

Vasilis Kontonis, Yuchen Zeng, Shivam Garg, Lingjiao Chen, Hao Tang, Ziyan Wang, Ahmed Awadallah, Eric Horvitz, John Langford, Dimitris Papailiopoulos

We taught models to compress their own chain-of-thought mid-generation. Peak KV cache drops 2–3x, throughput nearly doubles, and the erased reasoning blocks leave traces in the KV cache that the model still uses. Paper, OpenMemento dataset (228K traces), and vLLM fork all open.
If you’re too busy to read this, here’s what we found:
- You can teach a model to segment its own chain-of-thought into blocks, compress each into a dense memento, and reason forward from that. Standard SFT on ~30K examples suffices to teach this to a model.
- This cuts peak KV cache by 2–3× and nearly doubles serving throughput, with small accuracy gaps that shrink with scale and close with RL.
- Erased blocks don’t fully disappear: their information leaks forward through the KV cache representations, forming an implicit second channel without which accuracy drops significantly.
- We are releasing OpenMementos (228K annotated traces built on top of OpenThoughts-v3), the data generation pipeline, and a vLLM fork with native block masking.
The Problem: LLMs Don’t Know How to Manage their Context
It’s well established at this point that reasoning models can solve hard problems by generating a lot of tokens. Test-time compute works and has led to dramatic advances on competition-level math and coding, but it can also result in a single inference call producing hundreds of thousands of tokens. That is roughly the length of a book. All these tokens stay in memory, attended to at equal cost, whether they lead somewhere or not. The model has no built-in mechanism to compact what it has figured out, keep the conclusions, and move on.
There are ways to manage this externally, e.g., by running a separate summarizer, restart API calls with condensed context, build orchestration logic around the model. However, these are all systems bolted around the model rather than skills the model itself has learned. We think figuring out what to remember and what to forget can and should be a skill that the model learns during training.
Memento teaches language models exactly this. A Memento-trained (aka a mementified) model segments its reasoning into semantically coherent blocks. When a block is complete, the model produces a memento: a terse, information-dense compression of the block’s conclusions, key intermediate values, formulas, and strategic decisions. Think of a memento as a lemma: a minimal record of what future reasoning steps need to continue.
Once a memento is generated, the preceding thinking block is masked from attention and its KV cache entries are flushed away. From that point on, the model sees only past mementos plus whatever block it is currently working through. This means context grows while the model is reasoning through a block, but then it drops sharply once the memento is produced and the block is evicted. This gives rise to a sawtooth pattern where peak memory stays at a fraction of what a standard flat CoT trace would require. Here’s what this looks like:
Importantly, all of this happens within a single generation call, with no restarts, separate summarizers, or orchestration layers involved. The model segments, compresses, and masks its own reasoning by itself.
We applied Memento to five models: Qwen2.5-7B, Qwen3 8B and 32B, Phi-4 Reasoning (14B), and OLMo3-7B-Think. It works across all of them. Peak KV cache drops by 2-3x with small accuracy gaps that shrink with scale and close further with RL.
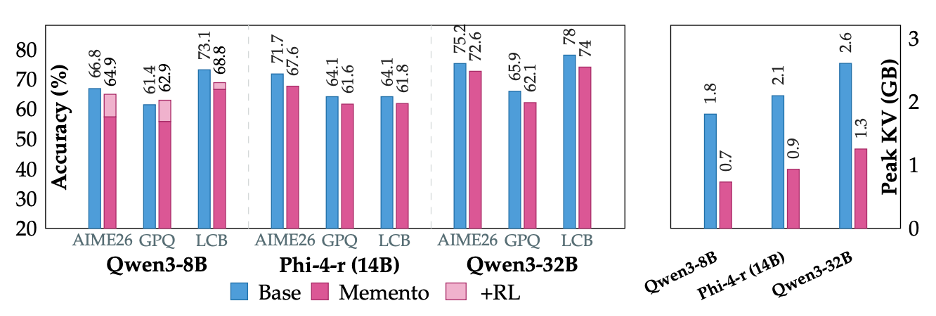
We also found something we did not anticipate: the erased blocks, although physically removed from the KV cache, don’t fully disappear from the model’s representations. More on this in a minute!
But before that, how do we train context management in a model?
How do you teach context management? Add it in the training data!
