William Blum, Principal Research Engineering Lead. (Photography by Scott Eklund/Red Box Pictures)
Microsoft researchers have developed a new method for discovering software security vulnerabilities that uses machine learning and deep neural networks to help the system root out bugs better by learning from past experience. This new research project, called neural fuzzing (opens in new tab), is designed to augment traditional fuzzing techniques, and early experiments have demonstrated promising results.
Software security testing is a hard task that is traditionally done by security experts through costly and targeted code audits, or by using very specialized and complex security tools to detect and assess vulnerabilities in code. We recently released a tool, called Microsoft Security Risk Detection (opens in new tab), that significantly simplifies security testing and does not require you to be an expert in security in order to root out software bugs. The Azure-based tool is available to Windows users and in preview for Linux users.
Fuzz testing
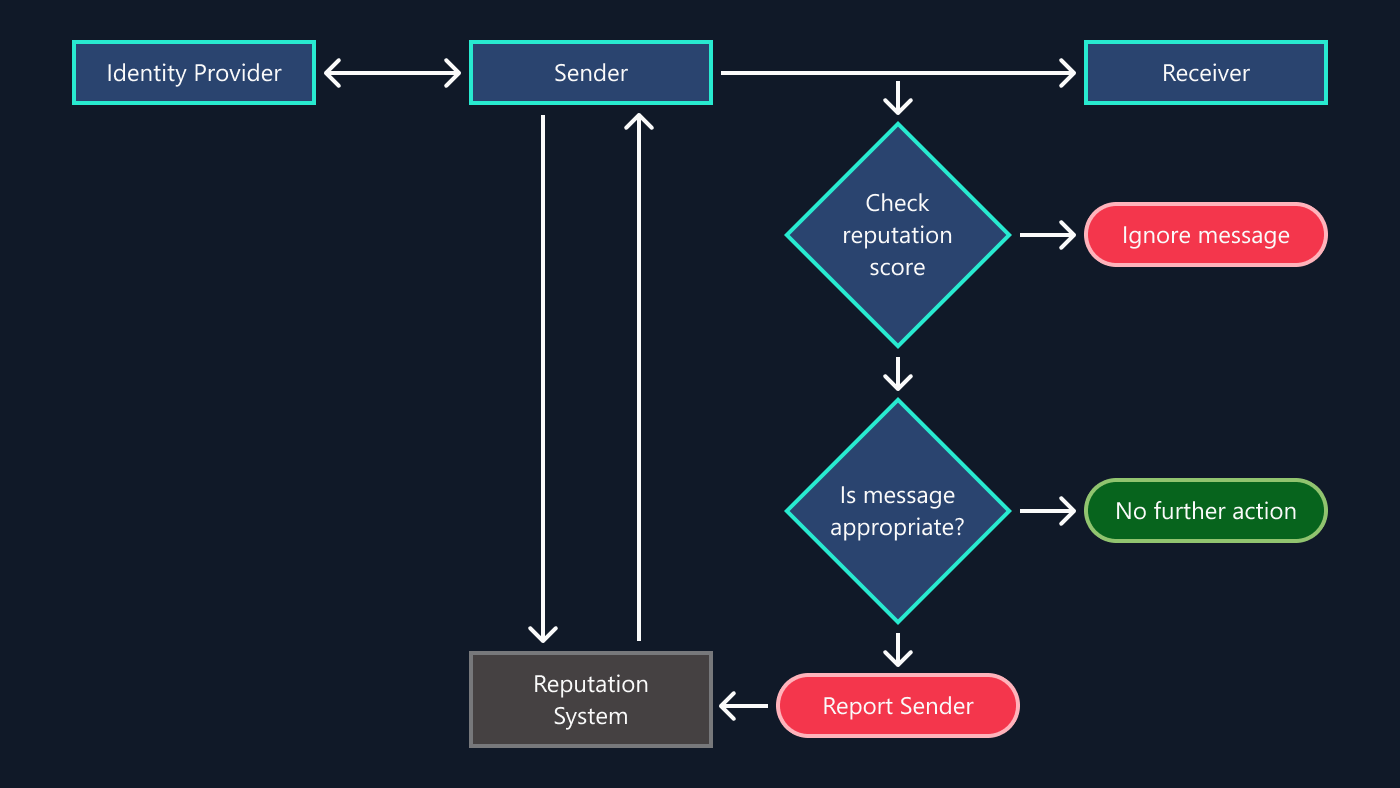
The key technology underpinning Microsoft Security Risk Detection is fuzz testing, or fuzzing. It’s a program analysis technique that looks for inputs causing error conditions that have a high chance of being exploitable, such as buffer overflows, memory access violations and null pointer dereferences.
Microsoft research podcast

