

On-device ML for Object and Activity Detection
Établi : January 8, 2015

Summary
Ambient-aware systems are omnipresent in drones, self-driving cars, body-worn cameras and AR-VR devices. These systems process environmental data to recognize objects, measure physical parameters and determine what actions to take. Intelligent cameras and microphones are key sensors that enable ambient-aware applications. For a good user experience, it is important that these sensors remain always-on and always-connected. Thus, they need to collect, transmit and process data with low latency and minimal power consumption. Simple approaches that sample and stream signals constantly to the cloud for processing are unacceptable. One problem that we have considered in this project is to efficiently map machine-learning algorithms onto edge devices and optimize their communication mechanism so that they can support always-on, always-connected computer vision for ambient-aware applications.
Project Overview
Fundamentally, ambient-aware applications rely on a multi-tiered sensing architecture, (opens in new tab) where data processing is split between the cloud and device. An efficient arbitration between these resources is the key to achieving performance with low-latency and low-power consumption. For instance, consider the local frame-filtering approach illustrated in the figure below. Only transmitting selected video frames after light-weight on-device processing can lower communication energies substantially. This in-turn leads to increased battery times on the device (8.8 hrs. with local processing vs. 96 minutes without). Thus, in order to achieve a seamless ambient-aware experience, it is important to communicate as well as compute efficiently on the local device.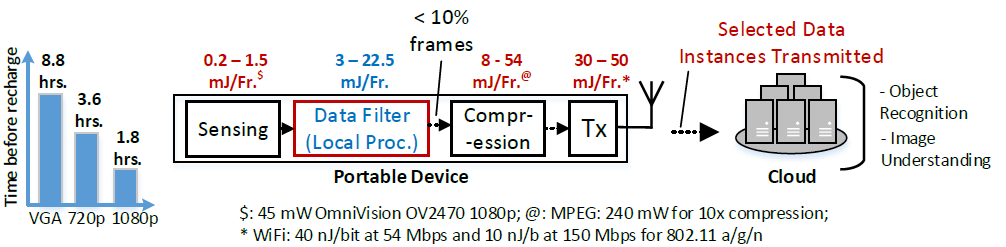
In this project, we aim to address both of these issues. We have developed efficient implementations of ML algorithms so that they can be mapped to resource-constrained devices. We have also streamlined remote communications by relying on long-range radios and optimally-biased ML classifiers.
Project Details
To process data locally, we have accelerated ML computations via ASICs that incorporate efficient pipelining and parallelism techniques. We have also compressed ML models by scaling their bit-precision values. To lower communication overheads, we have looked at cascading ML algorithms through the network. We have also developed prediction models that lower contact frequency with the cloud. Our first candidate computing task for optimization has been object detection in video data for ambient-awareness.
Efficient Local Computations
We have addressed the local computation issue via two approaches: architectural and algorithmic. In the architectural approach, we have developed efficient classification algorithms that rely on simple features obtained from video frames. In the algorithmic approach, we have explored different ways of compressing ML algorithms and adjusting their classification behavior at run time.
Architectural approaches: We have considered the problem of image classification, which is a fundamental building block in ambient-aware applications. Our on-device classification accelerator comprises feature-extraction and classification. The figure below is a block diagram of our feature extractor. It utilizes a proprietary systolic-array engine (opens in new tab) and flexible interest-point detection algorithm (opens in new tab). We have developed hardware IP and tested it in a 45 nm SOI process to achieve 37x speed up over CPU computations. Through various techniques, we have been able to lower the power consumption of this IP block to a mere 62.7 mW.
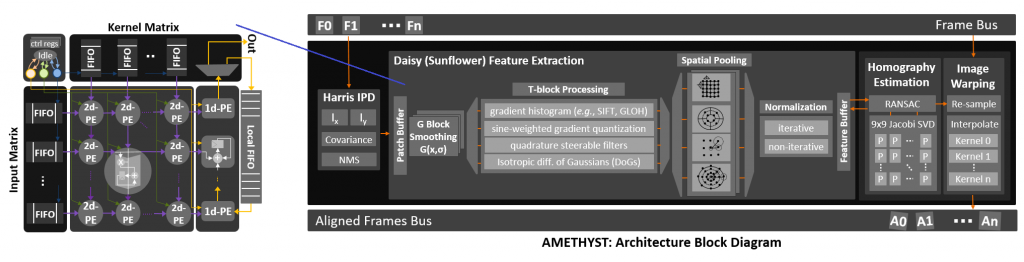
Our feature-extraction core has the ability to process many video frames per second. Beyond image classification, its potential lies in multi-frame processing (MFP). Thus, our IP core has found its way into the Windows Phone camera-processing pipeline. It has proven useful for several MFP applications like real-time HDR imaging, panorama creation, de-noising, de-hazing and de-blurring. Our feature-extraction module is extensively configurable to achieve multiple levels of data parallelism and interleaving through systolic arrays. It also supports 2-level vector reduction operations depending on application demands. Compared to other platforms, the performance of this engine was better in terms of both energy efficiency and run time (see figure below). We are continuing to evangelize this technology (esp. the hardware sub-systems) with Azure and HoloLens product teams to accelerate structured ML algorithms like neural-networks.