Teaching this behavior requires training data that isn’t quite common: large-scale, high-quality reasoning traces segmented into blocks, each paired with a memento that captures the block’s conclusions in a way the model can reason forward from. The intuition is straightforward: if you take reasoning traces, segment them, add proper summaries, and SFT on the result, maybe the model learns to do context management on its own.
It sounds simple, but as with many things there were several components that broke along the way and had to be fixed.
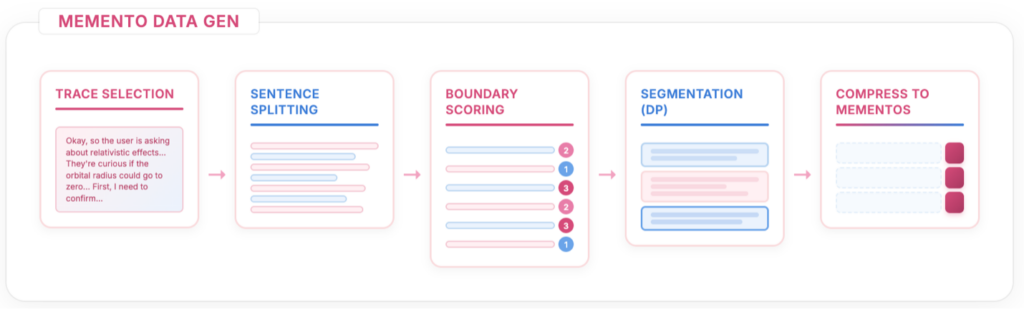
First, we decided to build on top of OpenThoughts (opens in new tab): reasoning traces generated by QwQ-32B that are already reasonably high-quality and widely used by the community, which saves us from generating everything from scratch. Now the question is: how do we go from raw traces to segmented, annotated ones with mementos at each block boundary? The challenge is that reasoning traces have no natural segment boundaries, i.e., ideas mix together, calculations span multiple sentences, and where to “cut” the CoT depends much more heavily on meaning rather than formatting, or some other obvious indicator.
We tried the obvious thing first: paste a trace into a frontier model and ask it to segment and summarize directly. This does not work! Not even if you cut the trace into pieces first, because you don’t quite know where to cut. Finding good partitions requires simultaneously reasoning about block coherence, size balance, and semantic boundaries, which is a tricky combinatorial optimization that LLMs (at least the ones we tried) struggle to do in one shot.
So we factored the problem into parts. First, we segment each trace into atomic units—sentences, code blocks, math equations—that can’t be meaningfully split further. Then an LLM scores each inter-sentence boundary from 0 (mid-thought, would break flow, i.e., bad) to 3 (major transition, natural stopping point, i.e., good). This is a local question and LLMs handle local questions very well. The global optimization of where to actually place boundaries given these scores is then handled by dynamic programming, which maximizes boundary quality while penalizing uneven block sizes. This is the kind of thing that’s (again, in our experience) hard for an LLM to zero-shot, but where good old dynamic programming just works.
Once we have our segmented traces, we now need to compress each block. A compressor LLM produces a memento for each one, and we explicitly explain in the prompt that the task is not vanilla summarization but state compression: produce something compact enough that the model could continue reasoning from the memento alone, without ever seeing the original block. And so, a memento is born!
Then, a separate judge LLM evaluates each memento across six dimensions (formulas extracted, values preserved, methods named, validation included, no hallucinations, result-first structure) and if the score falls short, the judge provides specific, actionable feedback (not “more details needed” but “missing formula: K² − 3K + 3” etc) and the compressor retries.
This iterative refinement turned out to be crucial. Single-pass compression barely hits a 28% pass rate on our rubric, because initial mementos typically miss exact formulas or intermediate values that downstream blocks depend on. Two rounds of judge feedback bring the pass rate to 92%.
Note: For all LLM calls in the pipeline we used GPT-5.x, but any sufficiently capable model should work. The full pipeline is open and we hope people use it, improve it, and build better datasets than ours.
Here is what the data gen pipeline looks like:
The final dataset, OpenMementos, contains 228K annotated traces consisting of 54% math, 19% code, 27% science problems. We measured that mementos resulted in roughly 6x trace-level compression: about 11k tokens of reasoning compacted to under 2k tokens of mementos per trace.
Here are some cool compression statistics on OpenMementos.

Training: How do we put pressure on the model?
