
![]()
Released in preview this week at Build 2018, the new Microsoft Translator custom feature lets users customize neural machine translation systems. These customizations can be applied to both text and speech translation workflows.
Microsoft Translator released neural machine translation (NMT) in 2016. NMT provided major advances in translation quality over the then industry-standard statistical machine translation (SMT) technology. Because NMT better captures the context of full sentences before translating them, it provides higher quality, more human-sounding and more fluent translations.
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
Stay connected to the research community at Microsoft.
There are limits to generic NMT models, however. Namely, they are not tuned to provide translations that are unique to a specific business or industry. However, it is too compute intensive, and therefore too expensive and slow, to retrain a new neural system from scratch for all languages and for every company or, even worse, for every product division within a company. Additionally, there is generally not enough parallel data available from the user to expect that the custom data alone would be sufficient to train a new good quality and appropriately adapted system.
Customization is a critical component of high quality machine translations. Customization provides additional context to generic translation models so that translations can reflect a company’s industry, tone and unique terminology.
As a simple illustration, the word “check” could mean many different things in English depending on context: a bank check, a check engine light in your car, a check list or box, etc. The same English word will most likely not always translate into the same word in another language. By providing additional context, the new customization feature can better recognize and translate a bank processing “checks” (pieces of paper) versus an auto manufacturer performing “checks” (verifications).
Of course, this is a simple example; generic NMT systems using the context of a sentence are generally sophisticated enough to resolve single word issues such as this. In the context of longer word sequences translation issues may become more apparent.
Simple as the concept of customization may be, putting it into practice is complex.
Customizing Neural Machine Translation models
To translate any word using a neural machine translation system, each word in a sentence is coded along a 500-dimensional vector representing its unique characteristics within a specific language pair (for example, English and Chinese). Based on the language pair used for training and the training data, the neural network will self-define what these dimensions represent. They could encode simple concepts like gender (feminine, masculine, neutral), politeness level (slang, casual, written, formal, and so on), type of word (verb, noun, and so on), but also any other non-obvious characteristics as derived from the training data. Once trained, the system encodes these words into higher dimensional vectors (1,000 dimensions) to embed both the word’s representation and its context with the full sentence. To learn more about how Neural Machine Translation works, please check our How machine translation works page.
Because of the complexity of these systems, an NMT model will have more than 10 million unique parameters per language. Each of these parameters will be tuned during training before the system is deployed for users and developers to use. This training is not only extremely compute-intensive (days of training using multiple dedicated high-power GPUs), but requires amounts of parallel training data that are, in most cases, several orders of magnitude larger than what a typical enterprise will have access to. For this reason, simply retraining a new NMT from scratch for each new system based on customer’s own data is not a technically or economically feasible option.
How we do it—the nuts and bolts of NMT customization
With careful design and research, using a combination of existing neural, hybrid neural and traditional as well as new techniques, we were able to build a customization feature that overcame these limitations to offer customers the possibility of creating translation models unique to their business and industry.
