
This research paper was presented at the 17th USENIX Symposium on Operating Systems Design and Implementation (opens in new tab) (OSDI), a premier forum for discussing the design, implementation, and implications of systems software.

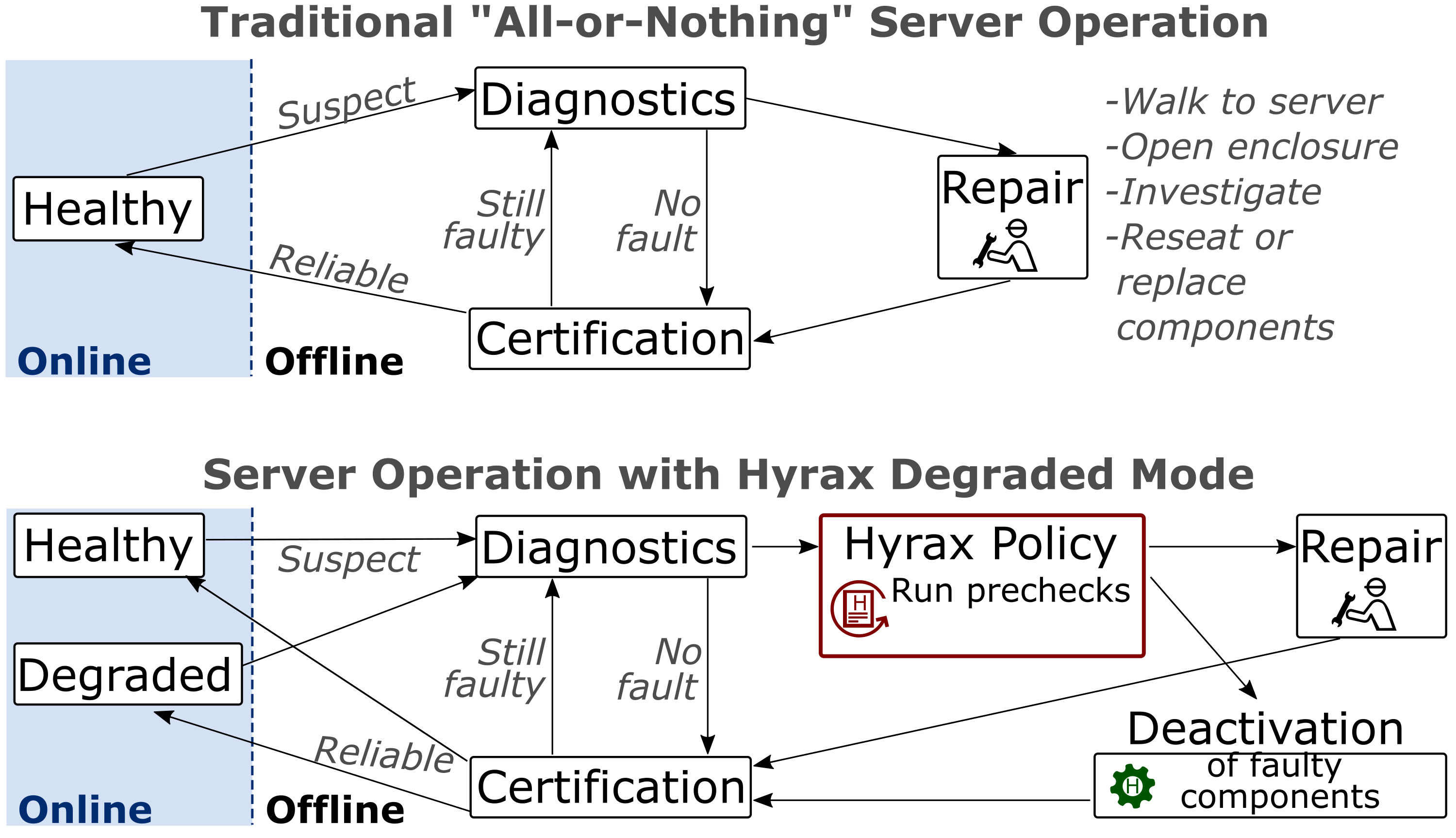
Cloud platforms aim to provide a seamless user experience, alleviating the challenge and complexity of managing physical servers in datacenters. Hardware failures are one such challenge, as individual server components can fail independently, and while failures affecting individual customers are rare, cloud platforms encounter a substantial volume of server failures. Currently, when a single component in a server fails, the entire server needs to be serviced by a technician. This all-or-nothing operating model is increasingly becoming a hindrance to achieving cloud sustainability goals.
