


創薬における AI/ML の活用と Microsoft の取り組み
Ⅰ. 創薬を取り巻く環境とAI/ML活用への期待
一般に、新薬の創出には膨大な時間とコストがかかる一方、その成功確率は極めて低いといわれています。2012~22 年の 11 年間における日本の製薬企業の研究開発に対する医薬産業政策研究所の調査[1]によると、1 新薬をグローバル開発で上市させるまで、基礎研究から申請までの全期間に要する研究開発費は約 131 億円、プロジェクト成功確率は 3.4%(プロジェクト数ではなく合成化合物数ベースの場合は一般に 1/25,000 ともいわれます)、そして所用期間は 14 年 4 か月とされています。調査の対象や推計の方式による数値の振れ幅はあるものの、こうしたコストや成功確率、期間に係る傾向はグローバルでも同様[2]であり、昨今のアンメットメディカルニーズの複雑化や、特に低分子領域における創薬ターゲットの枯渇などにより、新薬創出の難度はますます高まっています。

こうしたビジネス環境下で製薬企業各社は、全社・事業戦略レベルでは注力領域の選択や M&A、オープンイノベーション加速等の様々な施策を講じつつ新薬創出プロセスそのものの生産性向上にも努められており、AI/ML の活用はその方策の一つとして高い期待を持たれています。例えば McKinsey & Company 社の試算では、AI/ML の活用により製薬企業は創薬コストを 30〜50 %削減し、パイプラインのスピードを 20 %以上向上させることができるとされています[3]。
なお、AI/ML の活用は新薬創出プロセスの全ステージ(標的同定~市販後調査)において多岐にわたるシナリオが考えられますが[4]、本稿では R&D 領域、特に探索研究~非臨床試験のステージにフォーカスし、臨床試験移行のステージにおける AI/ML 活用については別稿に譲ることとします。

Ⅱ. 創薬におけるAI/MLの市場動向と主な活用シナリオ
パイプライン創出に何らかの形で AI/ML が用いられ、かつ 2024 年までに臨床試験(Phase I~III)が開始されている 111 のプロダクトに対するIQVIA社の調査によると、AI/ML による貢献は特に化合物設計( 32 %)や標的同定( 31 %)等の探索研究領域に対する割合が最も高く、次いでプレシジョン・メディシン開発( 18 %)や臨床試験のシミュレーション( 13 %)等が挙げられています[5]。また同レポート内では、2024年にグローバルのライフサイエンス業界の R&D 領域で発生した AI/ML 関連の大規模( 2 億米ドル以上)ディールが 12 件あり、総額約 100 億米ドルに上ったことも示されています[5]。このように AI/ML は、R&D の中でも特に上流の工程である標的同定~化合物設計等の探索研究領域における活用や投資が進んでいると考えられます。

