known as reward shaping. We can punish the agent for being too close to the walls while still rewarding it for reaching the goal. However, even with extensive experimentation, it’s difficult to attain a behavior that’s exactly what we want, as what we really want isn’t simply “staying away from the walls” but a more nuanced style of movement that’s hard to capture mathematically.
It would be much easier to recognize a desired style as opposed to describing it mathematically. Because of this, we implemented a preference-based learning method (opens in new tab) to allow designers to specify their desired style through a simple user interface—no coding required!
Our proposed method works as follows:
- The policy, pretrained on the task reward, interacts with the environment and produces a set of trajectories.
- The designer is shown segments of these trajectories, and they pick which segment is closer to their desired style.
- A reward network tasked with capturing the style is updated according to the designer’s preferences.
- The reward network predicts how much a state exhibits the learned style. This predicted style reward plus the original task reward is used to optimize the original policy.
- A new set of trajectories is collected with the updated policy to get new preferences.
Because RL training takes time, we fine-tune an already competent agent, cutting the amount of iteration down drastically compared to training an agent from scratch; all we need to do is add style to it. Further, this makes it easier to apply different styles to the same base agent, allowing AI engineers to train a base model and then designers to fine-tune style preferences.
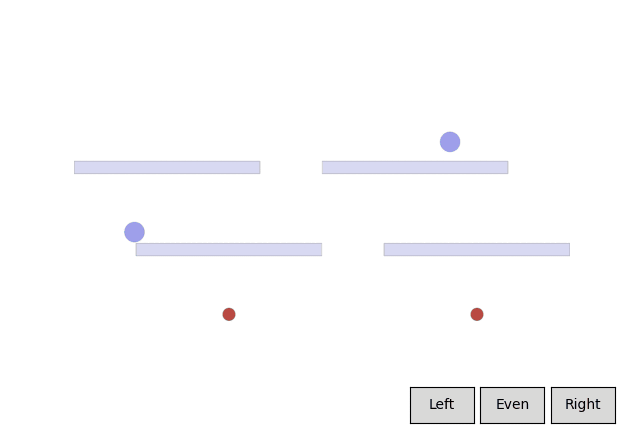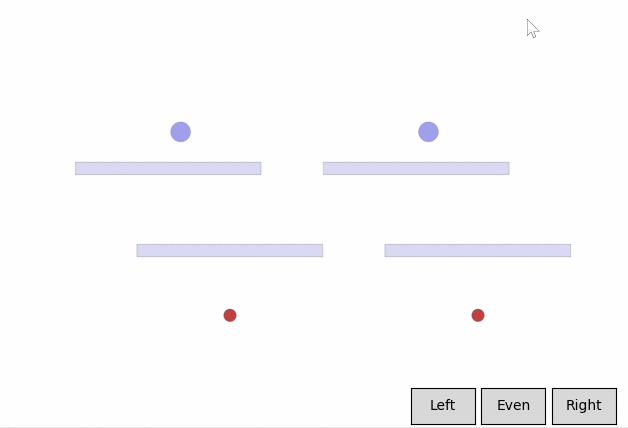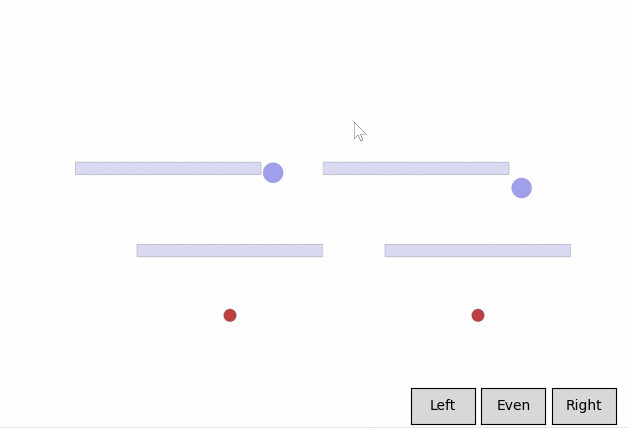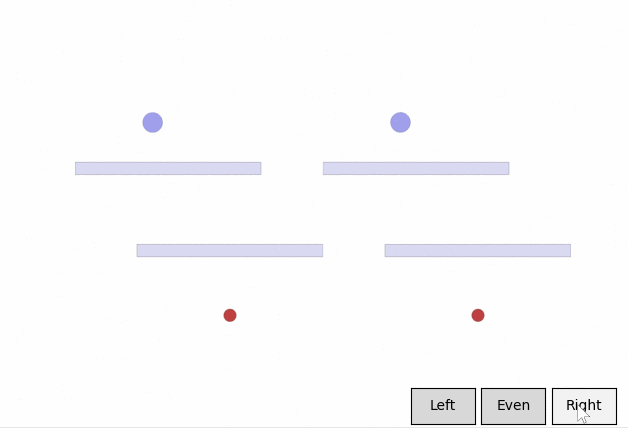
In a feedback efficiency study, we show we can reliably train a successful agent in our given task. For our task, training is only considered successful if the agent completes the task with a high enough style reward (measured by the mean distance from the nearest wall) and an acceptable task reward (an approximate equivalent to the time it takes to reach the goal). We reached our desired behavior in 50 comparisons. We expect the number of required preferences to increase as the complexity of the environment and of the desired style goes up.
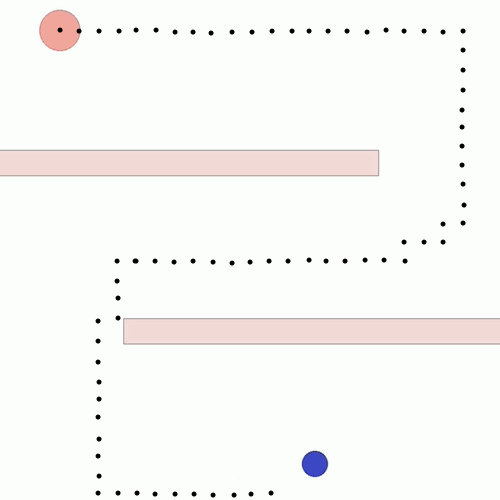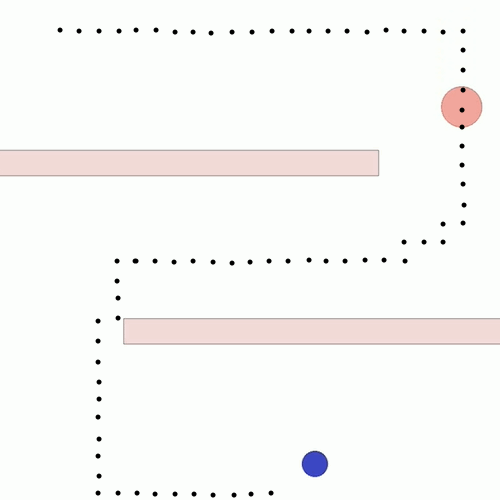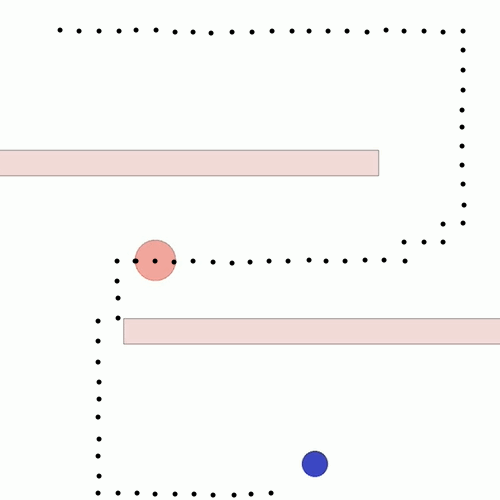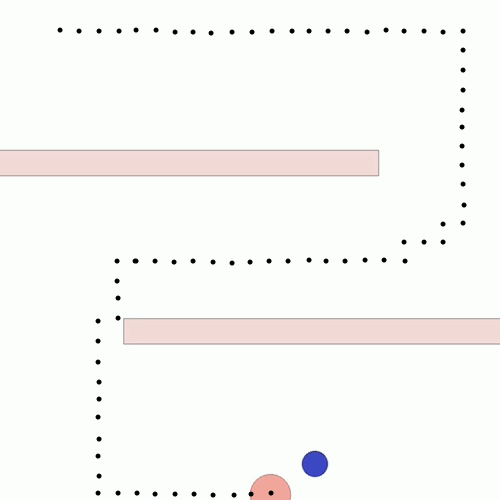
Potential-based shaping to combine style and task rewards
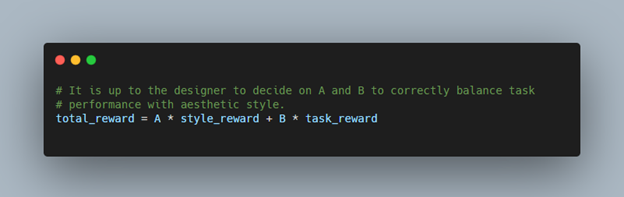
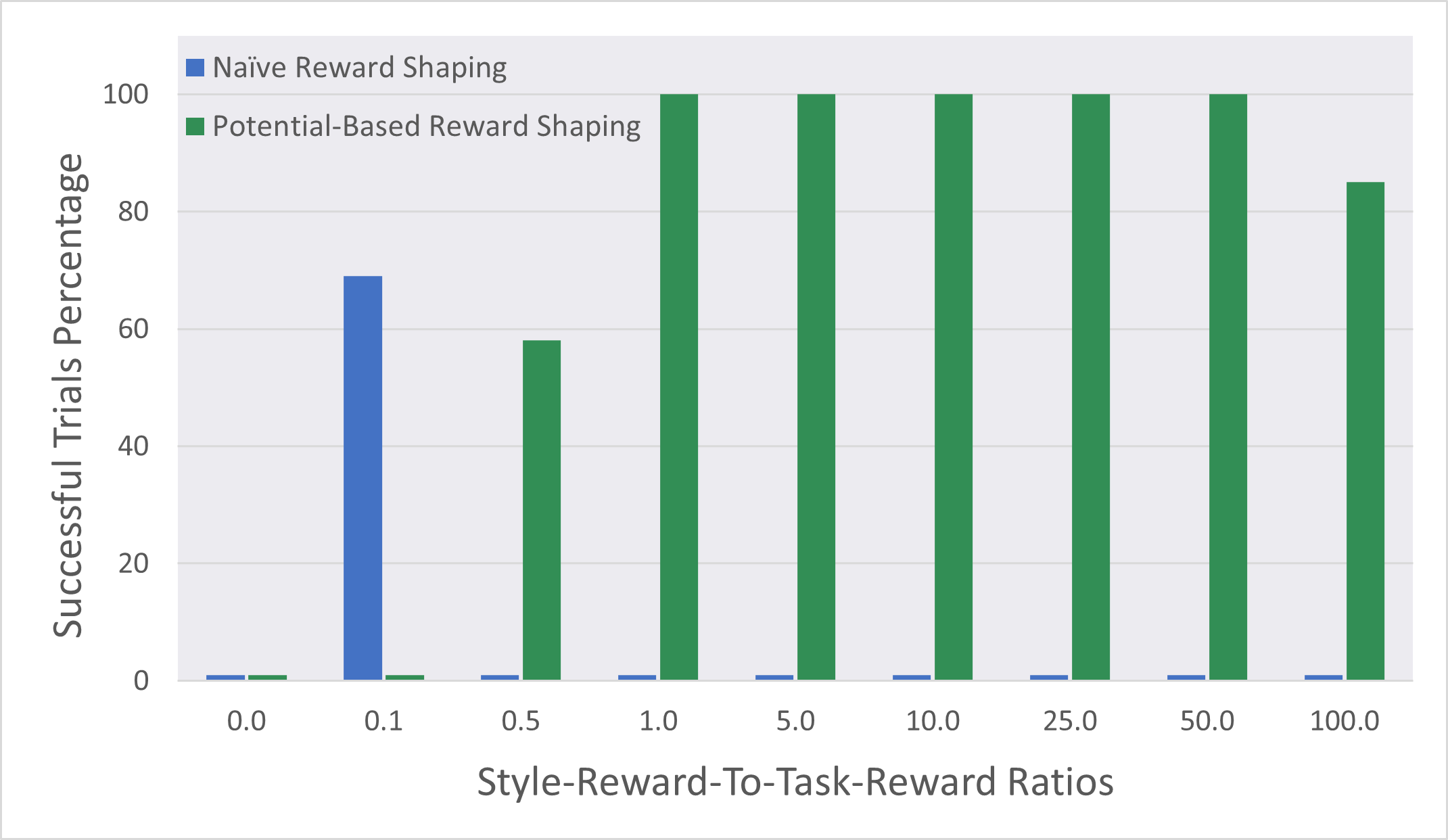
Specifying the reward that captures the desired style is only the first step; the style reward must then be integrated into the agent’s preexisting task reward. This is by no means a trivial undertaking. If the ratio of the style reward to the task reward is too high, the style reward overwhelms the task reward and navigation performance