

In industry today, research and development (R&D) plays a pivotal role in boosting productivity, especially in the AI era. However, the rapid advance of AI has exposed the limitations of traditional R&D automation methods. These methods often lack the intelligence needed to address the demands of innovative research and complex development tasks, falling short of producing solutions comparable to those devised by human experts. In contrast, experienced researchers rely on deep knowledge to propose new ideas, validate hypotheses, and refine processes through iterative experimentation.
The emergence of large language models (LLMs) offers a way to overcome these challenges and transform data-driven R&D. Trained on vast datasets spanning a wide range of subjects, LLMs are equipped with extensive knowledge and reasoning capabilities that support complex decision-making and enable LLMs to act as intelligent agents in diverse workflows. By autonomously performing tasks and analyzing data, LLMs can significantly increase the efficiency and precision of R&D processes.
LLMs infuse R&D with new intelligence
Researchers from Microsoft Research Asia believe that LLMs hold tremendous potential for advancing innovative research. Their extensive knowledge base enables the generation of novel ideas and hypotheses, while their reasoning abilities facilitate the exploration of new experimental paths and methodologies, driving continuous innovation.
In development, LLMs excel at processing and analyzing data, extracting insights, and identifying patterns. They can also create or leverage agentic tools to handle repetitive and complex tasks, greatly accelerating the development process.
To this end, researchers have developed RD-Agent, an automated research and development tool powered by LLMs. By integrating data-driven R&D systems, RD-Agent harnesses advanced AI to automate innovation and development.
At the heart of RD-Agent is an autonomous agent framework composed of two key components: Research and Development. Research focuses on actively exploring and generating new ideas, while Development implements these ideas. Both components improve through an iterative process, illustrated in Figure 1, ensures the system becomes increasingly effective over time.
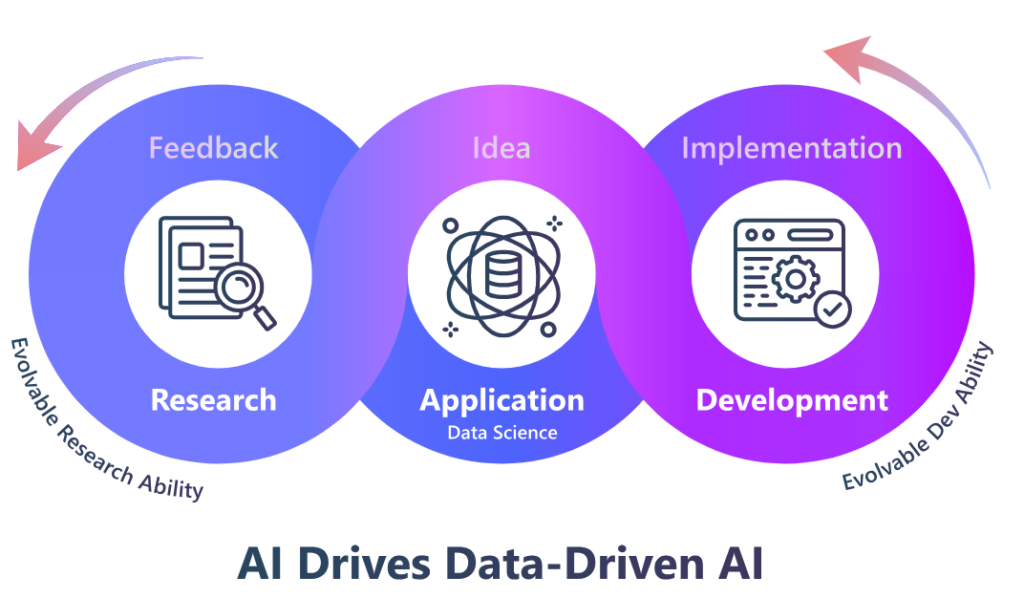
In practical applications, RD-Agent can perform a variety of functions. It acts as your productive research copilot, following your instructions to automate repetitive tasks, or as a more autonomous data-mining agent, actively proposing ideas to help you achieve better results.
