

Authors:
Tommy Guy, Allie Giddings, Chhaya Methani
Microsoft Dynamics 365 Supply Chain Insights is a new product that helps predict risks and manage your supply chain through three main functions.
- It increases visibility of risks affecting your supply chain.
- It provides analytics on your digital twin that can help you address risks.
- It enables collaboration with your suppliers to act on the visibility and analytics.
The AI in Supply Chain Insights is infused with the product’s main functions to accelerate risk identification and mitigation. In this blog post, we’ll focus on how surfacing relevant news articles about suppliers and warehouses helps increase the visibility of risks and empower you to collaborate with your partners to reduce the risk. We will cover how our model works and why you can trust the results, so you can have more confidence in your news feed in Supply Chain Insights.
What are relevant news articles for Supply Chain?
Smart news will filter news articles to those most relevant to suppliers in your supply chain and your own company. The model finds news related to supply chain topics such as:
- Product News
- Quality News
- Workforce News
- Infrastructure News
- Politics and Government News
- Location Health
- Sustainability News
- Disruption and Disaster News
By filtering to these topics, you can have a news feed that only shows important information affecting your supply chain. Here’s an example of how these articles are surfaced in Supply Chain Insights.
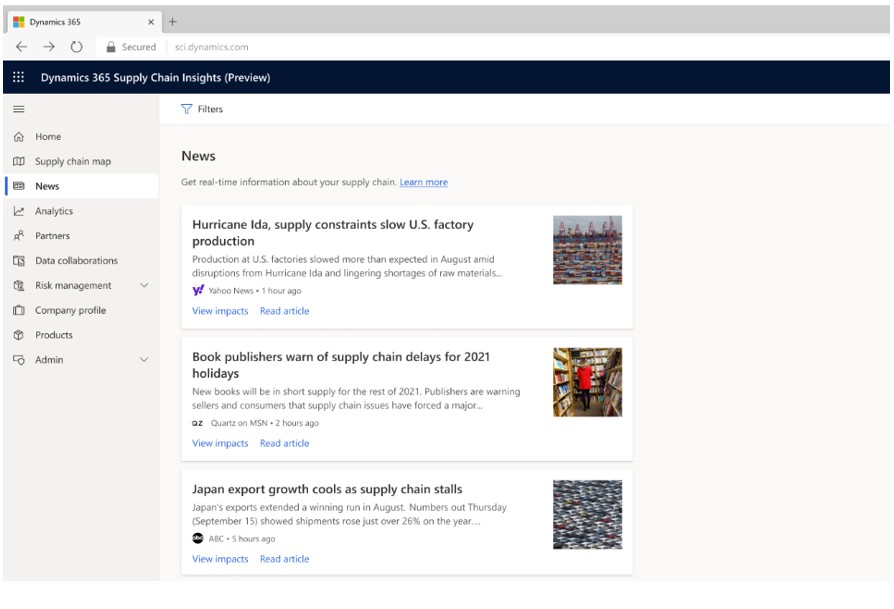
Figure 1: Example of how articles are surfaced in Supply Chain Insights.
What does the model do?
The model uses data you have uploaded to Supply Chain Insights in the Vendors table, and your company name in the company profile section to query Bing News for articles. These articles from Bing News are passed to the model, where it scores each article on how relevant it is from 0 to 1 with higher scores being more relevant. Only articles with a score higher than 0.5 are shown in the news feed, and the articles are ordered by the relevance score from highest to lowest.
What data does the model use to learn?
The model is trained on news articles from recent months with a label for whether each article is relevant or not. The news articles are generated by querying the news API with a broad list of companies to get news that cover a broad range of topics (that were listed above). The labels for if each article is relevant or not are created using simple rules since there are too many articles for humans to label. For example, we could have a simple rule to label the article as relevant if it contains the words “supply chain.”
How does the model learn?