別の観点としてモダリティに着目をしてみると、AI/ML の応用が相対的に容易と考えられる低分子だけではなく、近年は核酸医薬品や、タンパク質・抗体等のバイオ医薬品の創出に対する投資も進んでいます。例えば、Fig.3 に示した化合物探索に係る案件のうち、Genetic Leap 社と Eli Lilly 社の提携はRNA を標的とするオリゴヌクレオチドの創出を目指すものであり[6]、Generate:Biomedicines 社とNovartis 社の提携は複数疾患領域のタンパク質治療薬の創出を目標としています[7]。
このように創薬に係る AI/ML への投資と活用はますます拡大していますが、具体的にはどのようなシナリオがあるのでしょうか。本稿ではごく一部に限られますが、以下に例示します。
1)標的同定:
治療標的同定では、健常者と患者の遺伝子(ゲノム)やその発現状況(トランスクリプトーム、プロテオーム、メタボローム)のプロファイルを比較するアプローチが主流ですが、これにより見いだされる候補は膨大かつ必ずしも標的として有効ではないことが課題となっており、これを補強・補完するようなアプローチとして、疾患とタンパク質の関係性を AI/ML で予測するような手法が提案されています。ここにおけるAI/MLの用途も様々考えられますが、例としてタンパク質をコードする遺伝子に改変(ノックダウンや過剰発現化)を加えた際のトランスクリプトーム( mRNA プロファイル)から対象タンパク質の治療標的としての有望性を予測したり、各種データベースに蓄積されたタンパク質間の相互作用や生物学的機能に係る関係性から対象タンパク質が治療標的となりうる疾患を予測したりといった研究が発表されています[8, 9, 10]。
2)タンパク質の立体構造予測:
2024 年のノーベル化学賞受賞でも話題となった、AI によるタンパク質の立体構造予測も創薬での活用に高い期待が寄せられています。例えば、標的としての有望性を検証したり実際に標的とする結合部位の特定に繋げたりという観点では広義の治療標的同定に寄与する活用シナリオであり、結合ポケット等の構造を解明することで SBDD(structure based drug discovery)アプローチで後述の化合物探索・設計に寄与する活用シナリオでもあります[8]。
3)化合物探索:
化合物探索においては、大量の化合物ライブラリーから有望な候補を見つけ出す従来のスクリーニング型手法に代わり、目的とする薬理特性を持つ化合物構造を直接予測する「逆構造活性相関解析」が注目されています。分子構造の表現としては SMILES や SELFIES、DeepSMILES 等に代表される文字列表記を用い、N-gramや、VAE、GAN、再帰的ニューラルネットワーク、強化学習、自然言語処理で注目を集めている Transformer 等の様々な技術を組み合わせた生成手法が提案されています。また、化合物の構造を文字列ではなくグラフとして捉えて構造生成を行う手法( JT-VAE、Graph-AF 等)や、所望の物性を持つ化合物の構造だけでなくその合成経路も提示する手法( casVAE 等)も提案されています[8]。
上記以外にも、化合物の分子プロファイル(合成可能性、体内動態、毒性等)予測やリード分子最適化等、AI/ML を創薬の探索研究領域で活用するシナリオは様々挙げられます[4, 8, 11]。
Ⅲ. Microsoftの取り組みや関連ソリューション
当社 Microsoft においても、ライフサイエンス・創薬に特化した AI モデルの開発や、Azure OpenAI やMicrosoft 365 Copilot 等のAIソリューションの活用による探索研究プロセスの生産性向上等の実例があります。
1) BioEmu(Azure AI Foundryで利用可)によるタンパク質構造の予測
BioEmu(Biomolecular Emulator)は Microsoft Research が開発したディープラーニングモデルで、タンパク質がとりうる膨大な構造のアンサンブルを生成することができ、対象タンパク質が生体・溶液中で取りうる構造のバリエーションを理解することに役立ちます。
従来、タンパク質の生体・溶液中での構造を予測する方法としては主に分子動力学(MD)シミュレーションが用いられてきましたが、この手法で示唆を得るには非常に長時間のシミュレーションと膨大な量の計算処理が必要であり、時としてそれは実現可能な範囲を超えてしまうという課題があります。一方 BioEmu は、MD シミュレーションに比べて計算効率が桁違いに高く、1つの GPU で1時間当たり数千のタンパク質構造を生成することができます[12]。ここで、BioEmu の有用性を示唆する研究成果の例をご紹介します。
まずは、BioEmu により未知のタンパク質配列の構造を予測した例です。次の Fig. は、コレラの原因菌 Vibrio cholerae 由来のタンパク質LapDについて、BioEmu が予測した構造と実験で得られた構造を重ね合わせて示しています。対象としたLapDの構造は実験的に知られているものの BioEmu の学習データには含まれていなかったため、BioEmu-1 がその構造の「予測」に成功していることが伺えます。また、BioEmu は実験的にまだ得られていない中間的な構造も予測しているため、対象タンパク質の生化学的なふるまいに対する仮説づくりに貢献しうると考えられます。

これに加えて、BioEmu がごく僅かな計算コストで MD シミュレーションの結果を正確に再現できる(GPU 使用時間が MD シミュレーションの 1 万~10 万分の 1 )ことや、タンパク質の安定性(フォールディングの自由エネルギーΔG )も高い精度で予測しうること等が研究成果としてプレプリントで公表されています[12, 13]。なお、BioEmu は現在、Azure AI Foundry のモデルカタログで選択してデプロイすることが可能です。