Collaborators: Silica in space with Richard Black and Dexter Greene
College freshman Dexter Greene and Microsoft research manager Richard Black discuss how technology that stores data in glass is supporting students as they expand earlier efforts to communicate what it means to be human to extraterrestrials.
Fuzzers come in different categories:
- Blackbox fuzzers, also called “dumb fuzzers,” rely solely on the sample input files to generate new inputs.
- Whitebox fuzzers analyze the target program either statically or dynamically to guide the search for new inputs aimed at exploring as many code paths as possible.
- Greybox fuzzers, just like blackbox fuzzers, don’t have any knowledge of the structure of the target program, but make use of a feedback loop to guide their search based on observed behavior from previous executions of the program.

Figure 1 – Crashes reported by AFL. Experimental support in MSRD
Neural fuzzing
Earlier this year, Microsoft researchers including myself, Rishabh Singh (opens in new tab), and Mohit Rajpal, began a research project looking at ways to improve fuzzing techniques using machine learning and deep neural networks. Specifically, we wanted to see what a machine learning model could learn if we were to insert a deep neural network into the feedback loop of a greybox fuzzer.
For our initial experiment, we looked at whether we could learn over time by observing past fuzzing iterations of an existing fuzzer.
We applied our methods to a type of greybox fuzzer called American fuzzy lop, or AFL.
We tried four different types of neural networks and ran the experiment on four target programs, using parsers for four different file formats: ELF (opens in new tab), PDF (opens in new tab), PNG (opens in new tab), XML (opens in new tab).
The results were very encouraging—we saw significant improvements over traditional AFL in terms of code coverage, unique code paths and crashes for the four input formats.
- The AFL system using deep neural networks based on the Long short-term memory (opens in new tab) (LSTM) neural network model gives around 10 percent improvement in code coverage over traditional AFL for two files parsers: ELF and PNG.
- When looking at unique code paths, neural AFL discovered more unique paths than traditional AFL for all parsers except PDF. For the PNG parser, after 24 hours of fuzzing it found twice as many unique code paths as traditional AFL.

Figure 2 – Input gain over time (in hours) for the libpng file parser.
- A good way to evaluate fuzzers is to compare the number of crashes reported. For the ELF file parser, neural AFL reported more than 20 crashes whereas traditional AFL did not report any. This is astonishing given that neural AFL was trained on AFL itself. We also observed more crashes being reported for text-based file formats like XML, where neural AFL could find 38 percent more crashes than traditional AFL. For PDF, traditional AFL did overall better than neural AFL in terms of new code paths found. However, neither system reported any crashes.

Figure 3 – Reported crashes over time (in hours) for readelf (left) and libxml (right).
Overall, using neural fuzzing outperformed traditional AFL in every instance except the PDF case, where we suspect the large size of the PDF files incurs noticeable overhead when querying the neural model.
In general, we believe our neural fuzzing approach yields a novel way to perform greybox fuzzing that is simple, efficient and generic.
- Simple: The search is not based on sophisticated hand-crafted heuristics — the system learns a strategy from an existing fuzzer. We just give it sequences of bytes and let it figure out all sorts of features and automatically generalize from them to predict which types of inputs are more important than others and where the fuzzer’s attention should be focused.
- Efficient: In our AFL experiment, in the first 24 hours we explored significantly more unique code paths than traditional AFL. For some parsers we even report crashes not already reported by AFL.
- Generic: Although we’ve tested it only on AFL, our approach could be applied to any fuzzer, including blackbox and random fuzzers.
We believe our neural fuzzing research project is just scratching the surface of what can be achieved using deep neural networks for fuzzing. Right now, our model only learns fuzzing locations, but we could also use it to learn other fuzzing parameters such as the type of mutation or strategy to apply. We are also considering online versions of our machine learning model, in which the fuzzer constantly learns from ongoing fuzzing iterations.
William Blum (opens in new tab) leads the engineering team for Microsoft Security Risk Detection.
Related: