À propos
Dr. Lei CUI is a Principal Research Manager in Natural Language Computing (NLC) group at Microsoft Research Asia, Beijing, China. Lei joined MSR Asia in Jan 2015 after he received his Ph.D. degree from the Department of Computer Science at Harbin Institute of Technology. Lei’s research interests include Foundation Models and Multimodal AI.
Lei has been working in MSR Asia for 17 years starting from his internship in 2007. His work has contributed to several important products and research projects. He published 50+ research papers in top conferences in AI and NLP areas. Besides, he also held 20+ U.S. patents in AI and NLP areas.
Intern students I mentored:
- Shan YANG (Master student from Tsinghua University)
- Tao GE (Ph.D. student from Peking University)
- Yukun ZHAO (Master student from Shandong University)
- Chaoqun DUAN (Ph.D. student from Harbin Institute of Technology)
- Qingfu ZHU (Ph.D. student from Harbin Institute of Technology)
- Xiang DENG (Under-graduate student from University of Science and Technology of China)
- Hangbo BAO (Ph.D. student from Harbin Institute of Technology)
- Shuming MA (Master student from Peking University)
- Minghao LI (Joint Ph.D. student from Beihang University)
- Lin CHEN (Under-graduate student from Beihang University)
- Wei LIU (Master student from Beihang University)
- Tengchao LV (Master student from Peking University)
- Shengjie LUO (Under-graduate student from Beihang University)
- Yiheng XU (Under-graduate student from Harbin Institute of Technology)
- Yang XU (Ph.D. student from Harbin Institute of Technology)
- Zilong WANG (Ph.D. student from University of California, San Diego)
- Han WANG (Master student from New York University)
- Yupan HUANG (Joint Ph.D. studnet from Sun Yat-sen University)
- Junlong LI (Under-graduate student from Shanghai Jiao Tong University)
- Jingye CHEN (Ph.D. student from The Hong Kong University of Science and Technology)
- Yilin JIA (Under-graduate student from Shanghai Jiao Tong University and University of Michigan)
- Yuzhong ZHAO (Ph.D. student from University of Chinese Academy of Sciences)
S’ouvre dans un nouvel onglet
Open Source Projects

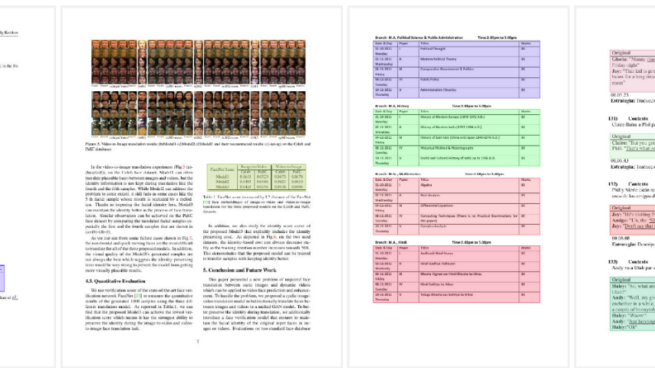
Diffusion models have gained increasing attention for their impressive generation abilities but currently struggle with rendering accurate and coherent text. To address this issue, we introduce TextDiffuser, focusing on generating images with visually appealing text that is coherent with backgrounds. TextDiffuser consists of two stages: first, a Transformer model generates the layout of keywords extracted from text prompts, and then diffusion models generate images conditioned on the text prompt and the generated layout. Additionally, we contribute the first large-scale text images dataset with OCR annotations, MARIO-10M, containing 10 million image-text pairs with text recognition, detection, and character-level segmentation annotations. We further collect the MARIO-Eval benchmark to serve as a comprehensive tool for evaluating text rendering quality. Through experiments and user studies, we show that TextDiffuser is flexible and controllable to create high-quality text images using text prompts alone or together with text template images, and conduct text inpainting to reconstruct incomplete images with text. The code, model, and dataset will be available at https://aka.ms/textdiffuser
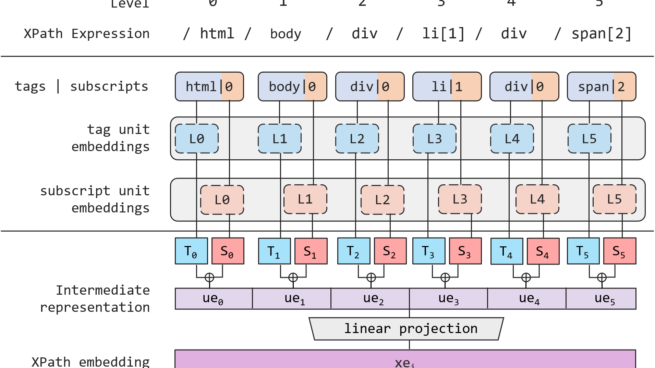
Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a large number of digital documents where the layout information is not fixed and needs to be interactively and dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding tasks.