The following are demonstration scenarios supported by RD-Agent, showcasing its capabilities from general research assistance to specialized data intelligence development in various professional fields:
- General research assistant (opens in new tab): Automatically reads research papers or reports and implements model structures.
- Data pattern identifying: Automatically explores and implements model structures to identify patterns in data from fields like finance (opens in new tab) and healthcare (opens in new tab).
- Automated quant factory (opens in new tab): Fully automates time-consuming feature engineering tasks in complex real-world systems.
RD-Agent is now open source on GitHub (opens in new tab), and researchers from Microsoft Research Asia are continuously updating and expanding its features to support more methods and scenarios. These ongoing efforts aim to optimize the development process and boost productivity.
Key challenges and technical innovations
Simply applying LLMs to R&D scenarios fails to yield significant industrial value. To achieve the transformative impact of automating data-driven R&D and harness the capabilities of LLMs, we must address two key challenges: continuous evolution capability and specialized knowledge acquisition.
Current LLMs struggle to expand their capabilities after the initial training phase, and their focus on general knowledge coupled with a lack of depth in specialized knowledge, becomes an obstacle to solving professional R&D problems. Specialized knowledge must be acquired through in-depth industry practice.
To address these challenges, RD-Agent incorporates a dynamic learning process that integrates real-world practice and feedback. This enables in-depth domain knowledge to be continuously acquired through deep exploration during the R&D phase.
To support this, researchers have proposed basic methods across three aspects: research, development, and benchmarking.
Research: Investigating new ideas and refining them through feedback
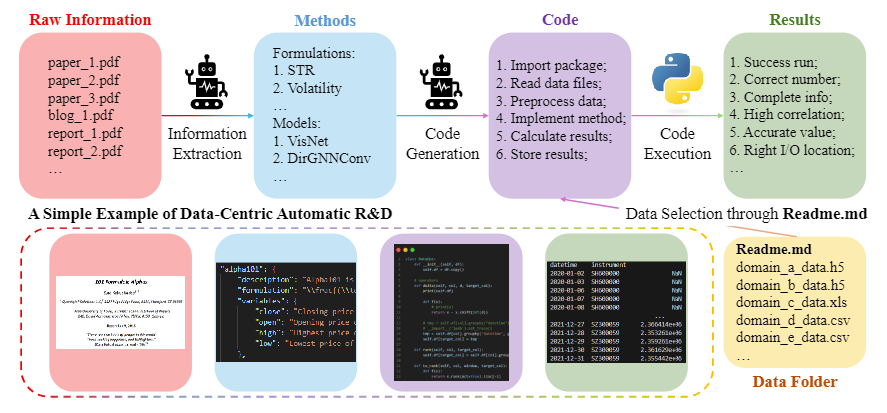
In the R&D process, proposing and validating new ideas are fundamental components of research. For example, a data mining expert might hypothesize that a model structure like RNN can capture patterns in time-series data. They would design experiments (e.g., testing the hypothesis on financial data), implement the model experiments as code (e.g., using PyTorch), execute the code, and analyze feedback (e.g., metrics, loss curves) to guide improvements for subsequent iterations. This process is illustrated in Figure 2.
