

Privacy Preserving Machine Learning Innovation
A holistic approach to PPML
Recent research has shown that deploying ML models can, in some cases, implicate privacy in unexpected ways. For example, pretrained public language models that are fine-tuned on private data can be misused to recover private information, and very large language models have been shown to memorize training examples, potentially encoding personally identifying information (PII). Finally, inferring that a specific user was part of the training data can also impact privacy. At Microsoft Research, we believe it’s critical to apply multiple techniques to achieve privacy and confidentiality; no single method can address all aspects alone. This is why we developed the Privacy Preserving Machine Learning (PPML) initiative to preserve the privacy and confidentiality of customer information while enabling next-generation productivity scenarios. With PPML, we take a three-pronged approach: first, we work to understand the risks and requirements around privacy and confidentiality; next, we work to measure the risks; and finally, we work to mitigate the potential for breaches of privacy. We explain the details of this multi-faceted approach below as well as in this blog post.
Understand: We work to understand the risk of customer data leakage and potential privacy attacks in a way that helps determine confidentiality properties of ML pipelines. In addition, we believe it’s critical to proactively align with policy makers. We take into account local and international laws and guidance regulating data privacy, such as the General Data Protection Regulation (opens in new tab) (GDPR) and the EU’s policy on trustworthy AI (opens in new tab). We then map these legal principles, our contractual obligations, and responsible AI principles to our technical requirements and develop tools to communicate with policy makers how we meet these requirements.
Measure: Once we understand the risks to privacy and the requirements we must adhere to, we define metrics that can quantify the identified risks and track success towards mitigating them.
