

Large language models (LLMs) have revolutionized a wide range of tasks and applications that were previously reliant on manually crafted machine learning (ML) solutions, streamlining through automation. However, despite these advances, a notable challenge persists: the need for extensive prompt engineering to adapt these models to new tasks. New generations of language models like GPT-4 and Mixtral 8x7B advance the capability to process long input texts. This progress enables the use of longer inputs, providing richer context and detailed instructions to language models. A common technique that uses this enhanced capacity is the Retrieval Augmented Generation (RAG) approach. RAG dynamically incorporates information into the prompt based on the specific input example. This process is illustrated in Figure 1, which shows a RAG prompt designed to translate user queries into a domain-specific language (DSL), also known as semantic parsing.

The example in Figure 1 combines three distinct structures to construct the final prompt. The first structure, the task description, remains static and independent of the input as a result of conventional prompt optimization techniques. However, RAG contains two input-specific structures: the example retriever and the input text itself. These introduce numerous optimization opportunities that surpass the scope of most traditional approaches. Despite previous efforts in prompt optimization, the evolution towards more complex prompt structures has rendered many older strategies ineffective in this new context.
SAMMO: A prompt optimization approach
- Download SAMMO
To address these challenges, we developed the Structure-Aware Multi-objective Metaprompt Optimization (SAMMO) framework. SAMMO is a new open-source tool that streamlines the optimization of prompts, particularly those that combine different types of structural information like in the RAG example above. It can make structural changes, such as removing entire components or replacing them with different ones. These features enable AI practitioners and researchers to efficiently refine their prompts with little manual effort.
Central to SAMMO’s innovation is its approach to treating prompts not just as static text inputs but as dynamic, programmable entities—metaprompts. SAMMO represents these metaprompts as function graphs, where individual components and substructures can be modified to optimize performance, similar to the optimization process that occurs during traditional program compilation.
The following key features contribute to SAMMO’s effectiveness:
Structured optimization: Unlike current methods that focus on text-level changes, SAMMO focuses on optimizing the structure of metaprompts. This granular approach facilitates precise modifications and enables the straightforward integration of domain knowledge, for instance, through rewrite operations targeting specific stylistic objectives.
Multi-objective search: SAMMO’s flexibility enables it to simultaneously address multiple objectives, such as improving accuracy and computational efficiency. Our paper illustrates how SAMMO can be used to compress prompts without compromising their accuracy.
General purpose application: SAMMO has proven to deliver significant performance improvements across a variety of tasks, including instruction tuning, RAG, and prompt compression.
Spotlight: AI-POWERED EXPERIENCE

Microsoft research copilot experience
Discover more about research at Microsoft through our AI-powered experience
Exploring SAMMO’s impact through use cases
Use case 1: RAG optimization
A common application of LLMs involves translating natural user queries into domain-specific language (DSL) constructions, often to communicate with external APIs. For example, Figure 1 shows how an LLM can be used to map user queries about geography facts to a custom DSL.
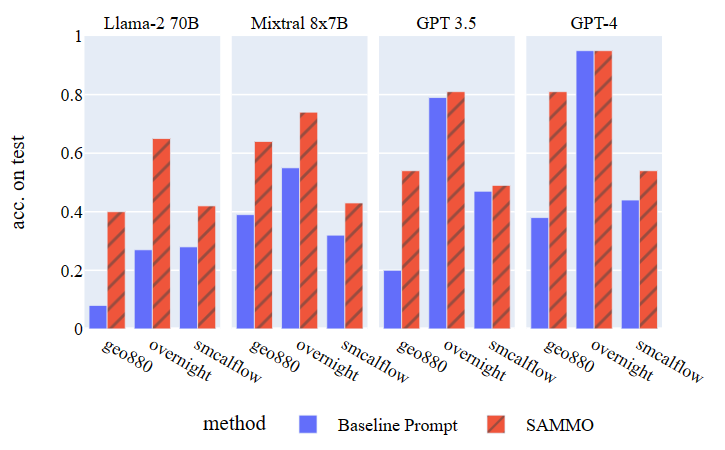
In a realistic RAG scenario, SAMMO demonstrates significant performance improvements. To demonstrate this, we conducted experiments across three semantic parsing datasets of varying complexity: GeoQuery, SMCalFlow, and Overnight. Given the often limited availability of data in practical settings, we trained and tested the model on a subsampled dataset (training and retrieval set n=600, test set n=100). We compared SAMMO against a manually designed competitive baseline, using enumerative search within a search space of 24 configurations. This included variations in data formats, the number of few-shot examples, and DSL specifications.
Evaluation
As illustrated in Figure 2, SAMMO improved accuracy across different datasets and backend LLMs in almost all cases, with the most notable gains observed in older generation models. However, even newer models like GPT-4, SAMMO facilitated accuracy improvements exceeding 100 percent.
Use case 2: Instruction tuning
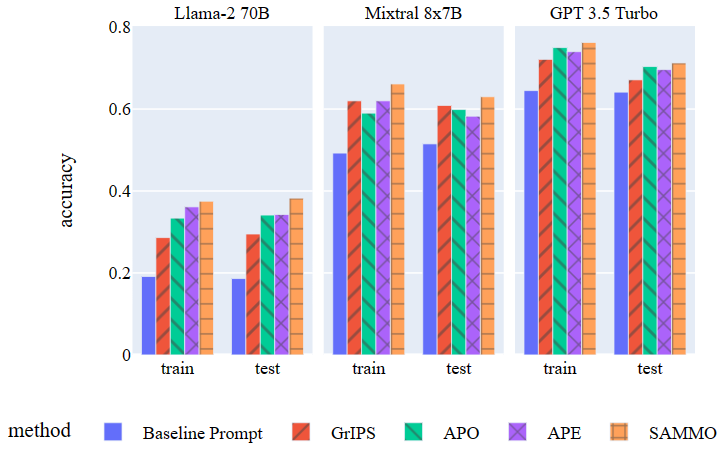
Instruction tuning addresses the optimization of static instructions given to LLMs that provide the goal and constraints of a task. To show that SAMMO extends beyond many previous prompt tuning methods, we applied this conventional setting.
To align with previous research, we used eight zero-shot BigBench classification tasks where the baseline prompt for GPT-3.5 achieved an accuracy of less than 0.9. We compared it against Automatic Prompt Optimization (APO) and GrIPS, applying open-source models Mixtral 7x8B and Llama-2 70B, alongside GPT-3.5 as backend LLMs. We did not include GPT-4 due to minimal improvement potential identified in pilot experiments. The results, shown in Figure 3, demonstrate that SAMMO outperformed all baselines regardless of the backend model, proving its effectiveness with even more complex metaprompts.
Implications and looking forward
SAMMO introduces a new and flexible approach to optimize prompts for specific requirements. Its design works with any LLM, and it features versatile components and operators suitable for a broad range of applications.
We are excited to integrate and apply SAMMO to the components and pipelines behind AI-powered assistant technologies. We also hope to establish a user-driven community centered around SAMMO, where people can exchange best practices and patterns, and encourage the expansion of the existing set of search operators.