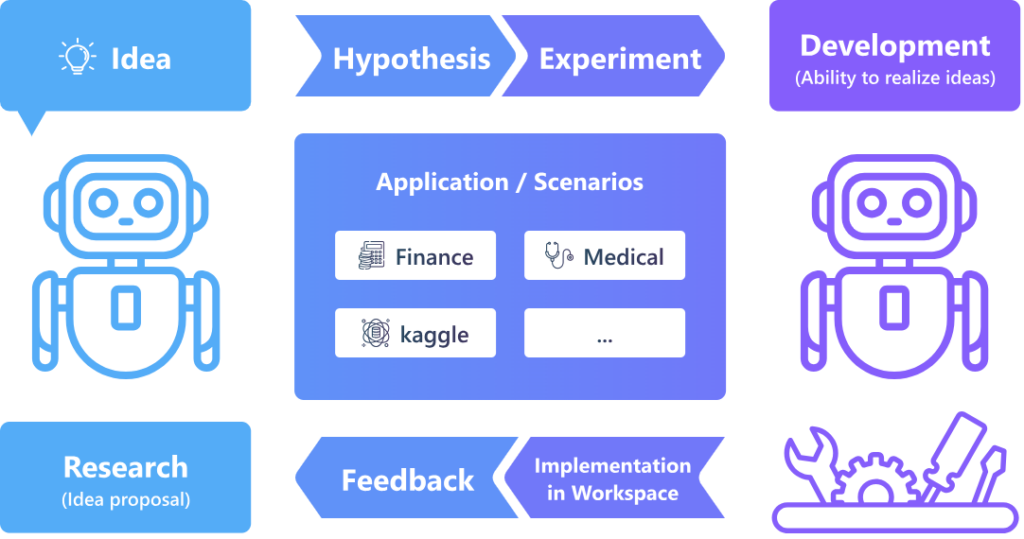
Inspired by these general principles, RD-Agent focuses on proposing new hypotheses or refining existing ones, designing and implementing experiments, and analyzing feedback. By establishing a continuous feedback loop, hypotheses are consistently proposed, verified, and refined based on real-world practice. RD-Agent is the first framework that supports linking scientific research automation with real-world verification. It incorporates knowledge management, allowing the agent to continuously verify, acquire, and accumulate knowledge during exploration, much like human experts. Over time, this deep understanding of scenarios enables the development of more optimal solutions.
Development: Efficiently implementing and executing ideas
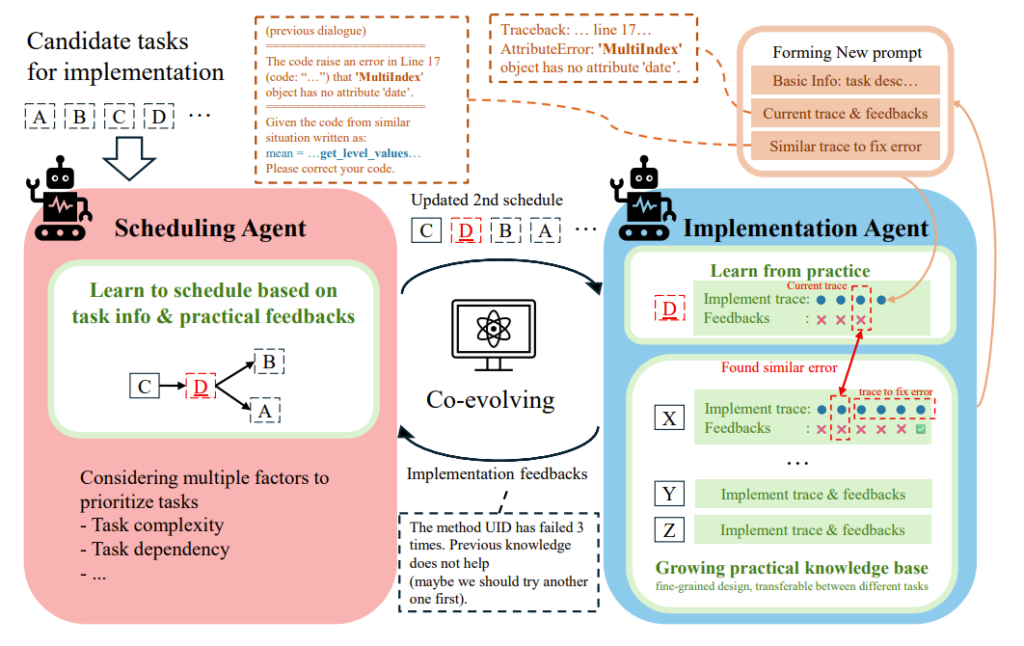
The development process emphasizes efficiently implementing research outcomes while maximizing benefits by effectively prioritizing tasks. To address this, researchers have introduced Collaborative Knowledge-STudying-Enhanced Evolution by Retrieval (Co-STEER), a data-centric development solution, as a key component of RD-Agent. Co-STEER starts with simple tasks and progressively enhances development strategies through continuous learning, using ongoing feedback to optimize its efficiency. This process is shown in Figure 3.