Mitigate: We then develop and apply mitigation strategies, such as differential privacy (DP), described in more detail in this blog post. After we apply mitigation strategies, we measure their success and use our findings to refine our PPML approach.
Several different technologies and processes contribute to PPML, and we implement them for a number of different use cases, including threat modeling and preventing the leakage of training data. PPML strives to provide a holistic approach to unlock the full potential of customer data for intelligent features while honoring our commitment to privacy and confidentiality.

Confidential AI
Our goal is to make Azure the most trustworthy cloud platform for AI. The platform we envisage offers confidentiality and integrity against privileged attackers including attacks on the code, data and hardware supply chains, performance close to that offered by GPUs, and programmability of state-of-the-art ML frameworks.
Privacy in AI (PAI)
The M365 Research Privacy in AI group explores questions related to user privacy and confidentiality in machine learning. Our workstreams consider problems in modeling privacy threats, measuring privacy loss in AI systems, and mitigating identified risks, including applications of differential privacy, federated learning, secure multi-party computation, etc.
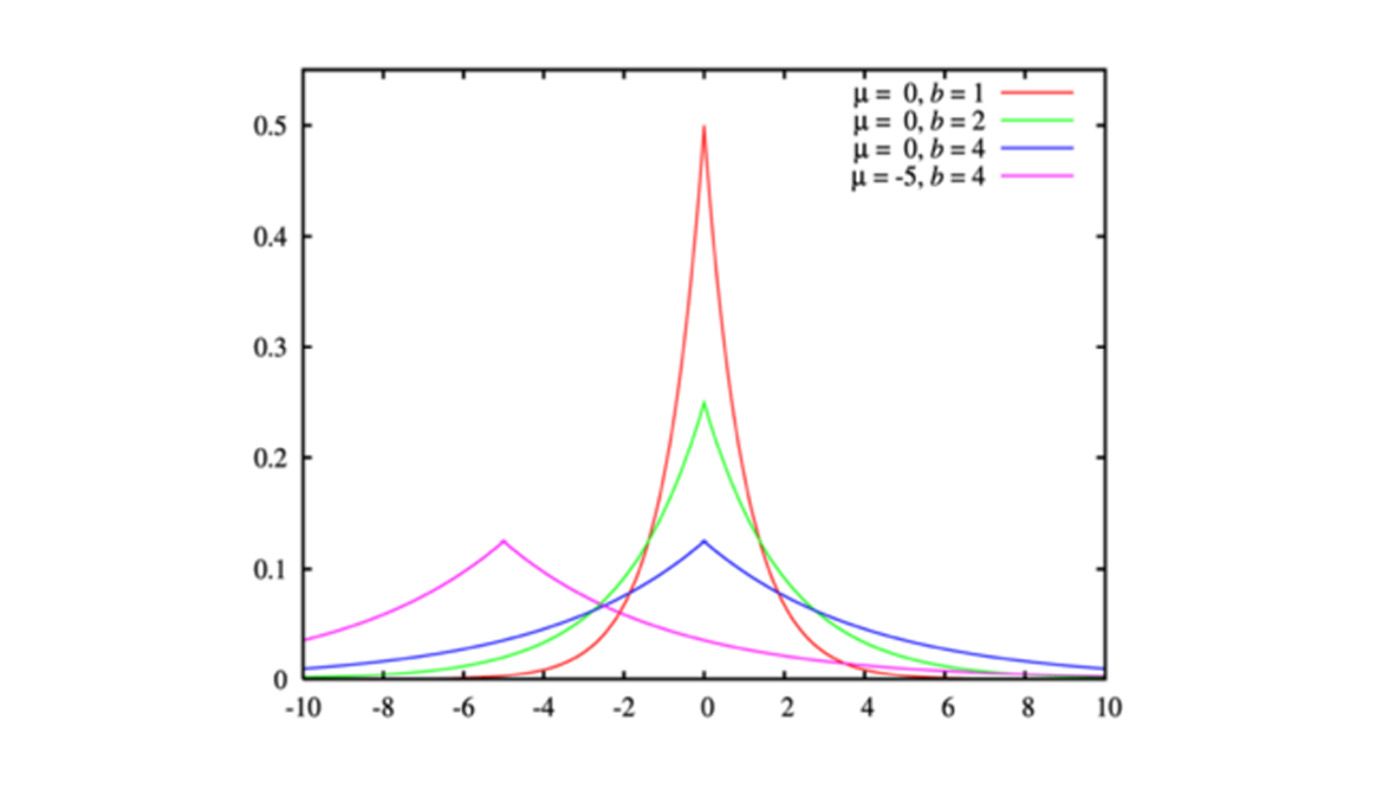
Differential Privacy: Project Laplace
Differential Privacy (DP) is the gold standard of privacy protection, with a vast body of academic literature and a growing number of large-scale deployments across the industry and the government. In machine learning scenarios DP works through adding small amounts of statistical random noise during training, the purpose of which is to conceal contributions of individual parties. When DP is employed, a mathematical proof ensures that the final ML model learns only general trends in the data without acquiring information specific to individual parties. To expand the scope of scenarios where DP can be successfully applied we push the boundaries of the state of the art in DP training algorithms to address the issues of scalability, efficiency, and privacy/utility trade-offs.