We have annotated traces with block structure and mementos. The obvious next step is: let’s SFT on them; but how exactly? The goal is for the model to eventually reason forward from mementos alone, with the original blocks masked and their KV cache entries removed.
One option is to train with normal causal attention on the annotated traces and then just mask the blocks at inference time. This works to some extent, but it means training never puts any pressure on the model to actually pack information into its mementos, as it can always fall back on attending to the full block during training, and then at inference it’s basically on its own.
We want training to match inference: if blocks will be masked when the model is deployed, they should be masked during training too.
But training directly with block masking from the start also does not work well. The model is trying to learn three things at the same time: the block-memento format, how to compress under hard constraints, how to only rely on mementos for the next block generation. And it struggles with all three simultaneously.
What we found is that curriculum matters a lot.
Stage 1 uses standard causal attention with loss on all tokens. The model learns the format: when to end a block, how to write a memento, what structure looks like. It can still see everything, so there’s no compression pressure yet. Stage 2 then introduces the hard constraint: after each memento, the preceding thinking block is fully masked from subsequent attention. Now the model has to produce mementos that carry everything future reasoning needs, because the original blocks are gone. This is where the real learning seems to occur: the model is forced to pack more information into its mementos, almost like an RL-style pressure signal that pushes toward self-contained compression. Very cool!
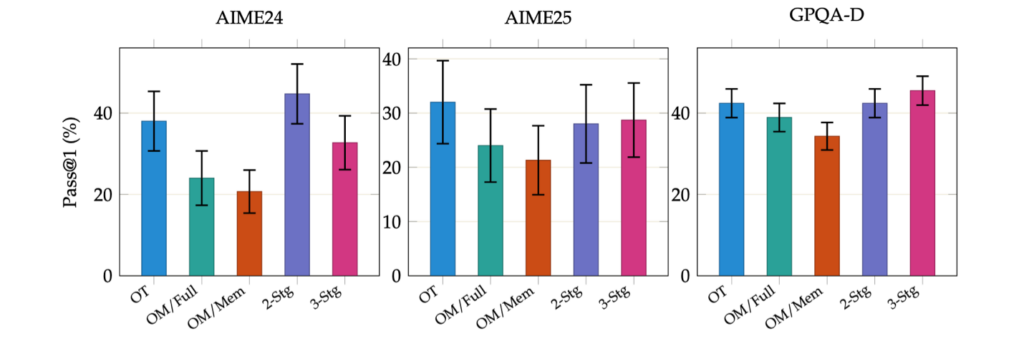
Multi-stage SFT ablation on AIME 2024, AIME 2025, and GPQA-Diamond (Pass@1, n=8, Qwen2.5-7B). OT = OpenThoughts only; OM/Full = OPENMEMENTOS Full Attention; OM/Mem = OPENMEMENTOS Memento Attention; 2-Stg = OT → OM/Full; 3-Stg = OT → OM/Full → OM/Mem (Ours). Training directly on OPENMEMENTOS from the base model (OM variants) substantially underperforms vanilla SFT (OT). Our three-stage pipeline enables block masking while retaining strong performance.
We also found, consistent with other work on teaching skills, that training on a small subset of the OpenMementos data is enough. Even ~30K samples from the 228K pool, trained for 5 epochs per stage at 32K sequence length, were sufficient for models to pick up the skill.
For models that already reason well (Qwen3, OLMo3, Phi-4-reasoning), two stages suffice; non-reasoning base models like Qwen 2.5 7B need a preliminary round of standard reasoning SFT first. Memento doesn’t require qualitatively more data than standard reasoning SFT, it just requires different kind of data.
