
Masintõlge
Mis on Masintõlge?
Masintõlke süsteemid on rakendused või võrguteenused, mis kasutavad masinõppe tehnoloogiaid, et tõlkida suurel hulgal teksti ja nende toetatud keeli. Teenus tõlgib "allikas" teksti ühest keelest teise "Target" keel.
Kuigi masintõlke tehnoloogia ja selle kasutamise liidesed on suhteliselt lihtsad, on selle taga olevad teaduslikud ja tehnoloogiad äärmiselt keerulised ja toovad kokku mitu tipptasemel tehnoloogiat, eriti sügavaid õppevõimalusi ( Tehisintellekt), suured andmed, lingvistika, pilvandmetöötlus ja veebi API-d.
Alates 2010s, uus tehisintellekti tehnoloogia, sügav närvivõrgud (aka sügav õppimine), on võimaldanud tehnoloogia kõnetuvastus jõuda kvaliteeditaseme, mis võimaldas Microsoft Translator meeskond ühendada kõnetuvastuse oma tõlketehnoloogiat, et käivitada uus kõnevahetuse tehnoloogia.
Ajalooliselt oli tööstuses kasutatav esmane masinõppe tehnika statistiline Masintõlge (SMT). SMT kasutab täiustatud statistilist analüüsi, et hinnata parimate võimalike tõlgete sõnastust, arvestades mõne sõna konteksti. SMT-d on kasutatud alates 2000de keskpaigast kõigi suuremate tõlketeenuste pakkujate, sealhulgas Microsofti poolt.
Neural masin Translation (NMT) tulekuga põhjustas radikaalse vahetuse tõlketehnoloogias, mille tulemuseks oli palju kõrgema kvaliteediga tõlked. See Tõlketehnoloogia alustas kasutajate ja arendajate juurutamist Viimane osa 2016.
Nii SMT kui ka NMT tõlketehnoloogiatel on kaks ühist elementi:
- Mõlemad nõuavad süsteemide treenima suurel hulgal eel-inimese tõlgitud sisu (kuni miljoneid tõlgitud lauseid).
- Kumbki ei tegutse kakskeelsete sõnastikena, tõlgete sõnade põhjal potentsiaalsete tõlgetega, vaid tõlgitakse sõna konteksti alusel, mida kasutatakse lauses.
Mis on tõlkija?
Tõlkija ja kõneteenused, osa Kognitiivsed teenused API-de kogum, on Microsofti masintõlke teenused.
Teksti tõlge
Microsofti rühmad kasutavad tõlkijat alates 2007. aastast ja on klientidele API-na saadaval alates 2011. aastast. Tõlkijat kasutatakse Microsoftis laialdaselt. See on kaasatud toodete lokaliseerimise, toe ja võrgusuhtluse meeskondadesse. Samale teenusele pääseb tasuta juurde ka tuttavatest Microsofti toodetest, näiteks Bing, Cortana, Microsoft Edge, Office, Sharepointi, Skype'ija Yammeri.
Tõlkijat saab kasutada veebis või klientrakenduses igas riistvaraplatis ja mis tahes operatsioonisüsteemiga, et teha keeletõlkeid ja muid keelega seotud toiminguid, nagu keele tuvastamine, tekst kõneks või sõnastik.
Võimendab tööstuse Standard REST tehnoloogia, arendaja saadab lähteteksti (või audio kõne tõlge) teenuse koos parameetriga, mis näitab Target keel ja teenus saadab tagasi tõlgitud teksti kliendi või veebirakendus kasutada.
Tõlkija teenus on Azure ' i teenus majutatud Microsofti andmekeskuste ja kasu turvalisuse, skaleeritavus, töökindluse ja nonstop kättesaadavus, et muud Microsofti pilve teenuseid ka saada.
Kõne tõlkimine
Tõlkija kõnetõlke tehnoloogia käivitati 2014. aasta lõpus alates Skype Translatorist ja on klientidele avatud API alates 2016. aasta algusest. See on integreeritud Microsoft Translatori reaalajas funktsiooni, Skype'i, Skype'i koosoleku leviedastuse ning Androidi ja iOS-i jaoks mõeldud Microsoft Translatori rakendustesse.
Kõnetõlge on nüüd saadaval Microsoft Speech, lõplikult kohandatav teenused Kõnetuvastus, kõne tõlge ja kõne süntees (tekst kõneks).
