
- Group Robot Learning Group
What would it take to get humanoid, bipedal robots to dance like Mick Jagger? Indeed, for something more mundane, what does it take to get them to simply stand still? Sit down? Walk? Move in myriads of other ways many people take for granted? Bipedalism provides unparalleled versatility in an environment designed for and by humans. By mixing and matching a wide range of basic motor skills, from walking to jumping to balancing on one foot, people routinely dance, play soccer, carry heavy objects, and perform other complex high-level motions. If robots are ever to reach their full potential as an assistive technology, mastery of diverse bipedal motion is a requirement, not a luxury. However, even the simplest of these skills can require a fine orchestration of dozens of joints. Sophisticated engineering can rein in some of this complexity, but endowing bipedal robots with the generality to cope with our messy, weakly structured world, or a metaverse that takes after it, requires learning. Training AI agents with humanoid morphology to match human performance across the entire diversity of human motion is one of the biggest challenges of artificial physical intelligence. Due to the vagaries of experimentation on physical robots, research in this direction is currently done mostly in simulation.
Unfortunately, it involves computationally intensive methods, effectively restricting participation to research institutions with large compute budgets. In an effort to level the playing field and make this critical research area more inclusive, Microsoft Research’s Robot Learning group is releasing MoCapAct, a large library of pre-trained humanoid control models along with enriched data for training new ones. This will enable advanced research on artificial humanoid control at a fraction of the compute resources currently required.
The reason why humanoid control research has been so computationally demanding is subtle and, at the first glance, paradoxical. The prominent avenue for learning locomotive skills (opens in new tab) is based on using motion capture (opens in new tab) (MoCap) data. MoCap is an animation technique widely used in the entertainment industry for decades. It involves recording the motion of several keypoints on a human actor’s body, such as their elbows, shoulders, and knees, while the actor is performing a task of interest, such as jogging. Thus, a MoCap clip can be thought of as a very concise and precise summary of an activity’s video clip. Thanks to this, useful information can be extracted from MoCap clips with much less computation than from the much more high-dimensional, ambiguous training data in other major areas of machine learning, which comes in the form of videos, images, and text. On top of this, MoCap data is widely available. Repositories such as CMU Motion Capture Dataset (opens in new tab) contain hours of clips for just about any common motion of a human body, with visualizations of several examples shown below. Why, then, is it so hard to make physical and simulated humanoid robots mimic a person’s movements?
Microsoft research podcast

What’s Your Story: Lex Story
Model maker and fabricator Lex Story helps bring research to life through prototyping. He discusses his take on failure; the encouragement and advice that has supported his pursuit of art and science; and the sabbatical that might inspire his next career move.
The caveat is that MoCap clips don’t contain all the information necessary to imitate the demonstrated motions on a physical robot or in a simulation that models physical forces. They only show us what a motion skill looks like, not the underlying muscular movements that caused the actor’s muscles to yield that motion. Even if MoCap systems recorded these signals, it wouldn’t be of much help: simulated humanoids and real robots typically use motors instead of muscles, which is a dramatically different form of articulation. Nonetheless, actuation in artificial humanoids is also driven by a type of control signal. MoCap clips are a valuable aid in computing these control signals, if combined with additional learning and optimization methods that use MoCap data as guidance. The computational bottleneck that our MoCapAct release aims to remove is created exactly by these methods, collectively known as reinforcement learning (opens in new tab) (RL). In simulation, where much of AI locomotion research is currently focused, RL can recover the sequence of control inputs that takes a humanoid agent through the sequence of poses from a given MoCap clip. What results is a locomotion behavior that is indistinguishable from the clip’s. The availability of control policies for individual basic behaviors learned from separate MoCap clips can open the doors for fascinating locomotion research, e.g., in methods for combining these behaviors into a single “multi-skilled” neural network and training higher-level locomotion capabilities by switching among them. However, with thousands of basic locomotion skills to learn, RL’s expensive trial-and-error approach creates a massive barrier to entry on this research path. It is this scalability issue that our dataset release aims to address.