suffers. If the ratio is too low, then there’s no observable behavior change. The default approach to solving this problem is to iterate—tweak the ratio slightly and run another experiment. Since each RL training run can take hours, trying to tune the style and task reward ratios manually is laborious and mind-numbingly boring.
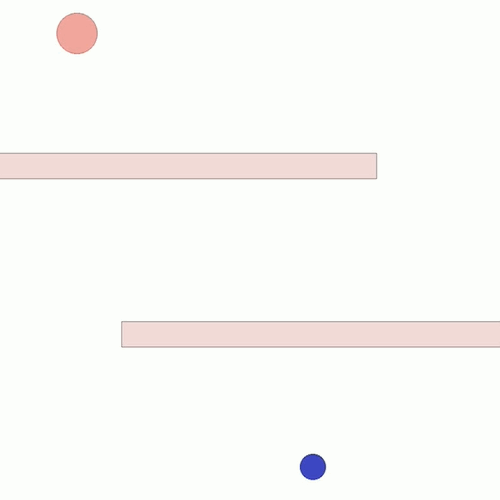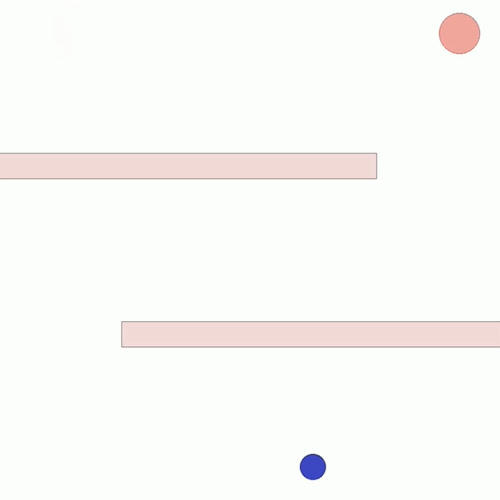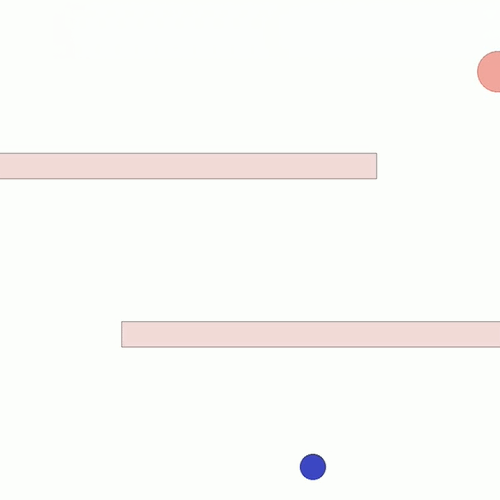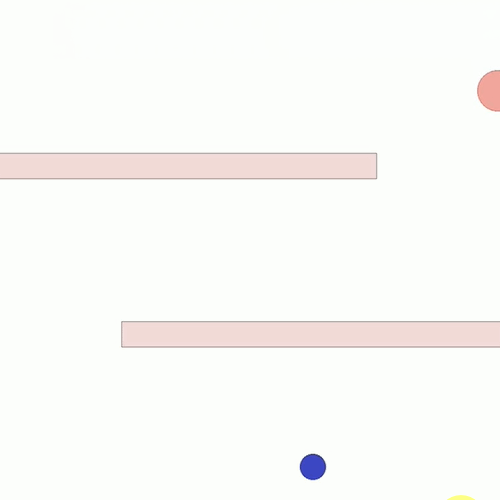
When we first tried to fine-tune our agent with our new style, it failed to be successful in the initial task, as it gave too much weight to exhibiting the style! We used potential-based reward shaping (PBRS) (opens in new tab) to solve this problem. PBRS ensures that when a shaping reward is introduced—that is, a reward encouraging behavior other than the initial task, like our style reward—the optimal policy for the initial task remains the same.
PBRS is a simple yet powerful technique where, at each step, we subtract the previous step’s style reward from the total reward (task reward plus style reward) of the current step. This means the agent is rewarded for being at a certain state and not moving into a certain state. The intuition behind PBRS can be expressed with the following example: imagine an agent is rewarded for crossing the finish line in a race. After crossing the finish line initially, the agent might be encouraged to step back over the finish line and forward again multiple times, effectively