

Azure HBv2 VM での OpenFOAM のパフォーマンスとコストの最適化
Azure – HPC
Share
協力者: Jon Shelley、プリンシパル PM マネージャー、マイクロソフト、Amirreza Rastegari、プログラム マネージャー 2、マイクロソフト、Gaurav Uppal、プログラム マネージャー、マイクロソフト
Azure HBv2 仮想マシンは、あらゆるパブリック クラウド プロバイダーの中で最高レベルの HPC パフォーマンス、スケーラビリティ、およびコスト効率を実現します。AMD EPYCTM 7V12 プロセッサを搭載した HBv2 VM は、リーダーシップ レベルの x86 コア数、メモリ帯域幅、および L3 キャッシュを備えています。また、すべての HBv2 VM に搭載されている 200 Gb/秒の HDR InfiniBand ネットワークにより、仮想マシン スケール セットでは 1 ジョブあたり 36,000 コアまで、また最大規模のお客様については 80,000 コアまでの MPI のスケーラビリティが可能です。
この豊富なリソースによりお客様は自在な構成が可能なため、HPC ワークロードや個々のモデルを最適化し、最高レベルの解析速度と総コストを実現できます。
この原理を実際に説明するために、Azure HPC チームは HBv2 VM 上で、広く使用されている CFD アプリケーションである OpenFOAM を、標準的な「Motorbike」モデルで 2,800 万セルのメッシュ サイズで実行しました。この演習では、OpenFOAM のようなメモリ帯域幅の影響を受けやすいアプリケーションでの、VM あたりのコア数を抑えてコアあたりのメモリ帯域幅を増やすことのメリットを確認できます。メモリ帯域幅の FLOPS とバイト数のバランスを改善するこのアプローチにより、同じアプリケーションとモデルを Amazon Web Services 上のあらゆる HPC 仮想マシン製品で実行した場合と比較して、非常に優れたパフォーマンス、スケーリング効率、およびコスト効率が実現されます。
HBv2 のテスト構成
各 Azure HBv2 仮想マシンの構成は以下のとおりです。
- AMD EPYC 7V12 CPU からの 120 の物理 CPU コア (SMT は既定で無効)
- 450 GB のメモリ (ノードあたり)
- 350 GB/秒のメモリ帯域幅 (STREAM TRIAD)
- 200 Gb/秒の Mellanox HDR InfiniBand
OpenFOAM
OpenFOAM は複雑なモデルおよびシミュレーション向けのオープン ソースの CFD ソルバーです。Motorbike モデルでは、OpenFOAM はバイクとライダーの周囲の定常気流を計算します。OpenFOAM はユーザーにより指定されたプロセス数に従って計算を負荷分散し、解析するプロセスごとにメッシュを分割します。解析の完了後、メッシュと解が 1 つの領域に再合成されます。
これは中規模のモデルであるため、ある点までスケーリングした後、その後は線形にはスケーリングしなくなります。言い換えると、このようなモデルでは「スイート スポット」までは追加コストなしで解析速度が上昇し続けますが、この点を超えると解析速度を上げるにはジョブあたりのコストも増加します。
このベンチマーク演習で使用したソフトウェアは以下のとおりです。
- OpenFOAM CFD Software (v1912)
- Spack Package Manager (v0.15.4)
- GNU Compiler Collection (v9.2.0)
- Mellanox HPC-X Software Toolkit v2.7.0 (OpenMPI v4.0.4 上に構築)
結果
図 1 に、モデルを 1 ~ 32 台の VM でスケーリングしたときの生パフォーマンス データを示します。1 ~ 16 台の VM の小スケール構成では、ほとんどの実時間は通信ではなく計算に費やされるため、60 コア/ノードを使用したほうが (青線) 優れたパフォーマンスとスケーリング効率が達成されます。しかしスケールが大きくなるにつれ、30 コア/ノードのみを使用したほうが (緑線) スケーリング効率が向上します。32 台の VM のフルスケールでは、30 コア/ノードのみを使用したほうが、スケーリング効率が高いだけでなく、絶対的パフォーマンスも高くなります。