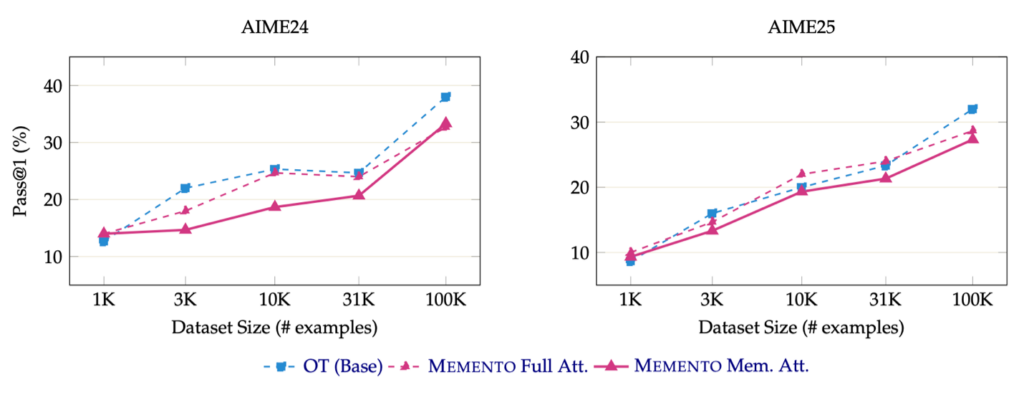
Training data scaling. Pass@1 accuracy on AIME24 and AIME25 for Qwen2.5-7B-Instruct fine-tuned on 1K–100K examples. All methods improve monotonically with data size.
How does compaction affect accuracy?
The first obvious concern with Memento is that attending to fewer tokens should hurt accuracy. And when we first looked at the numbers, there was indeed a drop. Where does it come from?
Our initial reaction was that it must be due to compaction and sparsity: the model is seeing far less context, so of course it gets worse. But then we ran control studies, and the picture turned out to be more interesting.
The key insight is that we train on OpenThoughts traces generated by QwQ-32B, which is a different and often weaker model than the ones we are fine-tuning. Several of our target models were released after QwQ and are arguably stronger. So we ran a control: take each base model, SFT it on the same raw OpenThoughts traces (no block structure, no mementos), and measure the accuracy drop from that alone. It turns out that just doing SFT on another model’s reasoning traces already costs you something. When we compare Memento against that control rather than the untouched baseline, the additional drop from compression is small, and in some cases negligible.
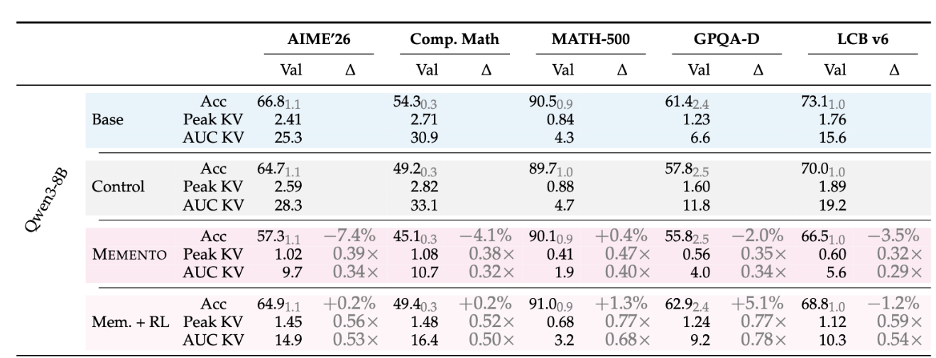
But we were still curious about whatever accuracy gap remained. So we asked: can the model still solve the same problems?
To test that, we generated 64 completions per problem across all three model families on AIME 2024/25/26, and the answer is overwhelmingly yes. The overlap between the problems solved by the base model and by Memento averages 96.4%, hitting 100% in some settings. The model retains the capability to solve these problems and what drops is the consistency of solving them on any single attempt.
This is an important distinction because it likely implies the gap is closable. For example we found that even majority voting at k=3 is enough for the Memento model to match not just the control but the original baseline. This confirms that the capability is still there in the distribution.
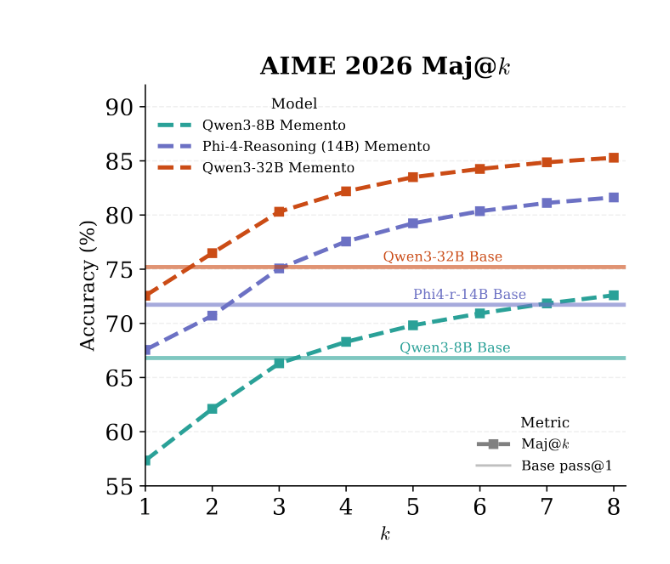
The natural next step was RL. And unsurprisingly it works: fine-tuning the Qwen3-8B Memento checkpoint with CISPO recovers AIME’26 and GPQA-Diamond scores (sometimes actually exceeding the vanilla baseline), while the KV savings remain substantial after RL.
