

If you’re a regular reader of the Experimentation Platform blog, you know that we’re always warning our customers to be vigilant when running A/B tests. We warn them about the pitfalls of even tiny SRMs (sample ratio mismatches), small bits of lossiness in data joins, and other similar issues that can invalidate their A/B tests [2, 3, 4]. But today, we’re going to switch gears and tell you to relax a little. We’re going to show you why A/B interactions – the dreaded scenario where two or more tests interfere with each other – are not as common a problem as you might think. Don’t get us wrong, we’re not saying that you can completely let down your guard and ignore A/B interactions altogether. We’re just saying that they’re rare enough that you can usually run your tests without worrying about them.
A/B Interactions
But we’re getting ahead of ourselves. What are A/B interactions? In an A/B test, users are randomly separated into control and treatment groups, and after being exposed to different product experiences, metrics are compared for the two groups [1]. At Microsoft’s Experimentation Platform (ExP), we have hundreds of A/B tests running every day. In an ideal world, every A/B test would get its own separate set of users. However, splitting users across so many A/B tests would dramatically decrease the statistical power of each test. Instead, we typically allow each user to be in multiple A/B tests simultaneously.
A case where concurrent A/B tests are safe
For example, a ranker might have one A/B test that changes the order of web results, and another A/B test that changes the UX. Both A/B tests can run at the same time, with users assigned independently to the control or treatment of each A/B test, in four equally likely combinations:
| Ranker #1 | Ranker #2 | |
| UX #1 | Control-control | Control-treatment |
| UX #2 | Treatment-control | Treatment-treatment |
In most cases, this is fine. Because which ad UX the user sees probably doesn’t have much impact on how they respond to the ranking of the results, the differences reported in the ranker A/B scorecard results will look the same regardless of what the UX A/B test is doing, and vice versa.
A case with A/B interactions
On the other hand, some cases are more problematic. For example, if there are two A/B tests, one which changes the ad text color from black to red, and one which changes the ad background color from grey to red, whether the user is in the control or the treatment of one A/B test will greatly impact the treatment effect seen in the other A/B test. The user can no longer see the ad text when it’s red on red, so the red ad text treatment might be good for users in the control of the ad background A/B test, but bad for users in the treatment of the ad background A/B test.
| Ad text color: black | Ad text color: light red | |
| Ad background color: grey | Buy flowers! | Buy flowers! |
| Ad background color: red | Buy flowers! | Buy flowers! |
A/B interactions can be a real concern, and at ExP we have techniques to isolate A/B tests like these from each other when we suspect they will interact, so that users aren’t assigned independently for each test. However, as already mentioned, doing this decreases the number of users available for each A/B test, thus decreasing their statistical power.
Looking for A/B Interactions at Microsoft
Our previous experience with A/B tests at Microsoft had found that A/B interactions were extremely rare. Similarly, researchers at Meta found that A/B interactions were not a serious problem for their tests [5 (opens in new tab)].
We recently carried out a new investigation of A/B interactions in a major Microsoft product group. In this product group, A/B tests are not isolated from each other, and each control-treatment assignment takes place independently.
The data analysis
Within this product group, we looked at four major products, each of which runs hundreds of A/B tests per day on millions of users. For each product, we picked a single day, and looked at every pair of A/B tests that were running on that same day. For each pair, we calculated every metric for that product for every possible control or treatment assignment combination for the two tests in the pair. The results for metric Y are shown here for a case where each test has one control and one treatment.
| A/B Test #2: C | A/B test #2: T | Treatment effect | |
| A/B test #1: c | YC,c | YT,c | Δc=YT,c– YC,c |
| A/B test #1: t | YC,t | YT,t | Δt=YT,t– YC,t |
A chi-square test was performed to check if there was any difference between the two treatment effects. Because there were hundreds of thousands of A/B test pairs and metric combinations, hundreds of thousands of p-values were calculated. Under the null hypothesis of no A/B interactions, the p-values should be drawn from a uniform distribution, with 5% of the p-values satisfying p<0.05, 0.1% of the p-values satisfying p<0.001, etc. [6]. Accordingly, some were bound to be small, just by chance.
