
Today we are making available an interactive real-time gameplay experience in Copilot Labs. Head over to this link (opens in new tab) to play an AI rendition of Quake II gameplay, powered by Muse.
Example generations from our WHAMM model showcasing Quake II gameplay.
What are we doing?
Muse is our family of world models for video games at Microsoft. Following on from our announcement of Muse in February, and the World and Human Action Model (WHAM) that was recently published in Nature (opens in new tab), we introduce a real-time playable extension of our model. Our approach: WHAMM which stands for World and Human Action MaskGIT Model (pronounced WHAM, the M is silent – yes this is intentionally silly) allows generating visuals much faster than WHAM. This means that you can interact with the model through keyboard/controller actions and see the effects of your actions immediately, essentially allowing you to play inside the model.
What has changed?
Since the release of WHAM-1.6B, our first WHAM trained on Bleeding Edge, we have changed and improved on a number of aspects that affect the overall experience.
- First and foremost we have improved the speed of generation. WHAMM is able to generate images at 10+ frames a second, enabling real-time video generation. In contrast WHAM-1.6B can generate about 1 image a second.
- The WHAMM recipe successfully transferred to a new game: Quake II. (We teased an earlier variant of the WHAMM model trained on Bleeding edge here (opens in new tab)). In comparison to Bleeding Edge, Quake II is a faster-paced first person shooter game which plays very differently.
- Transferring to a new game was made possible by substantially reducing the quantity of data that we required for training WHAMM. This was achieved through more intentional data collection and curation, resulting in only 1 week of data being used for WHAMM training. This is a substantial decrease from the 7 years of gameplay that we used to train WHAM-1.6B. This was made possible by working with professional game testers to collect the data, and by focusing on a single level with intentional gameplay ensuring we collected enough high quality and diverse data.
- Lastly, we doubled the resolution of WHAMM’s output, increasing it to 640×360 – WHAM-1.6B used 300×180. We found this was possible with only minor modifications to the image encoder/decoder, but resulted in a large bump in perceived quality of the overall experience. To accomplish this, we simply increased the patch size of the ViT to 20 (up from 10) which allowed us to keep the number of tokens roughly the same.
WHAMM architecture
In order to enable a real-time experience, we changed our modelling strategy. Moving from an autoregressive LLM-like setup, where WHAM-1.6B would generate 1 token at a time, to a MaskGIT [2] setup allows us to generate all of the tokens for an image in as many generations as we want.
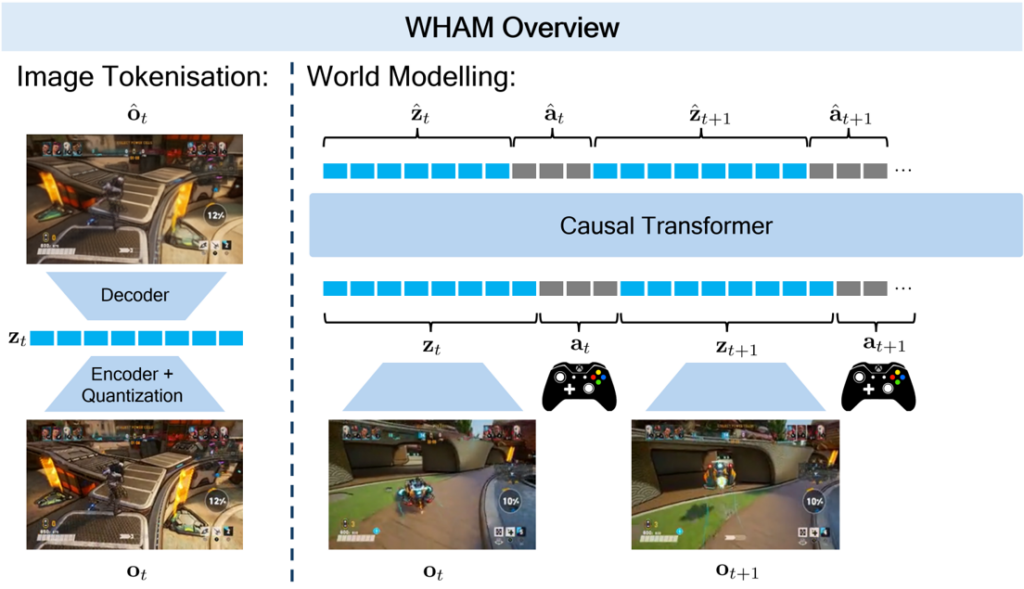
Figure 1: WHAM overview. WHAM first tokenises our gameplay data of image, action, image, action, etc sequences into a longer sequence of tokens. Then we train a decoder-only transformer to predict the next token in the sequence. Left: We tokenise each image using a ViT-VQGAN [3]. Right: We train a transformer on the resulting sequence of tokens. Please refer to our blog post and the Nature article (opens in new tab) for more details on WHAM.