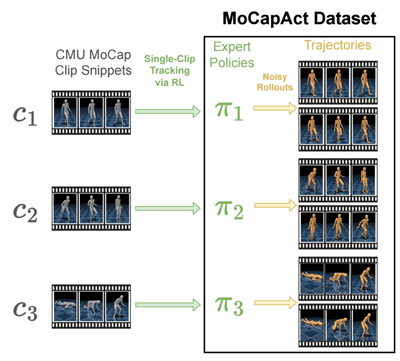
Our MoCapAct dataset, designed to be compatible with the highly popular dm_control (opens in new tab) humanoid simulation environment and the extensive CMU Motion Capture Dataset (opens in new tab), serves the research community in two ways:
- For each of over 2500 MoCap clip snippets from the CMU Motion Capture Dataset (opens in new tab), it provides an RL-trained “expert” control policy (represented as a PyTorch model) that enables dm_control (opens in new tab)’s simulated humanoid to faithfully recreate the skill depicted in that clip snippet, as shown in these videos of the experts’ behaviors:
Training this model zoo has taken the equivalent of 50 years over many GPU-equipped Azure NC6v2 (opens in new tab) virtual machines (excluding hyperparameter tuning and other required experiments) – a testament to the computational hurdle MoCapAct removes for other researchers.
- For each of the trained skill policies above, MoCapAct supplies a set of recorded trajectories generated by executing that skill’s control policy on the dm_control’s humanoid agent. These trajectories can be thought of as MoCap clips of the trained experts but, in a crucial difference from the original MoCap data, they contain both low-level sensory measurements (e.g., touch measurements) and control signals for the humanoid agent. Unlike typical MoCap data, these trajectories are suitable for learning to match and improve on skill experts via direct imitation – a much more efficient class of techniques than RL.
We give two examples of how we used the MoCapAct dataset.
First, we train a hierarchical policy based on the neural probabilistic motor primitive (opens in new tab). To achieve this, we combine the thousands of MoCapAct’s clip-specialized policies together into a single policy that is capable of executing many different skills. This agent has a high-level component that takes MoCap frames as input and outputs a learned skill. The low-level component takes the learned skill and sensory measurement from the humanoid as input and outputs the motor action.
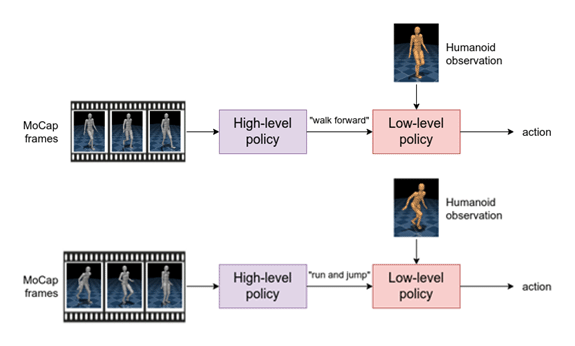
This hierarchical structure offers an appealing benefit. If we keep the low-level component, we can instead control the humanoid by inputting different skills to the low-level policy (e.g., “walk” instead of the corresponding motor actions). Therefore, we can re-use the low-level policy to efficiently learn new tasks.
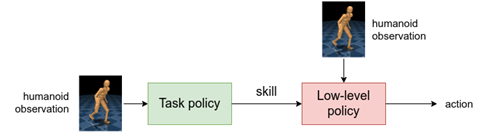
In light of that, we replace the high-level policy with a task policy that is then trained to steer the low-level policy towards achieving some task. As an example, we train a task policy to have the humanoid reach a target. Notice that the humanoid uses many low-level skills, like running, turning, and side-stepping.
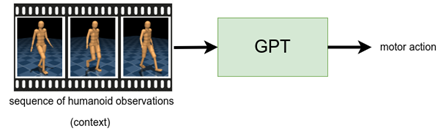
Our second example centers on motion completion, which is inspired by the task of sentence completion (opens in new tab). Here, we use the GPT architecture (opens in new tab), which accepts a sequence of sensory measurements (the “context”) and outputs a motor action. We train a control policy to take one second of sensory measurements from the dataset and output the corresponding motor actions from the specialized expert. Then, before executing the policy on our humanoid, we first generate a “prompt” (red humanoid in the videos) by executing a specialized expert for one second. Afterwards, we let the policy control the humanoid (bronze humanoid in the videos), at each time step, where it constantly takes the previous second of sensory measurements and predicts the motor actions. We find that this policy can reliably repeat the underlying motion of the clip, which is demonstrated in the first two videos. On other MoCap clips, we find that the policy can deviate from the underlying clip in a plausible way, such as in the third video, where the humanoid transitions from side-stepping to walking backwards.
On top of the dataset, we also release the code (opens in new tab) used to generate the policies and results. We hope the community can build off of our dataset and work to do incredible research in the control of humanoid robots.
Our paper is available here (opens in new tab). You can read more at our website (opens in new tab).
The data used in this project was obtained from mocap.cs.cmu.edu.
The database was created with funding from NSF EIA-0196217.