The results: few or no interactions
Therefore, to check whether there were A/B interactions, we looked at the distribution function of p-values, shown here for a single day for a specific product:
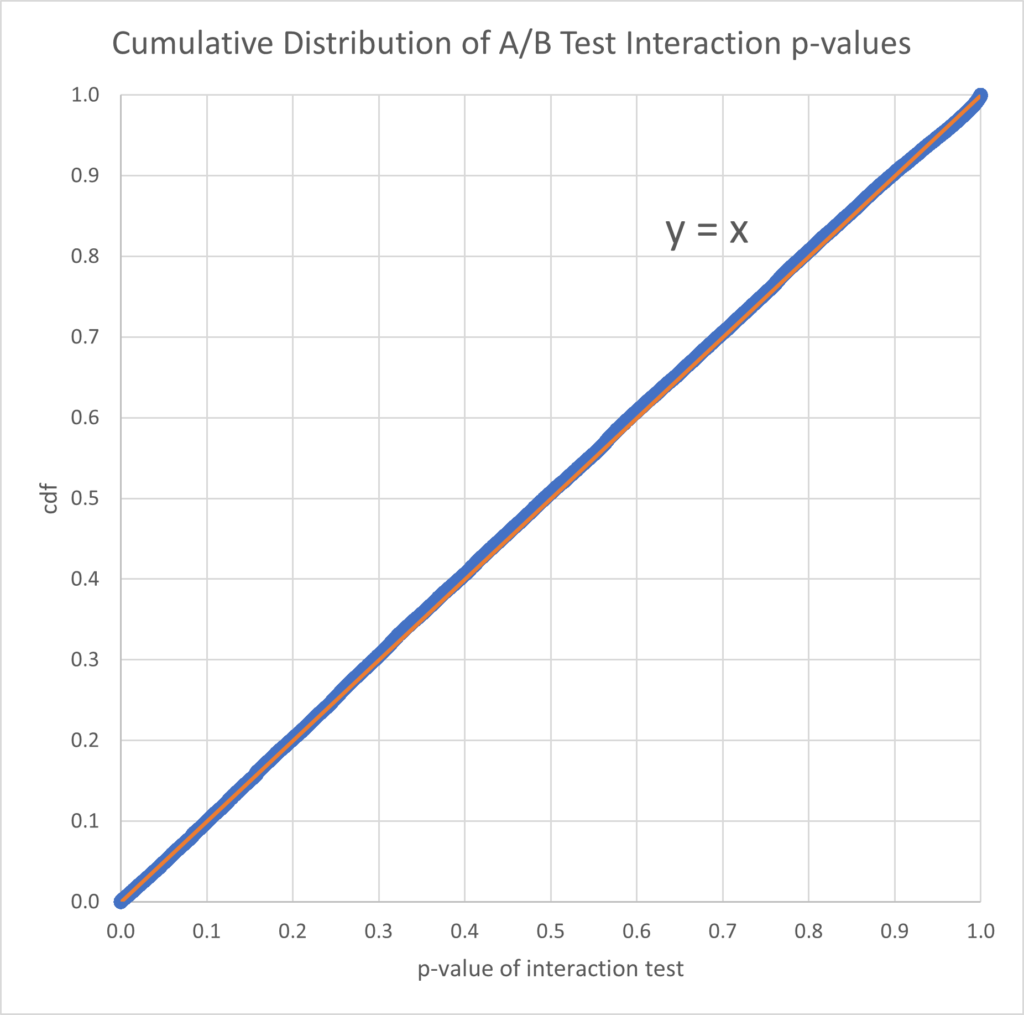
The graphs for all four products look similar; all are very close to a uniform distribution. We then looked for deviations from a uniform distribution by checking if there were any abnormally small p-values, using a Benjamini-Hochberg false positive rate correction test. For three of the products, we found none, showing that all results were consistent with no A/B interactions. For one product, we did find a tiny number of abnormally small p-values, corresponding to 0.002%, or 1 in 50,000 A/B test pair metrics. The detected interactions were checked manually, and there were no cases where the two treatment effects in Table 3 were both statistically significant but moving in opposite directions. In all cases either the two treatment effects were in the same direction but different in magnitude, or one of them was not statistically significant.
Discussion
It’s possible that there were other A/B interactions that we just didn’t have the statistical power to detect. If the cross-A/B test treatment effects were, for example, 10% and 11% for two different cross-A/B test assignments, we might not have detected that difference, either because the chi-square test returned a high p-value, or because it returned a low p-value that got “lost” in the sea of other low p-values that occurred by chance when doing hundreds of thousands of statistical tests.
This is possible, but it raises the question of when we should worry about interaction effects. For most A/B tests at Microsoft, the purpose of the A/B test is to produce a binary decision: whether to ship a feature or not. There are some cases where we’re interested in knowing if a treatment effect is 10% or 11%, but those cases are the minority. Usually, we just want to know if key metrics are improving, degrading, or remaining flat. From that perspective, the scenario with small cross-A/B test treatment effects is interesting in an academic sense, but not typically a problem for decision-making.
Conclusion
While there are cases where A/B interaction effects are real and important, in our experience, this is rare issue where people often worry more than they need to. Overall, the vast majority of A/B tests either don’t interact or have only relatively weak interactions. Of course, the results depend on the product and the A/B tests, so don’t just take our word for it: try running your A/B tests concurrently and perform your own meta-analysis of interaction effects!
– Monwhea Jeng, Microsoft Experimentation Platform
References
[1] Kohavi R., Tang D., & Xu Y. (2020). Trustworthy Online Controlled Experiments: A practical Guide to A/B Testing. Cambridge: Cambridge University Press. doi:10.1017/9781108653985
[2] Fabijan A., Blanarik T., Caughron M., Chen K., Zhang R., Gustafson A., Budumuri V.K. & Hunt S. Diagnosing Sample Ratio Mismatch in A/B Testing, http://approjects.co.za/?big=en-us/research/group/experimentation-platform-exp/articles/diagnosing-sample-ratio-mismatch-in-a-b-testing/.
[3] Liu P., Qin W., Ai H. & Jing J. Data Quality: Fundamental Building Blocks for Trustworthy A/B testing Analysis, http://approjects.co.za/?big=en-us/research/group/experimentation-platform-exp/articles/data-quality-fundamental-building-blocks-for-trustworthy-a-b-testing-analysis/ .
[4] Machmouchi W. and Gupta S. Patterns of Trustworthy Experimentation: Post-Experiment Stage, http://approjects.co.za/?big=en-us/research/group/experimentation-platform-exp/articles/patterns-of-trustworthy-experimentation-post-experiment-stage/.
[5] Chan T. Embrace Overlapping A/B Tests and Avoid the Dangers of Isolating Experiments, https://blog.statsig.com/embracing-overlapping-a-b-tests-and-the-danger-of-isolating-experiments-cb0a69e09d3 (opens in new tab).
[6] Mitchell C., Drake A., Litz J., & Vaz G. p-Values for Your p-Values: Validating Metric Trustworthiness by Simulated A/A Tests. http://approjects.co.za/?big=en-us/research/group/experimentation-platform-exp/articles/p-values-for-your-p-values-validating-metric-trustworthiness-by-simulated-a-a-tests/.