An overview of the WHAM setup is shown in Figure 1. On the left, we utilise a Vit-VQGAN [3] to tokenise the image. On the right, we model that new sequence of tokens utilising a decoder-only transformer. Much like an LLM, it is trained to predict the next token in the sequence. Please refer to our paper (opens in new tab) [1] for more details.
An overview of the WHAMM architecture is shown in Figure 2. Shown on the left, exactly like WHAM, we first tokenise the image. For this specific setting each 640×360 image is turned into 576 tokens (for WHAM each 300×180 was turned into 540 tokens). Since WHAM generates 1 token at a time, generating the 540 tokens necessary to turn into an image can take a long time. In contrast, a MaskGIT-style setup can generate all of the tokens for an image in as few forward passes as we want. This enables us to generate the image tokens fast enough to facilitate a real-time experience. Typically, in a MaskGIT setup you would start with all of the tokens for an image masked and then produce predictions for each and every one of them. We can think of this as producing a rough and ready first pass for the image. We would then re-mask some of those tokens, predict them again, re-mask, and so on. This iterative procedure allows us to gradually refine our image prediction. However, since we have tight constraints on the time we can take to produce an image, we are very limited in how many passes we can do through a big transformer.
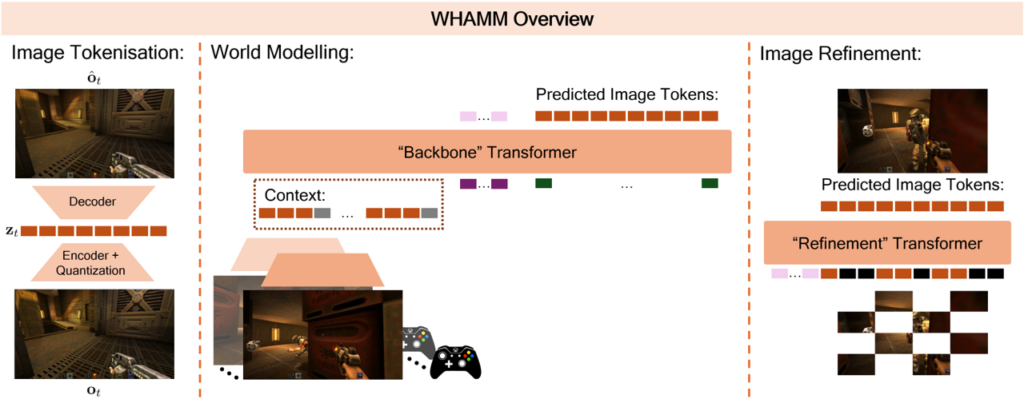
Figure 2: WHAMM overview. Left: We tokenise each image using a ViT-VQGAN, exactly like WHAM. Middle: The Backbone transformer takes in the context, the 9 previous image-action pairs, and predicts the tokens for the next image. Right: The Refinement transformer iteratively refines the image token predictions by repeatedly masking and predicting them [2].
To work around this, we adopt a two-stage setup for WHAMM. First, we have the “Backbone” transformer (~500M parameters), shown in the middle of Figure 2. This module takes as input the context (in our case this is the tokens of the 9 previous image-action pairs) and produces an initial prediction for all the tokens of the image. Next, shown on the right of Figure 2, we have a separate “Refinement” transformer which is responsible for refining our initial predictions for the image tokens. This module is both smaller in terms of size (~250M parameters), and also takes in substantially fewer tokens as input, allowing it to run much faster. This allows us to do many iterative MaskGIT steps to ensure a better final prediction. To ensure the Refinement module has the necessary information from the context available, instead of directly conditioning on the context tokens (as the Backbone transformer does) it takes as input a smaller set of “conditioning” tokens from the output of the bigger backbone transformer (shown in pink in Figure 2).