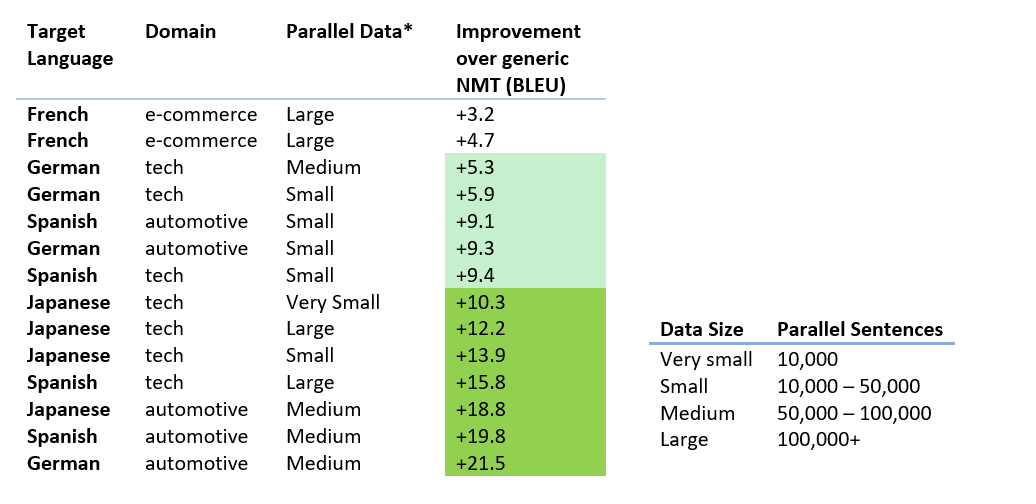
The starting point is available training data from the user’s own industry or company. To customize a system, a corpus of a minimum of 2,000 parallel sentences (human translated sentences in both the source and target language) is necessary. Working in partnership with Microsoft Translator key partners, and analyzing custom systems’ quality on dozens of data sets, we found that the results are always better than generic NMT, with most of systems showing large quality improvements.
Below are a few examples of BLEU score (an industry standard translation quality measure) improvements for various datasets size and content type. The improvement in quality over the default NMT system can vary from a few to more than 10 BLEU points.
 Before commencing training, the custom feature first preprocesses the data. For example, if versions of the same content in multiple languages in separate documents (for example, training manuals, web pages, leaflets) are the only content available, the custom feature will be able to automatically match sentences across documents to generate non-duplicated matched parallel training material. Also, if the user has monolingual data in either or both languages, this data can be used to complement the parallel data to improve the translation model.
Before commencing training, the custom feature first preprocesses the data. For example, if versions of the same content in multiple languages in separate documents (for example, training manuals, web pages, leaflets) are the only content available, the custom feature will be able to automatically match sentences across documents to generate non-duplicated matched parallel training material. Also, if the user has monolingual data in either or both languages, this data can be used to complement the parallel data to improve the translation model.
The first step the system performs is to start from the pre-existing model and to adapt the existing parameters using the new data. Conceptually, the system starts from the local minima of a general domain system (the best generic translation quality) and tunes it to the local minima relative to the custom data (the best translation quality for the user’s data). From a compute perspective, using this approach has tremendous benefits. By training the custom system from an existing one, the training algorithms are starting from parameters that are already close to what they should be and include information about how to translate concepts that may be outside the small amount of data the user provides. Because of this, the computing power necessary to custom train represents less than 1% of the GPU computing power necessary if training were to start from a blank slate model.
To further accelerate training, several variable learning rate techniques were tested, optimized and integrated into the process.
Not only is this approach effective from a cost and duration perspective (a model can be customized in as little as a few hours on the GPU-powered Azure AI cloud), it still significantly improves translations for the given dataset.

Jonathan Clark, Principal Scientist at Microsoft Research
“The key to custom training is having a good initializer for the neural network’s parameters and careful, relentless management of the optimizer’s learning rate,” explains Jon Clark, principal scientist on the Microsoft Translator team. “To make a golf analogy, by relying on our team-built systems as initializers, it’s like we’re already on the green and simply have to putt the ball into the hole with a thoughtful stroke.”
To further improve the custom translation quality, in addition to the neural network for translation that is optimized toward the user’s data, the custom feature also builds a language model over both the user’s parallel data and monolingual data. This further helps the system quickly learn and memorize key aspects of the customer’s unique data.
The resulting new model combines the breadth of the generic Translator NMT model with the unique terminology and tone of the customers parallel and monolingual data.
How to use the Microsoft Translator custom feature
The Microsoft Translator custom feature is available now. It can be used to customize neural text translations using the new Microsoft Translator V3 text API. It can also be used to customize speech translation using the new preview of Cognitive Services Speech. Both the V3 Text API and Cognitive Services Speech are available through the Azure portal with paid and free subscriptions.
The new custom portal can also be used to customize speech to text, and text to speech when used with the preview of Cognitive Services Speech. Learn more about these services.