We use a Random Forest model, which is an ensemble of Decision Trees. Ensemble methods combine multiple individual models to make a prediction, which often makes them more robust to noise in the training data. Decision Tree models learn by grouping data into different sets based on feature values and predicting a confidence score based on the average of the data in that group. For example, you could group data into two groups based on if the source of an article is a spam or junk domain. Here’s an example diagram of a simple Decision Tree model:
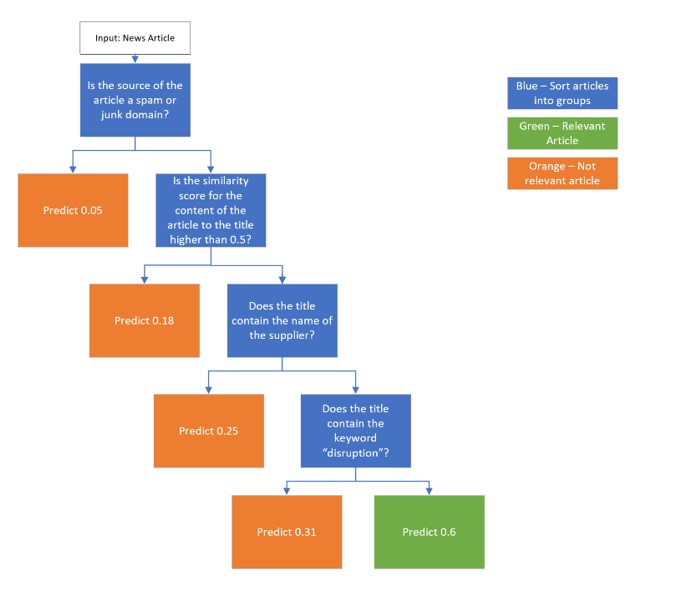
Figure 2: Decision Tree model
Note: This is not the actual model, but an illustrative example of what one tree could look like out of the many trees that together complete the Random Forest.
What features does the model use?
The model learns to deal with the ambiguity inherent in the news articles by using the following feature areas:
- Company name matches in article
- Avoiding click bait titles
- Penalizing cases when the article is not relevant to the title.
- Filter out spammy and junk domains
- Ensure high quality sources
- Similarity to supply chain domains
- Sentiment expressed in the article, which can be positive, negative, or neutral.
We use powerful, state-of-the-art language models developed by Microsoft Research. These pre-trained language models are used to create scores that tell how similar the title and content of an article are to different topics such as a natural disaster or port capacity issues.
How is the model evaluated?
The model is evaluated on test datasets with metrics. First, the model makes a prediction for every news article in the test dataset. These predictions are compared to the expected label and each news article will be a false positive, true positive, false negative, and true negative.
- A false positive is a news article that was predicted as relevant but should not have been predicted as relevant.
- A true positive is a news article that was predicted as relevant and was supposed to be relevant.
- A false negative is a news article that was predicted as not relevant but should have been predicted as relevant.
- A true negative is a news article that was predicted as not relevant and was supposed to not be relevant.
Now that we know for each article if it is a false positive, true positive, false negative, or true negative we can calculate the precision and recall metrics to evaluate how good the model is. Precision is a measure of how accurate the model is, while recall is a measure of the coverage of the model.
Precision = # of true positives/ (# of true positives + # of false positives)
Recall = # of true positives/ (# of true positives + # of false negatives)
How can I trust the results?
We validate the model results on test datasets. These test datasets are not shown to the model during training, so we can be confident the model didn’t learn patterns specific to the test datasets. This ensures the model isn’t overfitting to a dataset and can generalize to more types of news articles. For more information about overfitting, check out our previous post, Intro to Machine Learning in Customer Insights. Test datasets are created by the development team and are a sample set of suppliers.
Supply Chain News Model in Supply Chain Insights
In Supply Chain Insights, customers can see news that impacts their partners and collaborate with them to reduce risk surfaced from the news. These news articles are selected from a machine learning model so only the most important information is surfaced, leaving the noise out. We presented information to help you understand how relevance is determined to be able to act on risks to your supple chain more effectively. Relevance is determined by a Random Forest model which learns to predict a relevance score based on features and historical data. The model performance is validated by test sets and reviewed by the team to ensure high quality.
Check out our documentation for more information on this news feature and Supply Chain Insights. Please send any feedback on news article relevance to scinewsfeedback@microsoft.com.