2) TamGen(Azure AI Foundryで利用可)による化合物構造の生成
TamGen(Target-aware molecule Generation)は、Global Health Drug Discovery InstituteとMicrosoft Researchの共同研究を経て開発されたTransformerベースの生成AIモデル(Chemical Language Model)で、SMILES(Simplified Molecular Input Line Entry System)表記法に変換した分子情報を処理し、標的タンパク質特異的な候補化合物の構造を生成することができます[14]。
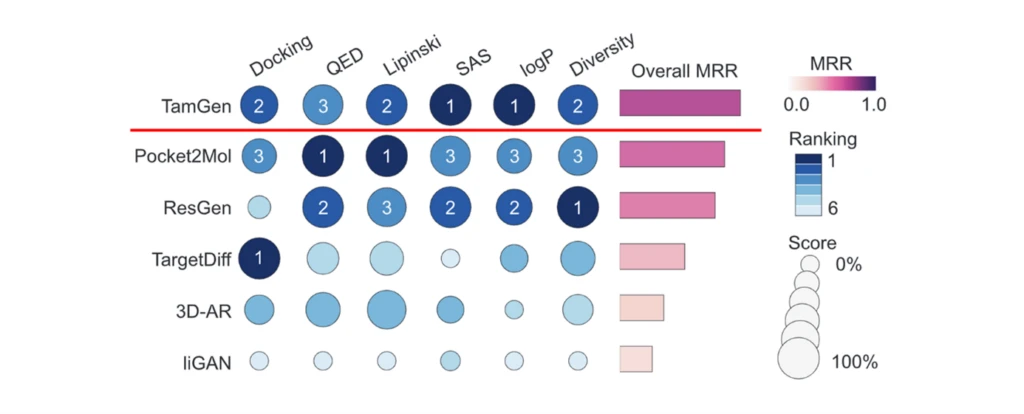
従来のスクリーニング(in vitroのハイスループットスクリーニング、in silicoのバーチャルスクリーニング等)によってヒット化合物を見出すアプローチは通常104~108程度の化合物ライブラリーを探索しますが、生成AIモデルを活用するアプローチ(Generative drug design)では1060以上ともいわれる広大なケミカルスペースを探索することができると考えられています[15]。Generative drug designアプローチに関してはこれまでも、自己回帰(AR)モデルやGAN、VAE、拡散モデル等の様々なAI技術に基づく手法が提案されていますが、生化学的アッセイによる検証が不足していたり、合成可能性を含むDrug-likenessが不十分であったりといった理由で創薬での実用性が乏しいケースも多くみられました[15]。一方TamGenは、近年提案された5つのGenerative drug design手法(LiGAN、3D-AR、Pocket2Mol、ResGen、 TargetDiff)に比して、標的タンパク質への結合性だけでなく、実際に薬剤化できるかどうか(Drug-likeness)に係る指標においてもよい成績を収めています[15]。より具体的には、標的タンパク質への結合性の指標としてドッキングスコアを、Drug-likenessの指標としてQuantitative Estimate of Drug-likeness (QED)や、医薬品になりやすい化合物の特性を表す経験則Lipinski’s Rule of Five、合成難易度を表すsynthetic accessibility scores (SAS)、そして脂溶性を表すLogP等でベンチマーク評価したところ、TamGenは総合的に最上位にランクされました。
また、結核菌由来のタンパク質ClpPプロテアーゼを標的として、TamGenによる候補化合物の生成と改良設計、実験による活性確認の組み合わせによる研究の結果として、IC₅₀が40 μM未満の高い阻害活性を示す化合物が14種類、そのうち最も高い活性としてIC₅₀が1.88 μMのヒット化合物が得られており[15]、創薬におけるTamGenの実用性が示唆されています。なお、TamGenは現在、Azure AI Foundryのモデルカタログで選択してデプロイすることが可能です。