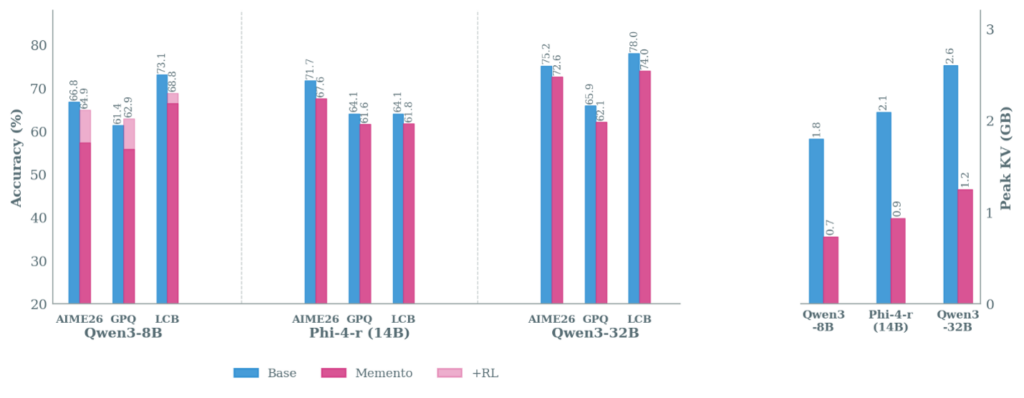
Scale also helps independently, even without RL. Going from Qwen3-8B to 32B, the gap shrinks considerably even though both models are trained on the same QwQ-32B traces: the larger model handles the distribution mismatch and the effects of compression more gracefully.
So the bottom line is: compression preserves capability, any consistency loss traces primarily to training data mismatch rather than a fundamental limitation, and both RL and scale close the gap further.
The Dual Information Stream
Early in the project, there were a lot of discussions about how inference should actually work. The simplest approach, and the one that would make our lives much easier, is restarts: every time a memento is produced, kill the KV cache and start a fresh API call with just the accumulated memento text. No need to implement non-causal sparse attention inside vLLM, which turned out to be a huge pain. Just restart the call.
But we kept coming back to a concern: when a memento is generated, the model can still see the full thinking block and therefore memento tokens attend to block tokens during their own generation. The block is only masked after the memento is complete. This means the KV cache entries for the memento were computed as a function of the block’s content. So even after the block text is gone, something from it survives in the memento’s KV representations. If the next block attends to the memento, it’s attending in an indirect way to this implicit, soft representation of what came before. In a restart setup, you throw all of that away.
That is to say, there is non-trivial information about masked blocks that survives in the KV cache representations, beyond what the actual memento tokens capture. So a question kept bothering us: does this implicit information channel actually matter for accuracy, or are we overthinking it?