Quake II WHAMM
The fun part is then being able to play a simulated version of the game inside the model. After the release of WHAM-1.6B only 6 short weeks ago, we immediately launched into this project on training WHAMM for a new game. This entailed both gathering the data from scratch, refining our earlier WHAMM prototypes, and then the actual training of both the image encoder/decoder and the WHAMM models.
A concerted effort by the team resulted in both planning out what data to collect (what game, how should the testers play said game, what kind of behaviours might we need to train a world model, etc), and the actual collection, preparation, and cleaning of the data required for model training.
Much to our initial delight we were able to play inside the world that the model was simulating. We could wander around, move the camera, jump, crouch, shoot, and even blow-up barrels similar to the original game. Additionally, since it features in our data, we can also discover some of the secrets hidden in this level of Quake II.
Figure 3: A video from our internal research prototype portal demonstrating one of the “secret” areas in Quake II’s first level.
We can also insert images into the models’ context and have those modifications persist in the scene.
Figure 4: An example of inserting an object into the world and then being able to interact with it. This is from the end of this video (opens in new tab), showing power cell insertion into a WHAMM trained on Bleeding Edge.
Limitations
Whilst we feel it is incredibly fun to play a simulated version of the game inside the model, there are of course limitations and shortcomings of our current approach.
The most important of which is this is a generative model. Thus, we are learning an approximation to the real environment whose data it was trained on. We do not intend for this to fully replicate the actual experience of playing the original Quake II game. This is intended to be a research exploration of what we are able to build using current ML approaches. Think of this as playing the model as opposed to playing the game.
Enemy interactions. The interactions with enemy characters is a big area for improvement in our current WHAMM model. Often, they will appear fuzzy in the images and combat with them (damage being dealt to both the enemy/player) can be incorrect. Whilst the entire experience is not 100% faithful to the original environment, this aspect of it is particularly noticeable since the enemies are one of the primary things the player will interact with.
Context length. In our current model the context length is 0.9 seconds of gameplay (9 frames at 10fps). This means that the model can and will forget about objects that go out of view for longer than this. This can also be a source of fun, whereby you can defeat or spawn enemies by looking at the floor for a second and then looking back up. Or it can let you teleport around the map by looking up at the sky and then back down. These are some examples of playing the model.
Counting. The health value is not always super reliable. In particular, counting doesn’t always work fantastically. This can affect the interactions with the health packs and with enemies.
Scope of the experience is limited. At the moment, WHAMM is only trained on a single part of a single level of Quake II. If you reach the end of the level (going down the elevator), then the generations freeze because we stopped recording data at that point and restarted the level.
Latency. Making WHAMM widely available for anybody to try at scale has introduced noticeable latency into the actions.
Future work
This WHAMM model is an early exploration of real-time generated gameplay experiences. As a team we are excited about exploring what new kinds of interactive media could be made possible by these kinds of models. We highlight the limitations above not to take away from the fun of the experience, but to bring attention to areas in which future models could be improved, enabling new kinds of interactive experiences and empowering game creators to bring to life the stories they wish to tell.
Contributions
This was a big joint-team effort involving Game Intelligence, Xbox Gaming AI, and Xbox Certification Team. These contributions focus just on the data and model training pipeline.
Model Training.
Tabish Rashid. Victor Fragoso. Chuyang Ke.
Data/Infrastructure.
Yuhan Cao. Dave Bignell. Shanzheng Tan. Lukas Schäfer. Sarah Parisot. Abdelhak Lemkhenter. Chris Lovett. Pallavi Choudhury. Raluca Stevenson. Sergio Valcarcel Macua. Andrew Donnelly.
Advisory.
Daniel Kennett. Andrea Treviño Gavito.
Project Management.
Linda Wen. Jason Entenmann.
Project Leadership.
Katja Hofmann. Haiyan Zhang.
References
[1] Kanervisto, Anssi, et al. “World and Human Action Models towards gameplay ideation.” Nature 638.8051 (2025): 656-663.
[2] Chang, Huiwen, et al. “Maskgit: Masked generative image transformer.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
[3] Yu, Jiahui, et al. “Vector-quantized Image Modeling with Improved VQGAN.” International Conference on Learning Representations 2022.