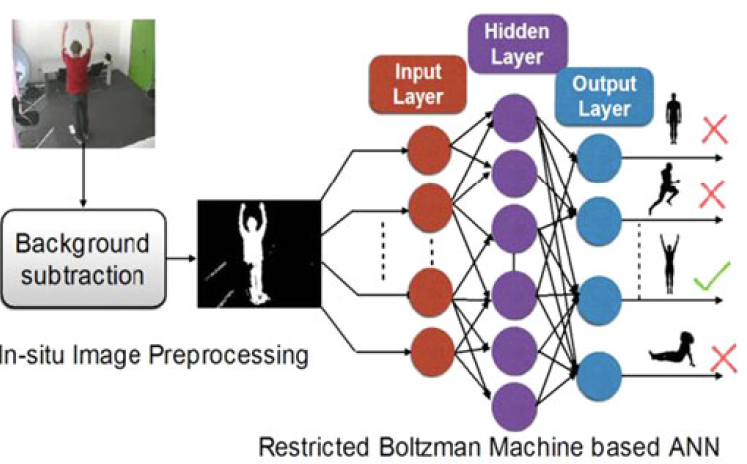
Furthermore, we have augmented our feature-extraction core with light-weight classifiers like those based on Fisher Vectors to achieve minimum-energy operation at a frame rate of 12 fps, while consuming a mere 3 mJ of energy per frame. Using a prototype system, we have estimated 70% reduction in communication energy when 5% of frames are interesting in a video stream. See our DATE 15 (opens in new tab) paper for more details. We have also looked at efficiently implementing other classifiers like RBMs on FPGAs (see adjacent figure). Thus, by exploiting the parallelism and computational-scaling properties of neural networks in hardware, we have demonstrated image classification with very low power. Our work is summarized in papers published at ISLPED 15 (opens in new tab) and TMSCS 16 (opens in new tab). Our hardware system prototypes have also motivated specs for emerging intelligent cameras.
Algorithmic approaches: In 2016, we joined forces with a team of researchers (opens in new tab) to make inference algorithms efficient so that they can be mapped to embedded devices. This bigger effort brought together several groups at Microsoft to work on related technologies. As part of this project, we have specifically explored bit-precision scaling in deep neural networks for ambient-aware computing tasks like image classification, object detection and audio processing. Owing to several issues, we have found that practical implementations of binarized neural-networks, such as those described in the literature (opens in new tab), do not necessarily provide the promised 64x speed ups (see figure). Thus, one outcome of our work has been the efficient implementation of XNOR nets (binary equivalent of algorithms) on CPUs by utilizing CNTK-bsaed ML tools from Microsoft.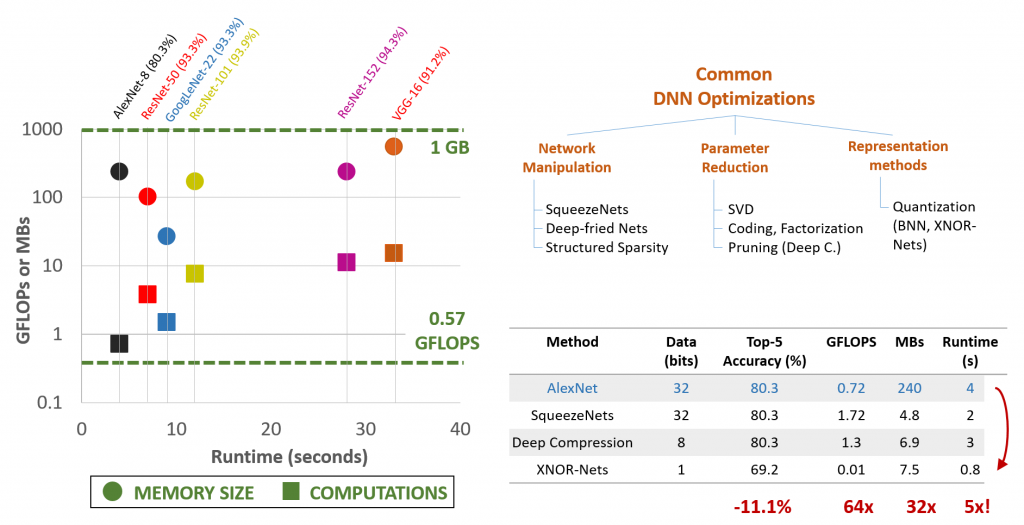
Efficient Communication
We have addressed communication issues in ambient-aware applications via two techniques: utilizing low-energy networking technologies and tweaking the performance of ML algorithms.
