
This research was accepted by the IEEE/ACM International Conference on Software Engineering (ICSE) (opens in new tab), which is a forum for researchers, practitioners, and educators to gather, present, and discuss the most recent innovations, trends, experiences, and issues in the field of software engineering.
The Microsoft 365 Systems Innovation research group has a paper accepted at the 45th International Conference on Software Engineering (ICSE), widely recognized as one of the most prestigious research conferences on software engineering. This paper, Recommending Root-Cause and Mitigation Steps for Cloud Incidents using Large Language Models, focuses on using state-of-the-art large language models (LLMs) to help generate recommendations for cloud incident root cause analysis and mitigation plans. With a rigorous study on real production incidents and analysis of several LLMs in different settings using semantic and lexical metrics as well as human evaluation, the research shows the efficacy and future potential of using AI for resolving cloud incidents.
Challenges of building reliable cloud services
Building highly reliable hyperscale cloud services such as Microsoft 365 (M365), which supports the productivity of hundreds of thousands of organizations, is very challenging. This includes the challenge of quickly detecting incidents, then performing root cause analysis and mitigation.
Our recent research starts with understanding the fundamentals of production incidents: we analyze the life cycle of incidents, then determine the common root causes, mitigations, and engineering efforts for resolution. In a previous paper: How to Fight Production Incidents? An Empirical Study on a Large-scale Cloud Service (opens in new tab), which won a Best Paper award at SoCC’22 (opens in new tab), we provide a comprehensive, multi-dimensional empirical study of production incidents from Microsoft Teams. From this study, we envision that automation should support incident diagnosis and help identify the root cause and mitigation steps to quickly resolve an incident and minimize customer impact. We should also leverage past lessons to build resilience for future incidents. We posit that adopting AIOps and using state-of-the-art AI/ML technologies can help achieve both goals, as we show in the ICSE paper.
Microsoft Research Blog

Microsoft Research Forum Episode 3: Globally inclusive and equitable AI, new use cases for AI, and more
In the latest episode of Microsoft Research Forum, researchers explored the importance of globally inclusive and equitable AI, shared updates on AutoGen and MatterGen, presented novel use cases for AI, including industrial applications and the potential of multimodal models to improve assistive technologies.
Adapting large-language models for automated incident management
Recent breakthroughs in AI have enabled LLMs to develop a rich understanding of natural language. They can understand and reason over large volumes of data and complete a diverse set of tasks, such as code completion, translation, and Q&A. Given the complexities of incident management, we sought to evaluate the effectiveness of LLMs in analyzing the root cause of production incidents and generating mitigation steps.
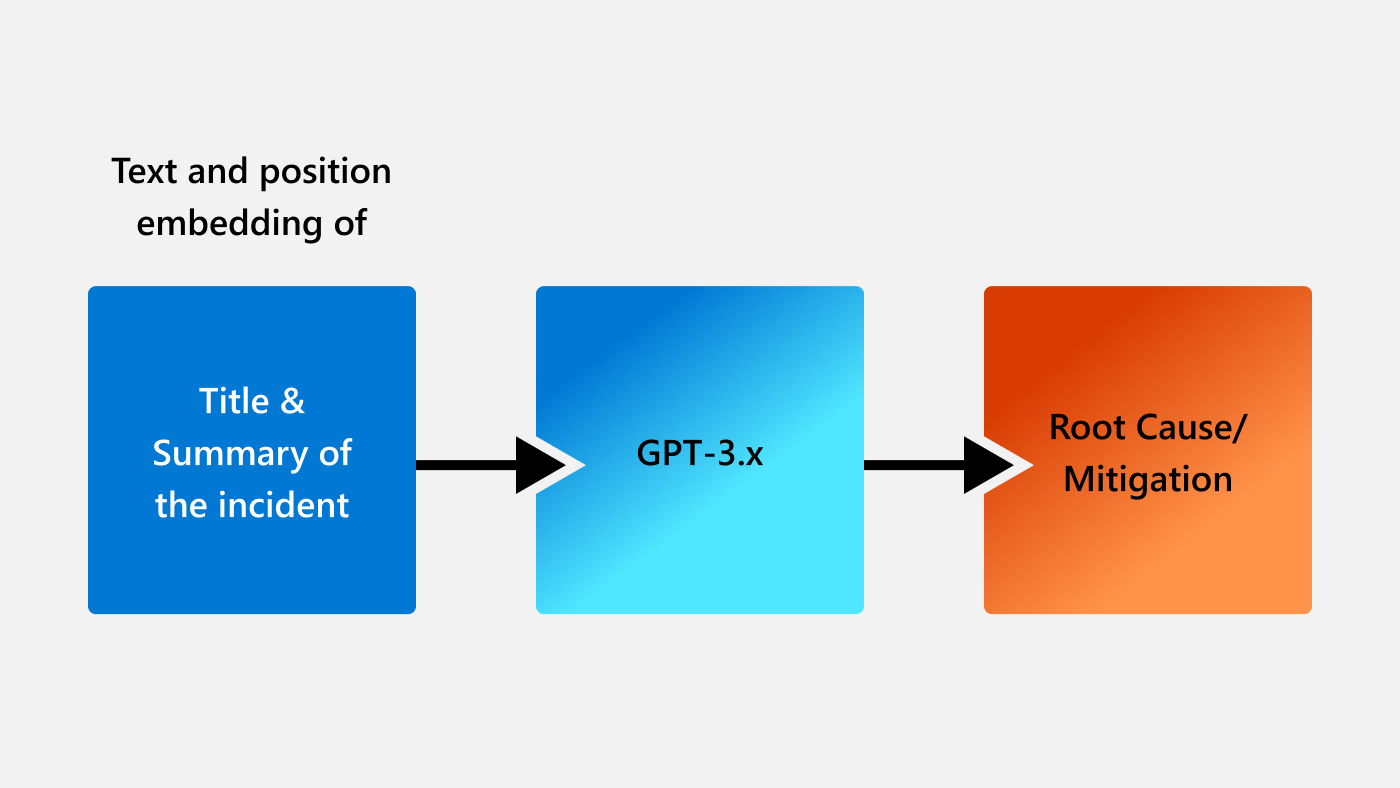
In our recently published ICSE paper, we demonstrated the usefulness of LLMs for production incident diagnosis for the first time. When an incident ticket is created, the author specifies a title for each incident created and describes any relevant details, such as error messages, anomalous behavior, and other details which might help with resolution. We used the title and the summary of a given incident as the input for LLMs and generated root cause and mitigation steps, as shown in Figure 1.