Kuidas teksttõlge töötab?
On kaks peamist tehnoloogiat kasutatakse teksti tõlkimine: pärand üks, statistiline masin Translation (SMT) ja uuema põlvkonna üks, Neural Machine tõlkimine (NMT).
Statistiline Masintõlge
Tõlkija rakendamise statistiline masin tõlkimine (SMT) on ehitatud rohkem kui kümme aastat looduslike keeleteadus Microsoft. Selle asemel, et kirjutada käsitsi formuleeritud reeglid tõlkida keelte, kaasaegne tõlkesüsteemide lähenemine tõlge on probleem õppimise ümberkujundamise keelte vahel olemasolevate inimeste tõlked ja võimendades hiljutist arengut rakendatud statistika ja masinõppe.
Niinimetatud "paralleelne Kapra" tegutseb kaasaegse Rosetta kivi massiivsetes proportsioonides, pakkudes sõna, fraasi ja idiomatlikke tõlkeid konteksti paljudes keelepaarides ja domeenides. Statistilise modelleerimise tehnikad ja tõhusad algoritmid aitavad arvutil lahendada deformatsimisprobleemi (Avastades koolitusandmetes allika ja sihtkeele vahelisi vastavusi) ja dekodeerimist (uue sisendlause parima tõlke leidmine). Tõlkija ühendab statistiliste meetodite võimu keelelise teabega, et toota mudeleid, mis generaliseerivad paremini ja toovad kaasa arusaadavamaks tõlked.
Kuna see lähenemine, mis ei sõltu sõnastikke või grammatilised reeglid, see annab parima tõlked fraasid, kus ta saab kasutada konteksti ümber teatud sõna versus üritab sooritada ühe sõna tõlked. Ühe sõna tõlkimiseks töötati välja kakskeelne sõnastik ja see on kättesaadav www.Bing.com/Translator.
Neuromasintõlke
Tõlke pidev paranemine on oluline. Kuid jõudluse parandusi on kõrgena SMT tehnoloogia alates keskel 2010s. Võimendades skaala ja võimu Microsofti AI superarvuti, konkreetselt Microsofti kognitiivse tööriistakomplekt, tõlkija nüüd pakub närvivõrgu (LSTM) põhinev tõlge, mis võimaldab uue kümnendi tõlkekvaliteedi parandamist.
Need närvivõrgu mudelid on saadaval kõigi kõnekeelte kaudu kõneteenuse Azure ' i kaudu ja teksti API kaudu "generalnn" kategooria ID abil.
Närvivõrgu tõlked erinevad oluliselt sellest, kuidas neid teostatakse võrreldes traditsiooniliste SMT-idega.
Järgmine animatsioon kujutab erinevaid samme närvivõrgu tõlked läbida lause tõlkida. Kuna see lähenemine, tõlge võtab arvesse kogu lause, võrreldes ainult paar sõna libistades aken, et SMT tehnoloogia kasutab ja toodab rohkem vedelikku ja inimese tõlgitud otsin tõlked.
Vastavalt neurovõrgu koolitusele on iga sõna kodeeritud 500-mõõtmete vektori kaudu (a), mis esindavad selle unikaalseid omadusi konkreetses keelepaaris (nt inglise ja Hiina keeles). Keelepaaride alusel, mida kasutatakse treenides, määrab närvivõrk ise kindlaks, millised need mõõtmed peaksid olema. Nad võivad kodeerivaid lihtsaid kontseptsioone nagu sugu (naiselik, meheline, neutraalne), viisakusaste (slang, juhuslik, kirjalik, formaalne jne), sõna tüüp (verb, nimisõna jne), kuid ka muud mitteilmsed omadused, mis on saadud koolitusandmetest.
Sammud närvivõrgu tõlked läbida on järgmised:
- Iga sõna või täpsemalt 500-dimensiooni vektor, mis esindab seda, läbib esimese kihi "neuronid", mis kodeerimiseks see 1000-dimensiooni vektor (b) esindab sõna kontekstis teiste sõnadega lauses.
