
ASL STEM Wiki
Dataset and Benchmark for Interpreting STEM Articles
ASL STEM Wiki is the first continuous ASL dataset of Science Technology Engineering and Mathematics (STEM) material. The dataset consists of 64,266 videos spanning 316 hours of content. The videos were recorded by 37 professional ASL interpreters, and are interpretations of 254 STEM-focused Wikipedia articles. Each recording corresponds to a sentence (or section title) of one of the articles. Unlike prior continuous sign language datasets, our dataset was collected with consent, recorded by trusted professional interpreters including Certified Deaf Interpreters, and focuses on STEM content.
| Dataset | Source & Topic | Signers | Consent? | # Hours |
| How2Sign (Duarte et al., 2021) | «How-to» YouTube | Interpreter | Yes | 80 |
| OpenASL (Shi et al., 2022) | Deaf YouTube | Deaf & Interpreter | No | 268 |
| YouTube-ASL (Uthus et al., 2023) | YouTube | Unknown | No | 984 |
| ASL STEM Wiki | STEM Wikipedia | Interpreter | Yes | 316 |
The interpreted texts consist of 254 STEM-focused Wikipedia articles. These articles fall under the following topic categories: Science (113 articles), Geography (50), Technology (47), Mathematics (26), and Medicine (18). The articles have been segmented into sentences. Each sentence is aligned with the interpretation of that sentence or section title. Article categories, sentence indexing, video alignment, and other article metadata are included in the dataset.
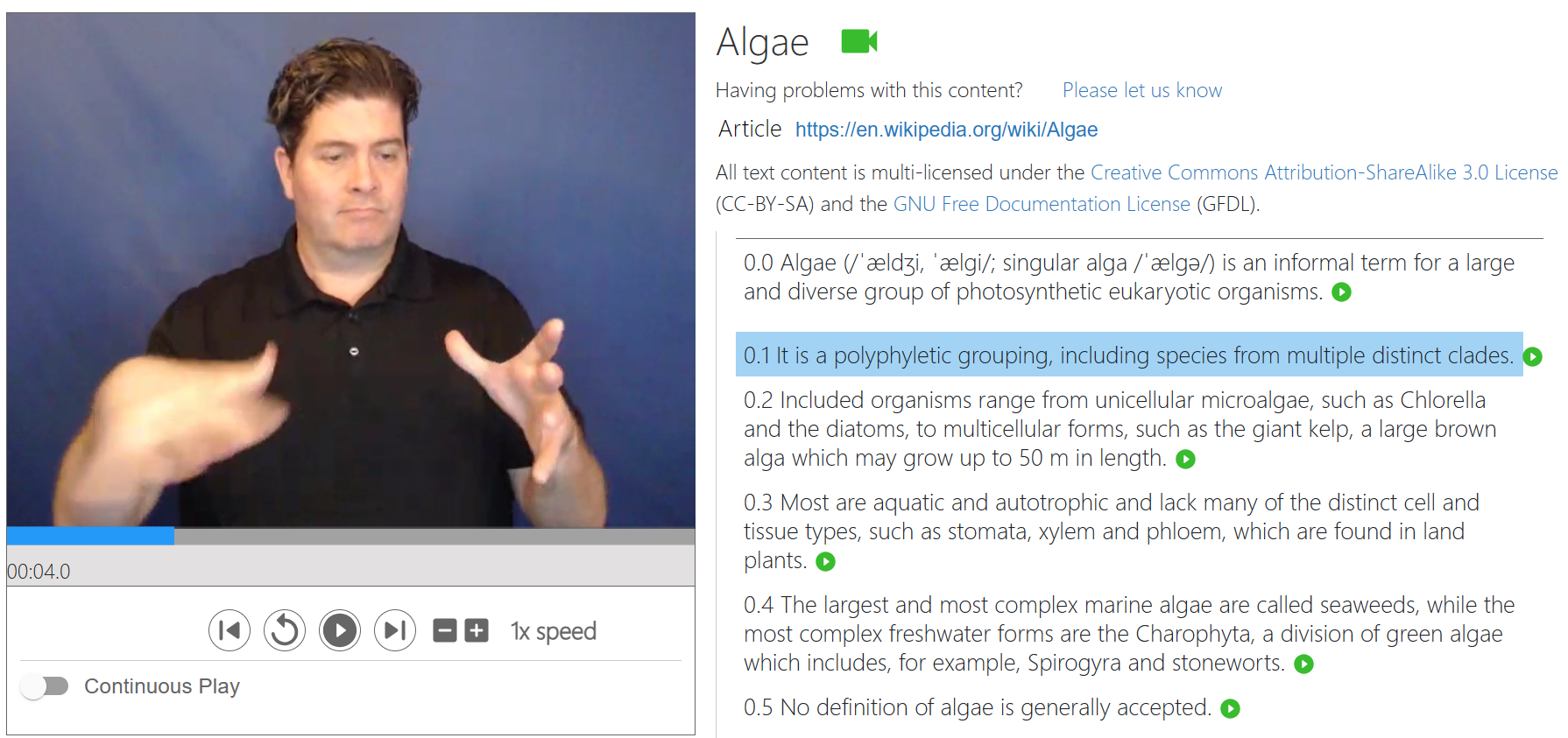
The texts were interpreted into ASL using a custom web interface, first proposed in prior work (opens in new tab), which displays English articles and interpretations side-by-side. People recording interpretations simultaneously contribute to two purposes: 1) the collection of a continuous dataset to help advance research, and 2) the creation of a new bilingual resource that students and others can use to access articles in both English and ASL. We release the new resource powered by the ASL STEM Wiki recordings (see the «Bilingual Resource» tab). While contributing, the interpreters could play back recordings, and re-record as desired. The research team validated the collected videos by removing invalid recordings, manually reviewing a random sample of videos from each contributor, and manually examining length outliers.

The resulting video dataset consists of 64,266 ASL videos, providing 316 hours of continuous STEM content. Because the videos were recorded by professional interpreters, they include plain backgrounds, and the interpreters typically wear plain-colored contrastive clothing to help with visual clarity. Because the interpreted contents are technical and focused on STEM, a large number of words are fingerspelled, estimated to be around 18.6% of words in our corpus.