
We are inundated with data. Resources to analyze the data are finite and expensive. Approximate answers allow us to explore much larger amounts of data than otherwise possible given available resources. Reducing the cost, if doable for a large fraction of the complex queries that run on this data, is of strategic importance because the savings can be re-invested into more sophisticated algorithms or be used as a key differentiator for analytics-as-a-service offerings.
Unfortunately, state-of-art techniques cannot approximate complex queries. Most production bigdata systems offer the uniform sample operator. The user can sample as desired. But the systems do not reason about how the answer will change. A rich vein of prior research builds samples over input datasets. They deliver benefit to predictable queries that touch only one large dataset. Joins with small dimension tables are okay. However, they cannot help queries that join more than one large table, queries that touch less frequently used datasets or query sets that use a diverse set of columns. Such queries and datasets dominate in bigdata clusters. On the TPC-DS benchmark, our experiments show that when given 1x (4x) the size of the input to store samples, a state-of-the-art apriori sampling technique, BlinkDB, offers benefit for 11% (17%) of the queries.
Despite statistical sampling being well-understood, there have been no real breakthroughs in offering approximate answers for complex ad-hoc queries. We break new ground in research on this topic: (1) we have discovered new samplers that effectively sample join inputs; (2) by treating samplers as native operators in a query optimizer, we show that one can cover a substantial fraction of complex queries without pre-constructed samples; and (3) we extend the state-of-art in reasoning about the accuracy of sampled plans.
Zero-touch approximation has been a Holy Grail problem. Achieving it for a large subset of U-SQL (SQL + user-defined operators) is a narrow waist for disruption since any query expressible in U-SQL can then be automatically approximated.

State-of-the-art: Apriori or Input Sampling.
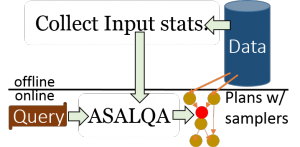
Quickr: Inline samplers injected by the query optimizer.
Personne
Surajit Chaudhuri
Technical Fellow, Data Platforms and Analytics
Kukjin Lee
Principal Research Software Design Engineer