gaining infinite rewards. However, with PBRS, we only reward the agent for being at the finish line, not crossing it: whenever the agent steps back, we take away the reward we had given it, preventing it from accruing more reward by simply crossing back and forth.
Spotlight: blog post

GraphRAG auto-tuning provides rapid adaptation to new domains
GraphRAG uses LLM-generated knowledge graphs to substantially improve complex Q&A over retrieval-augmented generation (RAG). Discover automatic tuning of GraphRAG for new datasets, making it more accurate and relevant.
While the distinction is subtle, this prevents the agent from “reward hacking” to maximize rewards without accomplishing the initial task. When we started using PBRS to integrate our style reward into the task reward, the training was more successful in both keeping the original task rewards high and displaying the desired style. This alternative to the time-consuming task of fine-tuning the ratio of style reward to task reward manually means designers can explore many more style variations instead of spending their resources getting a single style to work properly.
Automatic reward ratio adjustment to increase designer control
Even though using PBRS made finding an acceptable ratio of style reward to task reward much easier, we’re still asking designers to fine-tune a behavior by changing an arbitrary numeric ratio. There’s no designer-interpretable meaning to “combining one parts task reward with four parts style reward.”
Rewards, especially when designed intentionally, can be meaningful from a design perspective. For example, if the agent is penalized by 1 point every second, we can see how fast the agent reaches the goal by simply looking at the final reward. A –15 task reward means the agent took 15 seconds to reach the goal. In scenarios where it’s possible to provide similar types of meaningful rewards, it would be much more efficient for a designer to specify a minimum performance that’s acceptable—a lower bound reward threshold—versus tweaking arbitrary numeric ratios.
Toward this end, we implemented an automatic reward ratio schedule that tries to maximize the style reward while respecting the designer-specified threshold. The automated scheduler increases the ratio of style reward to task reward while the task reward is higher than the designer-specified threshold and reduces the ratio when the task performance starts to degrade. To be more specific, we linearly scale the style reward ratio between a maximum number and 0—between the starting performance and the threshold performance. In the above example, if a designer wanted their agent to reach the goal in at most 15 seconds, the automated scheduler would increase the ratio of style reward to task reward until the agent started taking longer than the specified 15 seconds. At that point, the scheduler would then reduce the style reward weight until a performance time of 15 seconds was achieved. This automated schedule would continue over the course of training.