Serving clients on low-bandwidth radios: ML on the edge sounds great. But, once a trigger has been initiated, what is the best way for edge devices to communicate with the cloud? We have taken the first steps to answer this question. Specifically, we have spent time and resources studying low-power wide-area network (LPWAN) technologies. Today cellular communication is the most viable technology for ambient-aware computing, however it faces a number of short comings: (1) signal overheads are huge and single message transmissions require 7-8 packet exchanges, (2) cellular chips are overly complex and are not optimized for ambient-aware computing, and (3) cost of messages are not set up for variable data rates. While investments in LTE-M promise to overcome some of the limitations, the technology is in it infancy as it requires over 85% reduction in modem complexity for practical use. Thus, low cost, proprietary networks such as RPMA, DSSS, mesh networking, narrow band and LoRa are emerging as suitable candidates for ambient-ware computing applications.

We have explored the use of some of these techniques to enable ultra low-power, long range communication. One key shortcoming of these wireless technologies is scale. Due to the limited bandwidth, these networks can only support a small number of devices. As part of this project, we have developed constant-velocity prediction models that allow us to lower sampling rates by 33% for the same error tolerance limit and transmission range of 100 m. For low data rates, we have developed techniques that allow us to scale from 100 devices to 150 devices at a single base station. We are continuing to optimize these protocols and are investigating other emerging ones to enable long range, higher data rate communication necessary for ambient-aware computing applications.
Trading ML precision for bandwidth savings: As discussed before, an important part of any ambient-aware application front end is a low-complexity image classifier. Such a classifier helps filter out unnecessary frames before transmission to the cloud. We have identified that our local-processing algorithm should balance precision with recall so as to maximize energy consumption. It is not obvious which metric to maximize since it depends on the conditions of the network and the associated computational costs. In our DAC 15 paper (opens in new tab), we have shown how to achieve a balance between precision and recall for arbitrary classifiers. Our approach was based on sample weighting and cascaded classification to manipulate the decision boundary of classifiers. Given this and other emerging approaches, we were able to exploit on-device classification efficiently within a connected network.

The precision-recall trade off is explained further as follows (see figure above). We biased a traditional set of classification algorithms B such that they led us to a new «lower-energy» alternative set B*, which had a high true positive rate (potentially close to that provided by a high-energy, high-accuracy set A) at the cost of a higher false positive rate than B (and A). We have thus demonstrated how to achieve energy-scalability at the highest level of performance in ambient-aware systems. For more details, see our DAC 15 (opens in new tab) and MCVMC 15 (opens in new tab) papers.
Going Forward
Ambient-aware systems constitute a specific class of IoT devices. They form vehicles for technologies like AR, VR, and autonomous agents. In this project, we have developed several building blocks and prototypes that show the benefits of always-on, always-connected intelligent cameras. We believe these are the first steps towards achieving true ambient-aware computing. Information from multiple sensor modalities has to come together for a practically-useful system. This includes data from other environmental and IoT sensors. Furthermore, there are issues of optics, audio-video algorithms, artificial intelligence and user experiences that need to be addressed. As we move along, we hope to forge collaborative efforts that target these other issues of the ambient-computing puzzle.
-
Joint work of our bigger research team on lean machine learning has gained attention in popular media.
- Digital Trends: Microsoft manages to cram artificial intelligence on the Raspberry Pi 3 PC board (opens in new tab)
- ZDNet: Microsoft wants to bring AI to Raspberry Pi and other tiny devices (opens in new tab)
- Mashable: Microsoft squeezed AI onto a Raspberry Pi (opens in new tab)
- Engadget: Microsoft made its AI work on a $10 Raspberry Pi (opens in new tab)
- Element14: Artificial Intelligence Gets Ported Over to the Raspberry Pi with Latest Microsoft Advancement (opens in new tab)
Personne
Matthai Philipose
Senior Principal Researcher
Bodhi Priyantha
Researcher