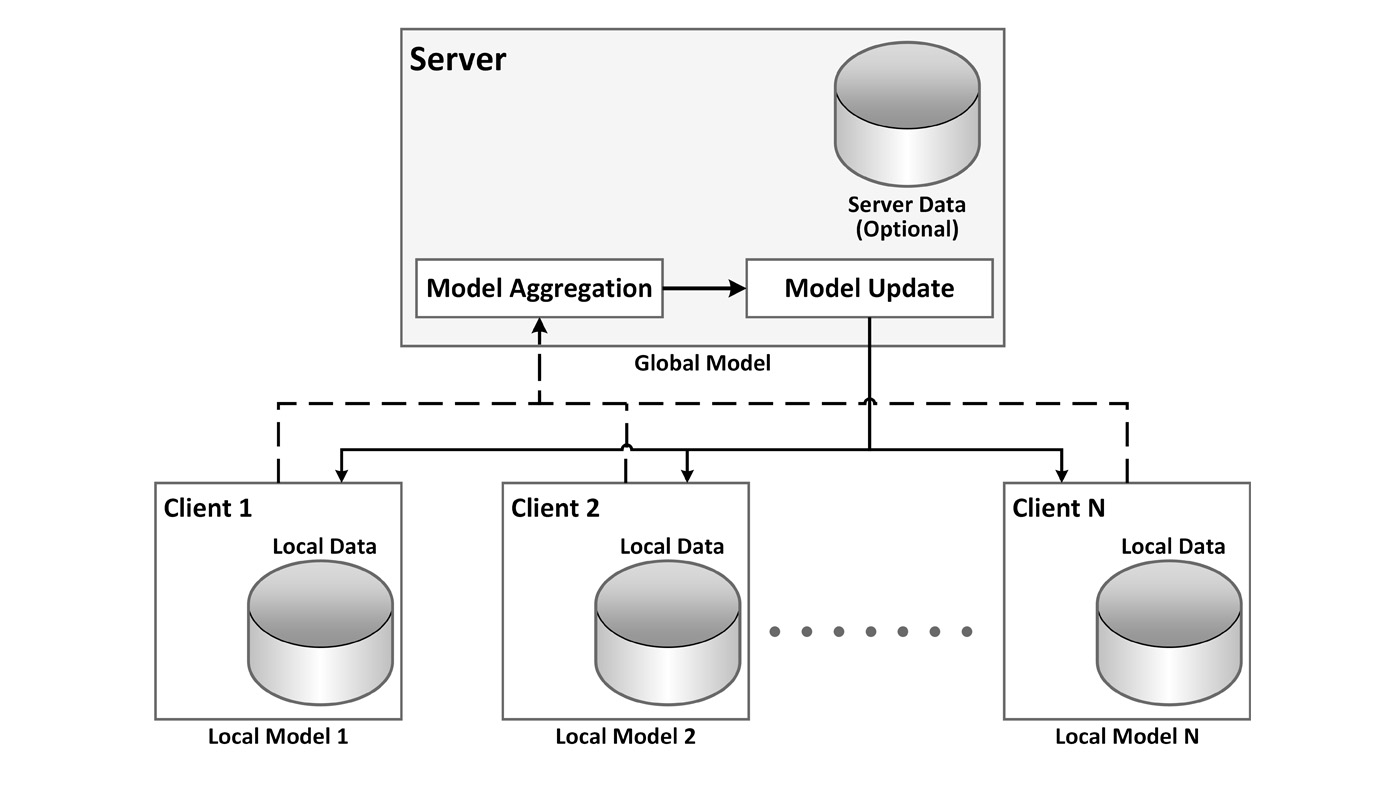
Project FLUTE
The goal of FLUTE is to create technologies that allow model training on private data without central curation. We apply techniques from federated learning, differential privacy, and high-performance computing, to enable cross-silo model training with strong experimental results. We have released FLUTE as an open-source toolkit on github (opens in new tab).
TOOLS
Privacy Random Variable (PRV) Accountant
A fast algorithm to optimally compose privacy guarantees of differentially private (DP) mechanisms to arbitrary accuracy.
DP-Transformers
Motivated by our recent work (opens in new tab), we are releasing a repository for training transformer models with differential privacy. Our GitHub (opens in new tab) repository is based on integrating the Opacus library (opens in new tab) to the Hugging Face (opens in new tab) platform. We aim to serve the privacy-preserving ML community in utilizing the state-of-the-art models while respecting the privacy of the individuals constituting what these models learn from.
Related research
EzPC (Easy Secure Multi-party Computation)
The EzPC project focuses on providing a scalable, performant, and usable system for secure Multi-Party Computation (MPC). MPC, through cryptographic protocols, allows multiple parties with sensitive information to compute joint functions on their data without sharing the data in the clear with any entity. In the context of machine learning, an example of such a task is that of secure inference—where a model owner can offer inference as a service to a data owner without either entity seeing any data in the clear. The EzPC system automatically generates MPC protocols for this task from standard TensorFlow/ONNX code.