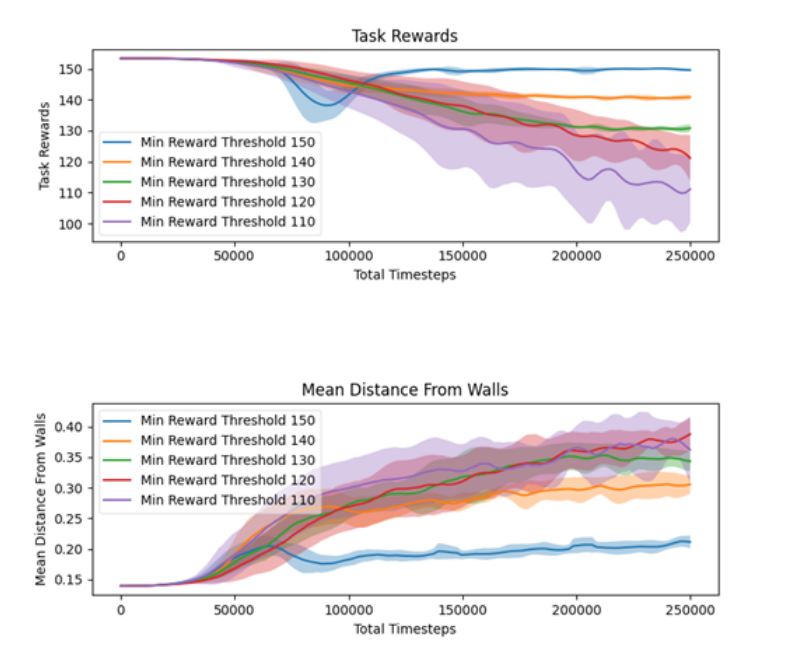
Figure 2a shows the task reward with different designer-specified minimum task reward thresholds. The automated reward ratio adjustment is effective in keeping the task reward above the specified performance threshold.
Figure 2b shows the mean distance to the closest wall, a simple approximation of our target style, under different reward thresholds. When the minimum task reward threshold is very high (150), the change in behavior is rather small, as the agent is prioritizing the task reward over exhibiting the style. However, as the designer relaxes the constraints, more style behavior emerges.
This method of specifying a desired reward is much more meaningful than iteratively changing the numeric ratio to hit the desired target. We believe this workflow simplifies the job of the designer immensely.
Open questions and continued collaboration
While these results are encouraging, there are several open research questions. First, we need to validate our findings with a user study. While the high-level workflow is established, there’s more to learn regarding the specifics. In the context of our proposed solutions, do designers continuously monitor the training, or do they give feedback in batches? What information is shown to the designers for them to make accurate choices?
Another open question is exploring different methods of specifying a style. While preferences are useful, there are many other methods we can employ. Designers can demonstrate the desired style by taking control of the agent, or they can annotate individual states to guide the fine-tuning. It’s unclear which of these methods (or what combination) offers the most control to the designers.

The journey toward RL that can be easily and organically incorporated into commercial game design is a long one. We feel taking a designer-centered approach, as demonstrated by the prototypes above, offers a promising means to achieving that goal, and we look forward to continuing to work with professionals in the game industry to deliver practical and empowering solutions.
Additional resources and opportunities
- Research Collection – Shall we play a game? (opens in new tab)
- “Reinforcement learning in Minecraft: Challenges and opportunities in multiplayer games” Webinar (opens in new tab)
This work was spearheaded by UC Santa Cruz PhD student Batu Aytemiz (opens in new tab) during a Microsoft Research Cambridge internship (opens in new tab). Team members Mikhail Jacob (opens in new tab), Sam Devlin (opens in new tab), and Katja Hofmann (opens in new tab) served as advisors on the work.