- Kui kõik sõnad on kodeeritud üks kord neid 1000-dimensiooni vektorid, protsessi korratakse mitu korda, iga kiht, mis võimaldab paremat peenhäälestus selle 1000-mõõtme kujutis sõna kontekstis täieliku lause (vastupidiselt SMT tehnoloogiat, mis võib võtta arvesse ainult 3 – 5 sõna akent)
- Lõppväljundi maatriksit kasutab seejärel tähelepanu kiht (st tarkvara algoritm), mis kasutab nii selle lõppväljundi maatriksit kui ka varem tõlgitud sõnade väljundit, et määratleda, milline sõna lähtelausega tuleks järgmisena tõlkida. Samuti kasutatakse neid arvutusi tarbetute sõnade potentsiaalselt kukutades sihtkeeles.
- Dekoodri (tõlke) kiht tõlgib valitud sõna (või täpsemalt 1000-dimensiooni vektor, mis esindab seda sõna täieliku lause kontekstis) kõige sobivam sihtkeele ekvivalent. Selle viimase kihi (c) väljund juhitakse seejärel tagasi tähelepanu kihile, et arvutada, milline järgmine sõna lähtelauses tuleks tõlkida.

Animatsiooniga kujutatud näites on kontekstiteadlik 1000-dimensiooni mudel "et"kodeb, et nimisõna (House) on naiselik sõna prantsuse keeles (La Maison). See võimaldab sobivat tõlget "et"olla"La"ja mitte"Le"(ainsus, isane) või"Les"(mitmuses), kui see jõuab dekoodri (tõlke) kihiga.
Tähelepanu algoritm arvutatakse ka eelnevalt tõlgitud sõna (de) alusel (antud juhul "et"), et järgmisena tõlgitakse järgmine sõna ("House"), mitte omadussõna ("Sinine"). Seda saab saavutada, sest süsteem sai selgeks, et inglise ja prantsuse keele ümberpööramine on nende sõnade järjestus. See oleks ka arvutanud, et kui omadussõna oleks "Suur"värvi asemel, et see ei tohiks neid ümber pöörata ("suur maja"= >"La Grande Maison").
Tänu sellele lähenemisele on lõppväljund enamikul juhtudel rohkem sõnakuullikum ja lähemal inimese tõlkele, kui SMT-põhine tõlge oleks võinud kunagi olla.
Kuidas kõnetõlge töötab?
Tõlkija on võimeline ka kõne tõlkimisel. See tehnoloogia on avatud tõlkija Live funktsioon (http://translate.it), tõlkija rakendused, Skype Translator ja on ka algselt kättesaadavaks ainult läbi Skype Translator funktsiooni ja Microsoft Translator rakendustes iOS ja Android, see funktsioon on nüüd saadaval arendajatele uusima versiooni avatud Azure ' i portaalis saadaval on REST-põhine API.
Kuigi see võib tunduda otsekohene protsess esimesel pilgul ehitada kõne tõlke tehnoloogia olemasolevate tehnoloogiate tellised, see nõudis palju rohkem tööd kui lihtsalt ühendada olemasoleva "traditsiooniline" inimese-to-Machine kõnetuvastus olemasoleva teksti tõlge üks.
Õigesti tõlkida "allikas" kõne ühest keelest teise "Target" keel, süsteem läbib nelja etapi protsessi.
- Kõnetuvastus, heli teisendamine tekstiks
- TrueText: Microsofti tehnoloogia, mis normaliseerib teksti, et muuta see tõlke jaoks asjakohasem
- Tõlge läbi teksti tõlke mootor eespool kirjeldatud, kuid tõlkemudelite spetsiaalselt välja töötatud reaalsest elust kõnelenud vestlused
- Teksti kõneks, vajadusel, et toota tõlgitud heli.

Automaatne kõnetuvastus (ASR)
Automaatne kõnetuvastus (ASR) teostatakse närvivõrgu (NN) süsteemi abil, mis on koolitatud tuhandeid tunde sissetulevat helisalvestust analüüsima. See mudel on koolitatud inimeste ja inimeste vastasmõjude, mitte inimese-to-Machine käske, mis toodavad Kõnetuvastus, mis on optimeeritud tavaliste vestluste. Selle saavutamiseks on vaja palju rohkem andmeid, samuti suuremat DNN-i kui traditsioonilisi inim-to-Machine ASRs.
Lisateave Microsofti kõne tekstiteenuste jaoks.