We did a rigorous study on more than 40,000 incidents generated from more than 1000 services and compared several LLMs in zero-shot, fine-tuned, and multi-task settings. We find that fine-tuning the GPT-3 and GPT-3.5 models significantly improves the effectiveness of LLMs for incident data.
Effectiveness of GPT-3.x models at finding root causes
| Model | BLEU-4 | ROUGE-L | METEOR | BERTScore | BLEURT | NUBIA | ||||||
| Top1 | Top5 | Top1 | Top5 | Top1 | Top5 | Top1 | Top5 | Top1 | Top5 | Top1 | Top5 | |
| RoBERTa | 4.21 | NA | 12.83 | NA | 9.89 | NA | 85.38 | NA | 35.66 | NA | 33.94 | NA |
| CodeBERT | 3.38 | NA | 10.17 | NA | 6.58 | NA | 84.88 | NA | 33.19 | NA | 39.05 | NA |
| Curie | 3.40 | 6.29 | 19.04 | 15.44 | 7.21 | 13.65 | 84.90 | 86.36 | 32.62 | 40.08 | 33.52 | 49.76 |
| Codex | 3.44 | 6.25 | 8.98 | 15.51 | 7.33 | 13.82 | 84.85 | 86.33 | 32.50 | 40.11 | 33.64 | 49.77 |
| Davinci | 3.34 | 5.94 | 8.53 | 15.10 | 6.67 | 12.95 | 83.13 | 84.41 | 31.06 | 38.61 | 35.28 | 50.79 |
| Davinci-002 | 4.24 | 7.15 | 11.43 | 17.2 | 10.42 | 16.8 | 85.42 | 86.78 | 36.77 | 42.87 | 32.3 | 51.34 |
| %gain for Davinci-002 | 23.26 | 13.67 | 26.44 | 10.90 | 42.16 | 21.56 | 0.61 | 0.49 | 12.72 | 6.88 | -8.45 | 1.08 |
In our offline evaluation, we compared the performance of GPT-3.5 against three GPT-3 models by computing several semantic and lexical metrics (which measures the text similarity) between the generated recommendations and the ground truth of root cause or mitigation steps mentioned in incident management (IcM) portal. The average gains for GPT-3.5 metrics for different tasks were as follows:
- For root cause and mitigation recommendation tasks, Davinci-002 (GPT-3.5) provided at least 15.38% and 11.9% gains over all the GPT-3 models, respectively, as shown in Table 1.
- When we generated mitigation plans by adding root cause as input to the model, GPT-3.5 model provided at least an 11.16% gain over the GPT-3 models.
- LLMs performed better on machine reported incidents (MRIs) as opposed to customer reported incidents (CRIs), due to the repetitive nature of the MRIs.
- Fine-tuning LLMs with incident data improved performance significantly. A fine-tuned GPT-3.5 model improved the average lexical similarity score by 45.5% for root cause generation and 131.3% for mitigation generation tasks over zero-shot (i.e., inferencing directly on pretrained GPT-3 or GPT-3.5 model) setting.
Looking through the incident owners’ eyes
In addition to analysis with semantic and lexical metrics, we also interviewed the incident owners to evaluate the effectiveness of the generated recommendations. Overall, GPT-3.5 outperforms GPT-3 in a majority of the metrics. More than 70% of on-call engineers gave a rating of 3 out of 5 or better for the usefulness of recommendations in a real-time production setting.
Looking forward
With future versions of LLMs coming, we expect the performance for automatic incident resolution will further improve, and the need for fine-tuning may decrease. Yet we are in the initial stage, with many open research questions in this field. For instance, how can we incorporate additional context about the incident, such as discussion entries, logs, service metrics, and even dependency graphs of the impacted services to improve the diagnosis? Another challenge is staleness since the models would need to be frequently retrained with the latest incident data. To solve these challenges, we are working on leveraging the latest LLMs combined with retrieval augmented approaches to improve incident diagnosis via a conversational interface, as shown in Figure 2.

Moreover, ChatGPT can be actively integrated into the «discussion» of the incident diagnosis. By collecting evidence from available documents and logs, the model can generate coherent, contextual, natural-sounding responses to inquiries and offer corresponding suggestions, thereby facilitating the discussion and accelerating the incident resolution process. We believe this could deliver a step function improvement in the overall incident management process with contextual and meaningful root causes analysis and mitigation, thereby reducing significant human effort required and bolstering reliability and customer satisfaction.
Acknowledgement
This post includes contributions from Toufique Ahmed (opens in new tab) during his internship at Microsoft.