Finding a sustainable server repair solution
A sustainable cloud platform should be water-positive and carbon-negative. Water consumption in datacenters primarily arises from the need for cooling, and liquid cooling (opens in new tab) has emerged as a potential solution for waterless cooling (opens in new tab). Paradoxically, liquid cooling also increases the complexity and time required to repair servers. Therefore, reducing the demand for repairs becomes essential to achieving water-positive status.
To become carbon-negative, Microsoft has been procuring renewable energy for its datacenters (opens in new tab) since 2016. Currently, Azure’s carbon emissions largely arise during server manufacturing, as indicated in Microsoft’s carbon emission report (opens in new tab). Extending the lifetime of servers, which Microsoft has recently done to a minimum of six years, is a key strategy to reduce server-related carbon emissions. However, longer server lifetimes highlight the importance of server repairs, which not only contribute significantly to costs but also to carbon emissions. Moreover, sourcing replacement components can sometimes pose challenges. Consequently, finding ways to minimize the need for repairs becomes crucial.
Spotlight: Event Series

Microsoft Research Forum
Join us for a continuous exchange of ideas about research in the era of general AI. Watch the latest episodes on demand.
Reducing server repairs by 60% with Hyrax
To support Microsoft sustainability goals, our paper, “Hyrax: Fail-in-Place Server Operation in Cloud,” proposes that cloud platforms adopt a fail-in-place paradigm where servers with faulty components continue to host virtual machines (VMs) without the need for immediate repairs. With this approach, cloud platforms could significantly reduce repair requirements, decreasing costs and carbon emissions at the same time. However, implementing fail-in-place in practice poses several challenges.
First, we want to ensure graceful degradation, where faulty components are identified and deactivated in a controlled manner. Second, deactivating common components like dual in-line memory modules (DIMMs) can significantly impact server performance due to reduced memory interleaving. It is crucial to prevent VM customers from experiencing loss in performance resulting from these deactivations. Finally, the cloud platform must be capable of using the capacity of servers with deactivated components, necessitating algorithmic changes in VM scheduling and structural adjustments in the cloud control plane.
To address these challenges, our paper introduces Hyrax, the first implementation of fail-in-place for cloud compute servers. Through a multi-year study of component failures across five server generations, we found that existing servers possess sufficient redundancy to overcome the most common types of server component failures. We propose effective mechanisms for component deactivation that can mitigate a wide range of possibilities, including issues like corroded connectors or chip failures. Additionally, Hyrax introduces a degraded server state and scheduling optimizations to the production control plane, enabling effective utilization of servers with deactivated components, as illustrated in Figure 1.