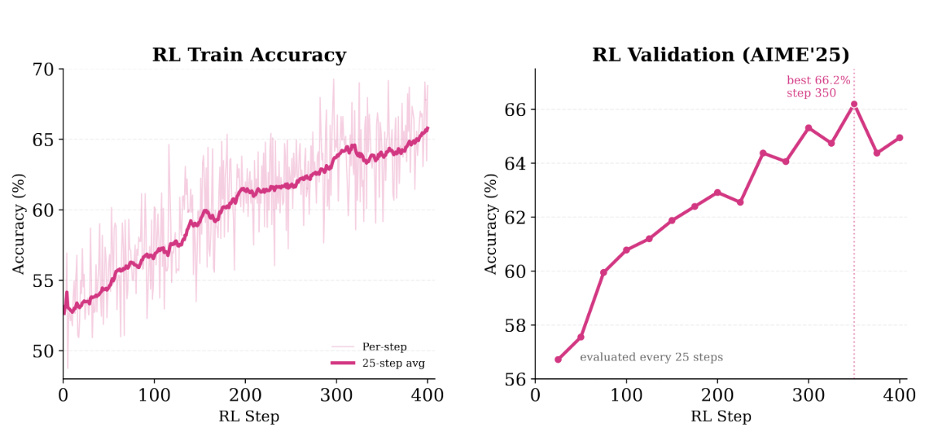
And so we ran an ablation. Take the same Qwen3-8B checkpoint, compare normal Memento inference (mask blocks but keep the memento KV states intact) against restart mode (recompute the entire KV cache from scratch at each memento boundary, so the mementos themselves never attended to their blocks). The restart mode drops AIME’24 from 66.1% to 50.8%. Fifteen percentage points which to any reasonable observer does not register as noise. It in fact strongly suggests that the side information channel flowing through the KV representations matters a great deal. Just to be sure, we wanted to test this hypothesis further.
So we designed a simple experiment: take a model, inject a random 5-digit passcode into a target block, mask that block, and train linear probes on the KV states of downstream mementos that never directly attended to the masked block. Can you recover a piece of information that exists only in the implicit KV channel, not in any memento text?
Oh, yes, yes you can! The probes reconstruct the passcode well above chance, precisely because of information leakage that happens through the KV states. This leakage concentrates in deeper layers, decays with distance from the target block, but remains detectable even seven blocks away, and scales with model capacity.
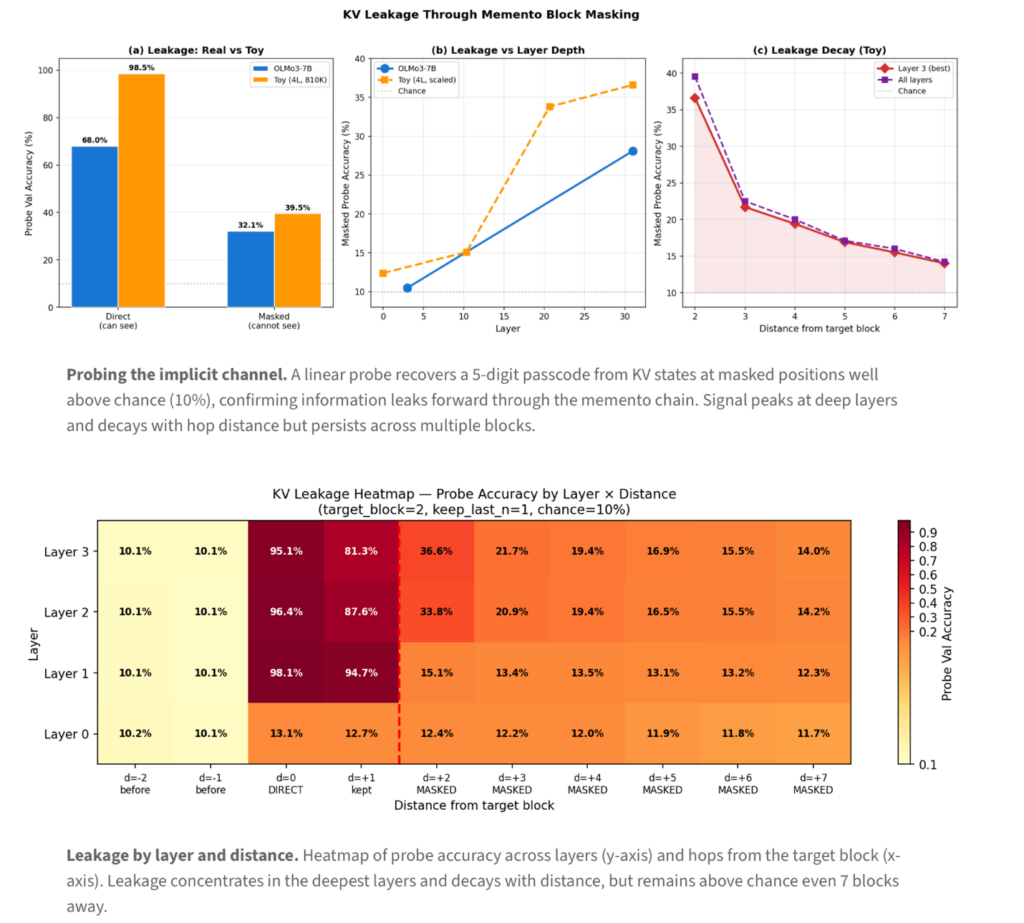
We also verified this on a small controlled toy transformer (4 layers, 810K parameters), where the leakage is constant across training checkpoints even as task accuracy improves from 77% to 95%. This is an architectural consequence of residual connections, causal attention, and in-place masking.