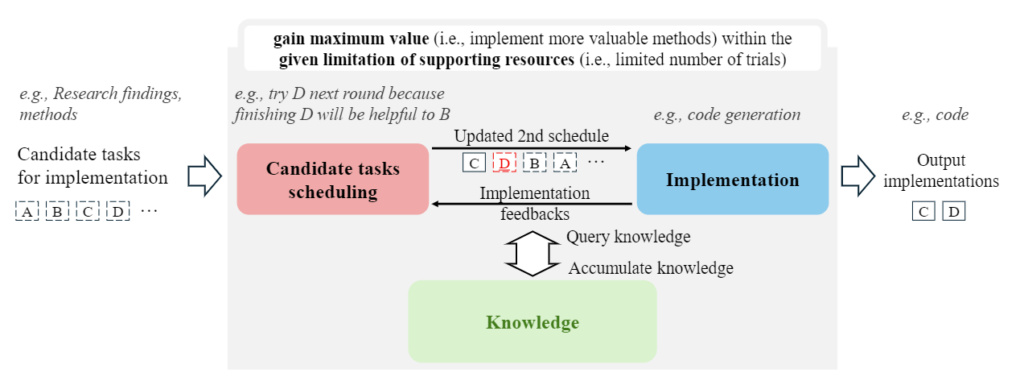
By enhancing domain knowledge through evolving strategies and practical experience, the Co-STEER agent improves its scheduling and implementation skills. This collaborative evolution process ensures faster and more accurate implementation by using detailed feedback to refine both scheduling and strategies. Learn more about Co-STEER in our paper (opens in new tab).
Benchmark: Developing a new benchmarking system to assess agents’ R&D capabilities
Researchers have developed a comprehensive benchmark called RD2Bench (opens in new tab), designed to evaluate the capabilities of LLM-Agents in model and data development through a series of tasks ranging from data construction to model design.
For model development evaluation, researchers extract information from papers on model structure design, summarize implementation details using mathematical formulas and text, and provide this as input to the development agent. For data development evaluation, they identify the construction of financial features (factors) as a typical and knowledge-dense scenario. Implementation formulas and descriptions of these factors are extracted from publicly available research reports and used as input for the development agent. Each task has a manually implemented correct version, serving as the basis for evaluating the quality of the model and data construction results. This process is illustrated in Figure 5.
Unlocking the full potential of LLMs
Looking ahead, efficiently automating data science research remains an open question. Additionally, fully unlocking the innovative potential of LLMs to enable cross-domain and cross-disciplinary knowledge transfer, integration, and innovation is a significant challenge. During the development process, automating the understanding of feedback, integrating it with the current development level, and intelligently scheduling and prioritizing tasks to enhance foundational models as agents—these are all critical and challenging research directions.
To address these challenges, the key lies in fostering the simultaneous enhancement of research and development capabilities through practical feedback, enabling their co-evolution. This integrated approach can significantly boost the innovative capacity of LLMs, driving cross-domain and cross-disciplinary knowledge transfer while improving R&D efficiency and quality. Ultimately, it aims to achieve a transformative leap in automated research and development.
Resources
Explore the RD-Agent
View RD-Agent demos
- Continuous Exploration
- Guided Implementation