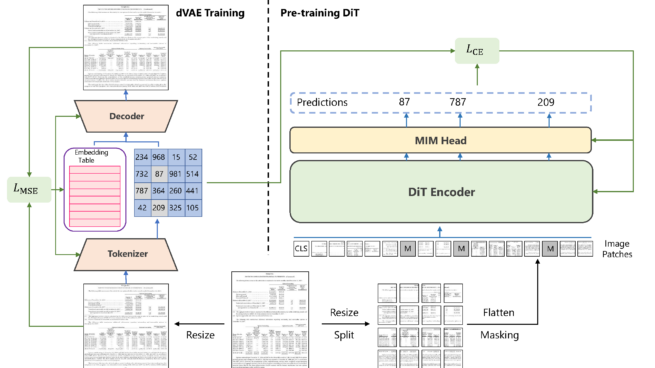
DiT is a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human-labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, as well as table detection.
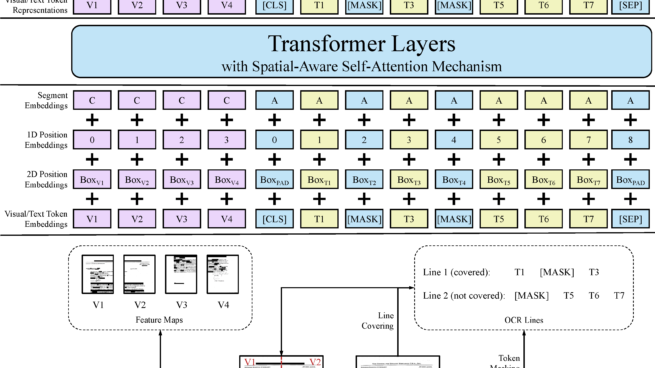
Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. In this paper, we present \textbf{LayoutLMv2} by pre-training text, layout and image in a multi-modal framework, where new model architectures and pre-training tasks are leveraged. Specifically, LayoutLMv2 not only uses the existing masked visual-language modeling task but also the new text-image alignment and text-image matching tasks in the pre-training stage, where cross-modality interaction is better learned. Meanwhile, it also integrates a spatial-aware self-attention mechanism into the Transformer architecture, so that the model can fully understand the relative positional relationship among different text blocks. Experiment results show that LayoutLMv2 outperforms strong baselines and achieves new state-of-the-art results on a wide variety of downstream visually-rich document understanding tasks, including FUNSD (0.7895 -> 0.8420), CORD (0.9493 -> 0.9601), SROIE (0.9524 -> 0.9781), Kleister-NDA (0.834 -> 0.852), RVL-CDIP (0.9443 -> 0.9564), and DocVQA (0.7295 -> 0.8672).

Pre-training techniques have been verified successfully in a variety of NLP tasks in recent years. Despite the widespread of pre-training models for NLP applications, they almost focused on text-level manipulation, while neglecting the layout and style information that is vital for document image understanding. In this paper, we propose the LayoutLM to jointly model the interaction between text and layout information across scanned document images, which is beneficial for a great number of real-world document image understanding tasks such as information extraction from scanned documents. Furthermore, we also leverage the image features to incorporate the visual information of words into LayoutLM. To the best of our knowledge, this is the first time that text and layout are jointly learned in a single framework for document-level pre-training. It achieves new state-of-the-art results in several downstream tasks, including form understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification (from 93.07 to 94.42).
We present TableBank, a new image-based table detection and recognition dataset built with novel weak supervision from Word and Latex documents on the internet. Existing research for image-based table detection and recognition usually fine-tunes pre-trained models on out-of-domain data with a few thousands human labeled examples, which is difficult to generalize on real world applications. With TableBank that contains 417K high-quality labeled tables, we build several strong baselines using state-of-the-art models with deep neural networks. We make TableBank publicly available and hope it will empower more deep learning approaches in the table detection and recognition task.