We believe this distinguishes Memento from approaches like InftyThink and Accordion-Thinking, which discard original tokens and rebuild context from summary text alone and lose this implicit channel entirely. And it is what convinced us to do the hard infrastructure work of implementing proper block masking inside vLLM rather than taking the infra-wise easier restart path.
Making Memento work in vLLM
Memento’s block masking is data-dependent and keeps changing during generation, since which tokens to mask depends on what the model produces. No production inference framework supported this out of the box, unfortunately. We started with a HuggingFace backend, which was enough to validate that block masking and keeping everything in a single inference call actually helps, but once we were convinced, it was clear we needed to build this properly inside vLLM.
That turned out to be painful but, in the end, doable. The key design choice was physical KV cache compaction rather than logical masking: when a block completes, its KV entries are physically flushed and the freed slots are returned to the KV pool. This means standard FlashAttention and paged-attention kernels work completely unmodified as they never see the evicted tokens. The implementation operates purely at the vLLM Python level and can be installed as a patch on top of an existing vLLM installation.
On a single B200 GPU with 240 concurrent requests (Qwen3-8B, 32K max tokens), Memento sustains 4,290 tok/s versus 2,447 for vanilla (1.75× throughput) and completes the batch in 693s versus 1,096s. The gains come from freeing KV entries as blocks complete, allowing the engine to sustain higher batch sizes in regimes where vanilla vLLM becomes KV-cache-bound.
This infrastructure also turned out to be essential for RL: generating 32K-token training rollouts requires block masking during generation, with each rollout producing and compacting blocks on the fly. Without the vLLM fork, RL at this scale would not have been feasible.
What’s next?
Two things seem natural from here. First, scaling the RL recipe: our results with Qwen3-8B are early, and the pass@64 analysis makes it clear there is a lot of headroom for improvement. Larger models with more RL compute should take us to interesting places.
Second, and more importantly to us: agents. Memento was built for mathematical, coding, and science reasoning as a test case, not because we think single-turn math and coding are the most interesting applications. The block-and-compress pattern maps onto any setting where a model accumulates a long trajectory of intermediate state and limited context windows become the bottleneck. Terminal and CLI agents are naturally multi-turn, where each action-observation cycle is laid out as a natural block, and the ability to selectively remember and forget is exactly what seems missing (at least from OSS models/agents). Recent work on context compaction in agentic settings (e.g., from Anthropic and OpenAI) points in the same direction, and we think there is a ton of room to explore here.
Coda
Memento started as an attempt to teach models to compact their own reasoning. That indeed works: 2-3x KV reduction, accuracy largely preserved while throughput nearly doubled. But we came away from this project with two insights that feel more important than the efficiency gains.
The first is that context management can be taught through standard training on the right data. A model that had no concept of blocks or summaries can, after SFT on ~30K examples, learn to segment its own reasoning, compress each segment, and continue from the compressed version. This is a non-trivial, non-causal skill involving sparse attention, selective forgetting, state compression, that was acquired through entirely conventional training. We think there in fact is a much wider space of unconventional capabilities that can be taught this way.
The second is the dual information stream supported by both hard tokens and their KV representations. When you mask a block inside a single forward pass, the block’s information doesn’t quite vanish: it persists in the KV representations of the mementos that were computed while the block was still visible. This is both useful and architecturally unavoidable, and we don’t yet know how far this implicit channel can be pushed, especially with RL.
These two pieces point in the same direction: memory management should be a learned capability, and models can learn with less effort than we expected.
We think Memento is a first step, and there is a long way to go, with better training data, stronger RL, and agent applications. We are continuing work across all of these, and along the way we are releasing OpenMementos (228K annotated reasoning traces), our full data generation pipeline, and the vLLM fork with native block masking.
In the meantime, stop flushing your KV cache. Your model remembers more than you think.
Paper (opens in new tab) · Code (opens in new tab) · Dataset (opens in new tab)