3) Azure OpenAI や Microsoft 365 Copilot 等による探索研究プロセスの生産性向上
上記のようにライフサイエンス・創薬に特化したAIモデルの提供だけでなく、Azure OpenAI やMicrosoft 365 Copilot のエージェント等を組み合わせ、探索研究プロセスの生産性を劇的に高めるような活用シナリオも多数存在します。
例えば、Amgen 社では全社的に Microsoft 365 Copilot を活用いただいていますが、特に R&D 部門の研究者向けには Catalyst Copilot と呼ばれるエージェントを独自に構築し、治療領域別に整理されたナレッジやトレーニング ビデオ、製品データベースなどが含まれる膨大な情報に対し、自然言語のクエリで即座にアクセスできる環境を提供しています[16]。
また、Boehringer Ingelheim 社ではサイエンス・臨床研究・特許等の特殊な情報も含むデータの量の膨大さと、その中でのコンテキスト(例:特殊な医療用語や略語、表現の揺れ)の複雑さがネックでナレッジ活用に膨大な時間を要していた課題に対し、Azure OpenAI を活用したナレッジマネジメントプラットフォーム iQNow を開発し、グループ全体で約 150,000 時間の労働時間を削減しています[17]。ここではごく一部の例を挙げましたが、日本国内を含むグローバルの様々な製薬企業において、主にナレッジマネジメントのプラットフォームとしてこうした AI/ML ソリューションを活用することで探索研究プロセスの生産性向上を目指す試みが進められています。
Ⅳ. 創薬におけるAI/MLの活用に係る課題と展望
ここまでに述べたように、創薬でのAI/ML活用は市場の期待と現場の研究・応用がますます拡大しており、新薬創出の生産性を劇的に高める可能性を示しつつあります。一方で、in silicoとin vitroの適材適所での使い分けは、もちろん当面必要であり続けると考えられます。また、AI/MLによって予測・生成された化合物が現実に合成・入手できないといったin silicoとin vitroの境界で起こる問題の解決や、診療情報等のヒトデータと分子データの統合的な解析、構造や物性がより複雑なペプチド・抗体・核酸等新規モダリティ分子での活用等、取り組むべき課題は多く残されています。
こうした課題へのアプローチにおける技術的側面においては、新規モデルの開発や改良、様々なモデルや手法の組み合わせによるAI/ML自体の技術進化は当然ながら、それらをクラウド上で行うことでフレキシビリティやアジリティを高めたり、HPC(High Performance Computing)や将来的には量子コンピューティング等の他の技術と連携させたりといったことがますます重要になっていくと考えられます。
参考文献
[1] 製薬協, データで見る医薬品研究開発の実態, 製薬協ニューズレター, 2024年1月号 No.224.
[2] AI’s potential to accelerate drug discovery needs a reality check. Nature 622, 217 (2023).
[3] McKinsey & Company. Generative AI in the pharmaceutical industry: Moving from hype to reality, January 2024.
[4] Zhang, K., Yang, X., Wang, Y. et al., Artificial intelligence in drug development, Nat Med 31, 45–59 (2025).
[5] IQVIA, Global Trends in R&D 2025. Institute Report, Mar 26, 2025.
[8] 国立研究開発法人 科学技術振興機構(JST)研究開発戦略センター(CRDS), 研究開発の俯瞰報告書 ライフサイエンス・臨床医学分野, 2024年.
[9] Namba, S., et al., From drug repositioning to target repositioning: prediction of therapeutic targets using genetically perturbed transcriptomic signature, Bioinformatics 38, Issue Supplement_1, (2022), Pages i68–i76.
[10] Han, Y., et al., Empowering the discovery of novel target-disease associations via machine learning approaches in the open targets platform, BMC Bioinformatics 23 232 (2022).
[11] 田中成典, 広川貴次, 池口満徳, インシリコ創薬 計算創薬の基礎から実例まで, 森北出版, 2025
[12] Microsoft Research Blog, Exploring the structural changes driving protein function with BioEmu-1, February 2025.
[13] Lewis, S., et al., Scalable emulation of protein equilibrium ensembles with generative deep learning, bioRxiv 2024.12.05.626885.
[14] Microsoft Research Blog, Accelerating drug discovery with TamGen: A generative AI approach to target-aware molecule generation, November 2024.
[15] Wu, K., Xia, Y., Deng, P. et al., TamGen: drug design with target-aware molecule generation through a chemical language model, Nat Commun 15, 9360 (2024).