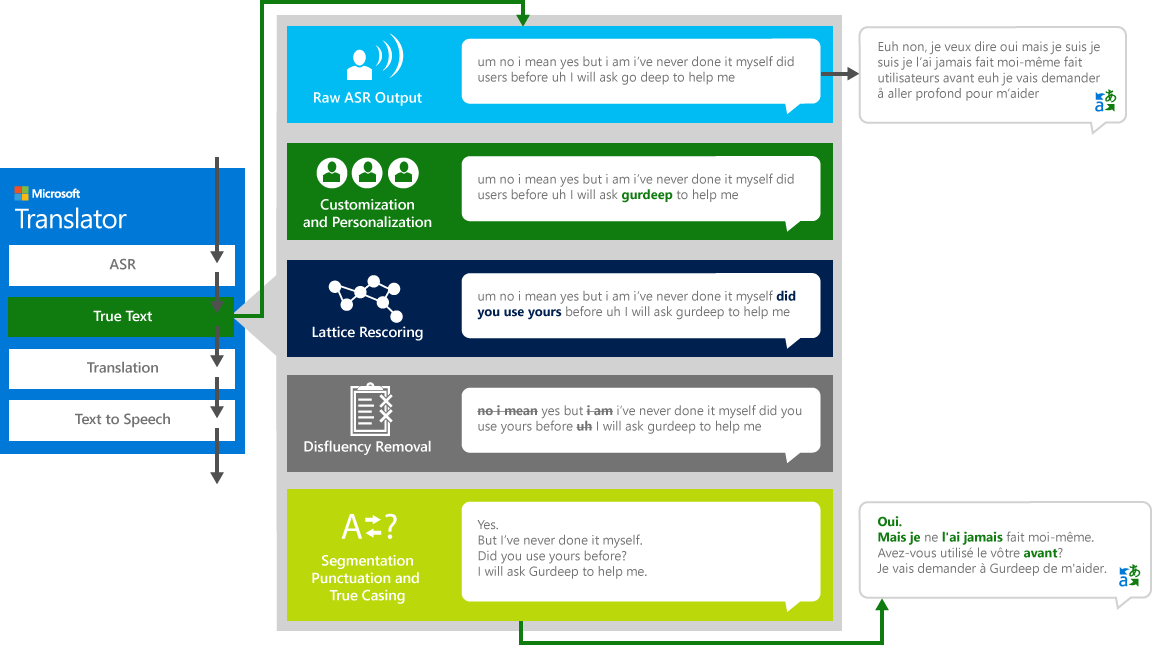
TrueText-tekst
Kui inimesed räägivad teiste inimestega, siis me ei räägi nii täiuslikult, selgelt või korralikult, nagu me sageli arvame. TrueText tehnoloogia, sõnasõnaline tekst on ümber, et paremini kajastada kasutaja kavatsuste eemaldades kõne disfluariikide (täiteaine sõnad), nagu "UM" s, "ah" s, "ja" s, "nagu" s, stutters, ja kordused. Tekst on ka loetavam ja tõlgitav, lisades laused pause, õige kirjavahemärgid ja kapitaliseerimine. Nende tulemuste saavutamiseks kasutasime me aastakümneid tööd keeletehnoloogiate valdkonnas, arendasime tõlkijat, et luua TrueText. Järgnev Diagramm kirjeldab reaalelu näite abil, et eri transformatsiooni TrueText toimib selle sõnasõnalise teksti normaliseerimiseks.
Tõlge
Seejärel tõlgitakse tekst keeled ja murded Tõlkija toetab.
Tõlked, kasutades kõne tõlge API (arendaja) või kõne tõlke rakendus või teenus, on powered koos uusim Neural-võrgu põhinev tõlked kõik kõne sisend toetatud keeled (vt Siin täielik loetelu). Need mudelid ehitati ka laiendades praegust, enamasti kirjutatud teksti koolitatud tõlke mudelid, rohkem räägitud teksti Kapra ehitada parem mudel kõne vestlus tüüpi tõlked. Need mudelid on saadaval ka "kõne" Standard kategooria traditsioonilise teksttõlke API-ga.
Mis tahes keeles, mida närvi tõlge ei toeta, tehakse traditsiooniline SMT tõlge.
Tekst kõneks
Kui Sihtkeel on üks 18 toetatud teksti kõneks Keeledja kasutamise puhul on vaja heliväljundit, teisendatakse tekst kõneväljundit kasutades kõnesünteesi. See etapp on jäetud kõne tekstiks tõlke stsenaariumide.
Lisateave Microsofti tekst kõneteenustele.
Teadus
Saate vaadata Microsoft translaatori meeskonna värskemaid teadusdokumente.