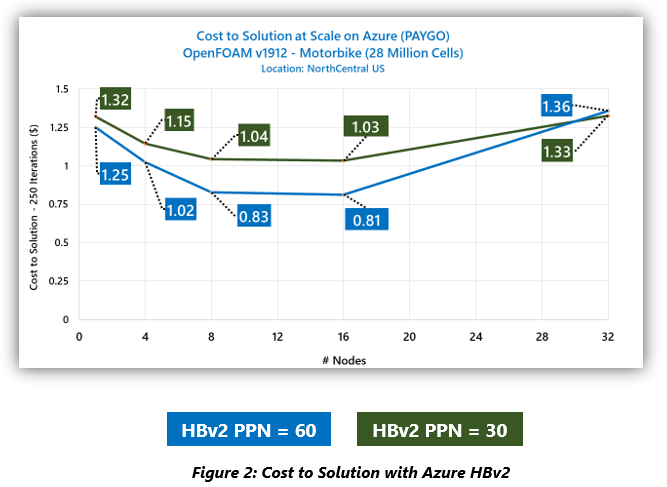
図 2 のビジネス上の考慮事項に目を向けると、ジョブあたりのコストがスケールとともに変化することがわかります。どちらのアプローチでも同じ数の VM を使用しているため、コストの差は、VM スケールの特定のレベルでどちらのアプローチがよりパフォーマンスが高いかを示しています。したがって、スケーリング演習の大半では 60 コア/ノードのアプローチのほうが、コスト効率が高くなりますが、32 台の VM では 30 コア/ノードを使用したほうが、コスト効率が高くなります。
このデータを、HPC のお客様が、専用 HPC 機能の提供における Azure のアプローチの強みを理解するうえで役立つ視点で示すために、HBv2 の結果を、c5n.18xlarge 仮想マシンを使用した Amazon Web Services での同じアプリケーションとモデルの結果 (AWS のモータースポーツ向けの数値流体力学レポートから引用) と比較してみます。
C5n.18xlarge の仕様は以下のとおりです。
- Intel Xeon 8124m (「Skylake」) からの 36 の物理 CPU コア (HT は既定で有効)
- 192 GB のメモリ (ノードあたり)
- 190 GB/秒のメモリ帯域幅 (STREAM TRIAD)
- 100 Gb/秒のイーサネット (AWS 「低遅延」 EFA を使用)
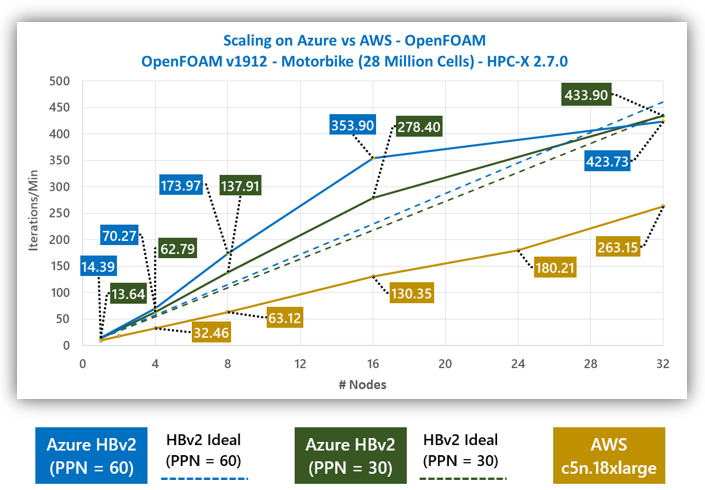
図 3 では、スケーリング演習の全範囲を通して、HBv2 のパフォーマンスが 2.16 ~ 2.68 倍高いことがわかります。60 コア/ノードと 30 コア/ノードのどちらのアプローチでも (一方は C5.18xlarge よりも多くのコアを使用し、もう一方はより少ないコアを使用)、スケーリング演習全体を通して大幅に高いパフォーマンス レベルが見られます。HBv2 の高いスケーリング効率にも注目してください。その優れたインターコネクト テクノロジにより、演習の最後まで超線形に上昇しています。つまり、演習のほぼ全範囲を通して、1 台の VM だけで問題を解析する場合と比べて、お客様がより多くの VM を導入するほど、総コストは減ります。
このパフォーマンス データを、米国の類似の地域での各クラウド プロバイダーからの各 VM チームの従量制 (または「オンデマンド」) 価格と重ね合わせたものが、以下の図 4 です。
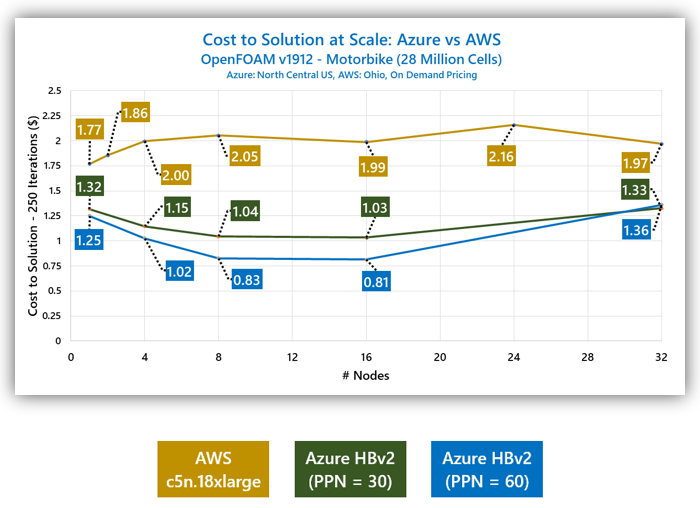
スケーリング演習の全範囲を通して、総解析コストは、AWS と比較して、Azure では最大で 2.45 倍低くなっています。最大の差は 16 台の VM で発生し、ここでの Azure での解析コストは、お客様が AWS で同じ問題を解析した場合の 40% 以下です。
まとめ
コスト効率が高く、効率的にスケーラブルな構成要素は、優れた HPC システム設計の特徴であり、科学者やエンジニアが最小限のコストでより迅速に洞察を獲得することを可能にします。逆に言えば、HPC のお客様は高価でスケーラビリティの低い HPC アーキテクチャをこれまで避けてきており、パブリック クラウドの時代でもそれは継続します。
この演習では、Microsoft Azure HPC チームは、Azure HBv2 と OpenFOAM が最強の組み合わせであることを実証しました。Azure HBv2 仮想マシンは、他のパブリック クラウド プロバイダーと比べて一貫して大幅なリードを実現し、お客様があらゆる規模で解析速度とコストを最適化することを可能にします。具体的には、これらのデータに基づく比較から、以下のような結論を導き出すことができます。
- Azure HBv2 シリーズは CFD に対して実証済みのプラットフォームであり、モデルによっては超線形のスケーリングを実現できる。
- プロセスごとのメモリ帯域幅の比率を最適化することにより、実行時間を短縮し、解あたりの総コストを削減できる。
- Azure HBv2 は現在クラウドで最もスケーラブルな CFD プラットフォームを提供している。
- OpenFOAM のような CFD ワークロードの実行時には、AWS の最上位仮想マシン オファリングと比較して、Azure HBv2 は優れたコスト/パフォーマンス比を実現する。