

VALL-E
A neural codec language model for speech synthesis
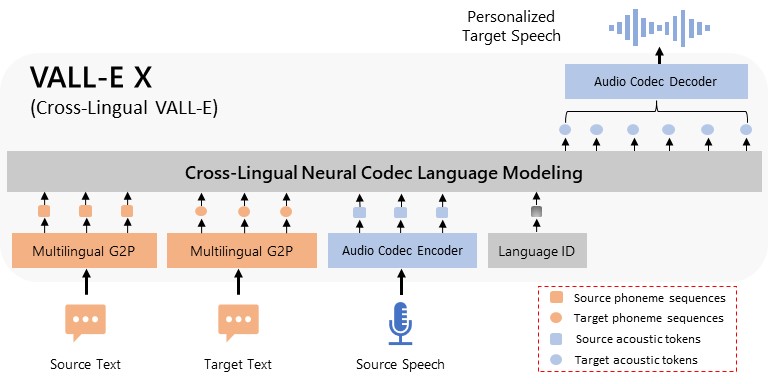
We extend VALL-E to a cross-lingual neural codec language model, VALL-E X, for cross-lingual speech synthesis, and train a multi-lingual conditional codec language model to predict the acoustic token sequences of the target language speech by using both the source language speech and the target language text as prompts. VALL-E X inherits strong in-context learning capabilities and can be applied for zero-shot cross-lingual text-to-speech synthesis and zero-shot speech-to-speech translation tasks. Experimental results show that it can generate high-quality speech in the target language via just one speech utterance in the source language as a prompt while preserving the unseen speaker’s voice, emotion, and acoustic environment. Moreover, VALL-E X effectively alleviates foreign accent problems, which can be controlled by a language ID.
This page is for research demonstration purposes only.
Model Overview
VALL-E X can synthesize personalized speech in another language for a monolingual speaker. Taking the phoneme sequences derived from the source and target text, and the source acoustic tokens derived from an audio codec model as prompts, VALL-E X is able to produce the acoustic tokens in the target language, which can be then decompressed to the target speech waveform. Thanks to its powerful in-context learning capabilities, VALL-E X does not require cross-lingual speech data of the same speakers for training and can perform various zero-shot cross-lingual speech generation tasks, such as cross-lingual text-to-speech synthesis and speech-to-speech translation.
Zero-shot cross-lingual text to speech
-
English Text Chinese Speaker Prompt Baseline VALL-E X Look a little closer while our guide lets the light of his lamp fall upon the black wall at your side. He honours whatever he recognizes in himself, such morality equals self-glorification. One dark night at the head of a score of his tribe, he fell upon Wabigoon’s camp, his object being the abduction of the princess. There could be little art in this last and final round of fencing. It’s the first time Hilda has been to our house and Tom introduces her around. It was youth and poverty and proximity and everything was young and kindly. -
Chinese Text English Speaker Prompt VALL-E X 坚持房地产调控政策不动摇。 值得关注的是从二零一零年到二零一四年。 两千六百四十八万二千五百四十六。 汇聚部分全球领先品牌的下一代技术创新。 商品房销售情况也传递出了更多暖意。 最低首付款比例为百分之一。
Zero-shot speech-to-speech translation
-
Chinese Speech English Ground Truth Baseline VALL-E X Trans -
English Speech Chinese Ground Truth VALL-E X Trans -
Chinese Text Chinese Speech Baseline VALL-E X Trans 我们就坐在他的位于半山坡的办公室里。 是巴西女选手在热身泳道中违规使用脚扑影响他人。 更在于这项运动本身具有着极其丰富的精神内涵。 美国并没有统一的全国高中联赛。 本市还要打造慈善捐赠事业的阳光工程。 达茜兮会称呼我为瓦齐里先生。 -
English Text English Speech VALL-E X Trans His instant of panic was followed by a small sharp blow high on his chest. The last two days of the voyage Bartley found almost intolerable. She merely brushed his cheek with her lips and put a hand lightly and joyously on either shoulder. But in this awful moment of the danger of the church. their vow was superseded by a more sublime and indispensable duty. We’ve lost the key of the cellar and there’s nothing out except water and i don’t think you’d care for that. He had been late he had offered no excuse no explanation.
Foreign accent control
-
English Speech (Prompt) Chinese Speech (Ground Truth) VALL-E X with English LID VALL-E X with Chinese LID -
Chinese Speech (Prompt) English Speech (Ground Truth) VALL-E X with English LID VALL-E X with Chinese LID
Voice emotion maintenance
-
VALL-E X Trans can synthesize personalized target speech while maintaining the emotion in the source speech. The source audio are sampled from the Emotional Voices Database EmoV-DB.
Emotion English Speech VALL-E X Trans Neutral Amused Sleepiness Anger Disgust
Code-switch speech synthesis
-
Code-Switch Text Prompts VALL-E X 播放歌曲 BEST FRIEND。 我想去travel一下,放松一下自己。 他是一个funny的人,总是讲笑话。 这个restaurant很有名,很多人都来吃。 这个pizza很好吃,你要不要try一下。
Ethics Statement
VALL-E X could synthesize speech that maintains speaker identity and could be used for educational learning, entertainment, journalistic, self-authored content, accessibility features, interactive voice response systems, translation, chatbot, and so on. While VALL-E X can speak in a voice like the voice talent, the similarity, and naturalness depend on the length and quality of the speech prompt, the background noise, as well as other factors. It may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agrees to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model. If you suspect that VALL-E X is being used in a manner that is abusive or illegal or infringes on your rights or the rights of other people, you can report it at the Report Abuse Portal.