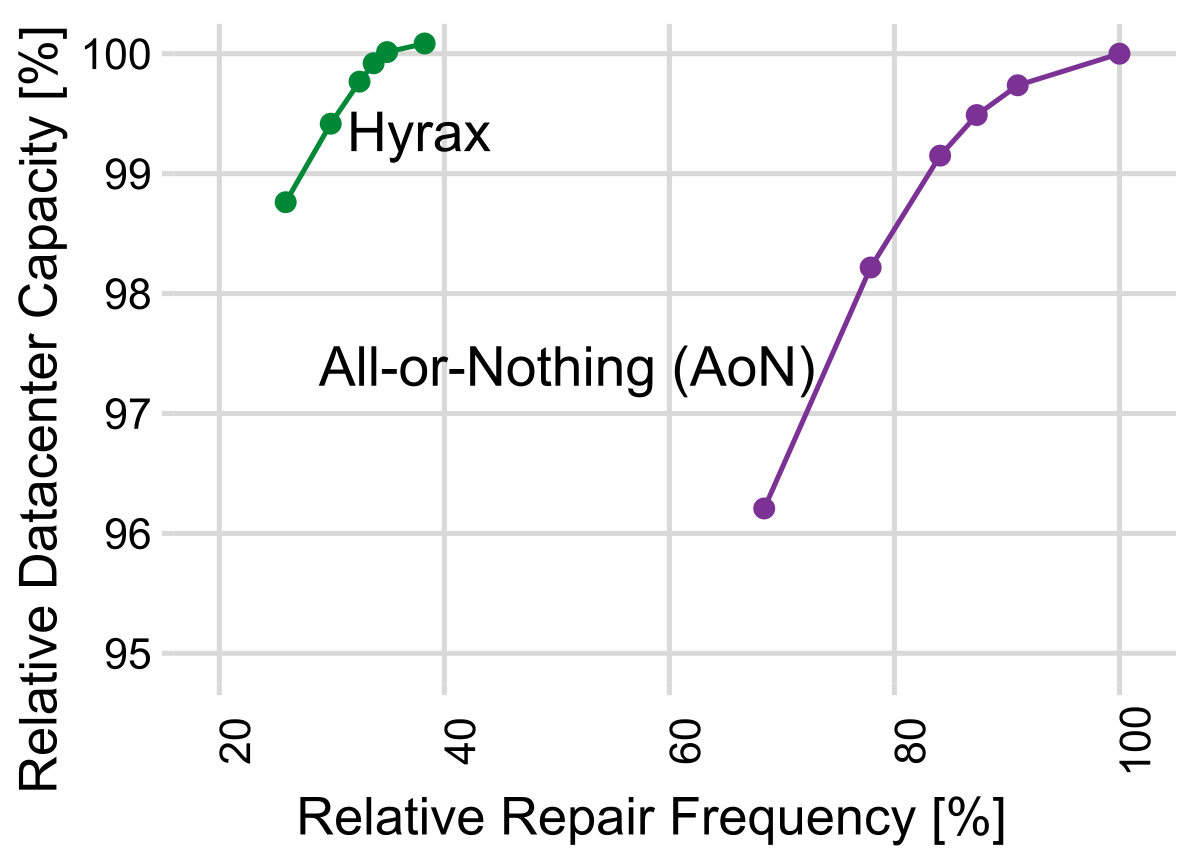
Our results demonstrate that Hyrax achieves a 60 percent reduction in repair demand without compromising datacenter capacity, as shown in Figure 2. This reduction in repairs leads to a 5 percent decrease in embodied carbon emissions over a typical six-year deployment period, as fewer replacement components are needed. In a subsequent study, we show that Hyrax enables servers to run for 30 percent longer, resulting in a proportional reduction in embodied carbon. We also demonstrate that Hyrax does not impact VM performance.
Deactivating memory modules without impacting performance
One of Hyrax’s key technical challenges is the need to deactivate components at the firmware level, as software-based deactivations prove to be insufficient. This requirement requires addressing previously unexplored performance implications.
A good example is the deactivation of a memory module, specifically a DIMM. To understand DIMM deactivation, it is important to consider how CPUs access memory, which is usually hidden from software. This occurs at the granularity of a cache line, which is 64 bytes and resides on a single DIMM. Larger data is divided into cache lines and distributed among all DIMMs connected to a CPU in a round-robin fashion. This interleaving mechanism ensures that while one DIMM is handling cache line N, another DIMM serves cache line N+1. From a software standpoint, memory is typically presented as a uniform address space that encompasses all cache lines across all the DIMMs attached to the CPU. Accessing any portion of this address space is equally fast in terms of memory bandwidth. Figure 3 shows an example of a server with six memory channels populated with two 32-GB DIMMs each. From the software perspective, the entire 384 GB of address space appears indistinguishable and offers a consistent 120 GB/sec bandwidth.
However, deactivating a DIMM causes the interleaving policy to reconfigure in unexpected ways. Figure 3 demonstrates this scenario, where the second DIMM on channel B (B2) has been identified as faulty and subsequently deactivated. Consequently, three different parts of the address space exhibit different characteristics: 120 GB/sec (six-way interleaving), 80 GB/sec (four-way interleaving), and 20 GB/sec (one-way interleaving). These performance differences are invisible to software and naively scheduling VMs on such a server can lead to variable performance, a suboptimal outcome.
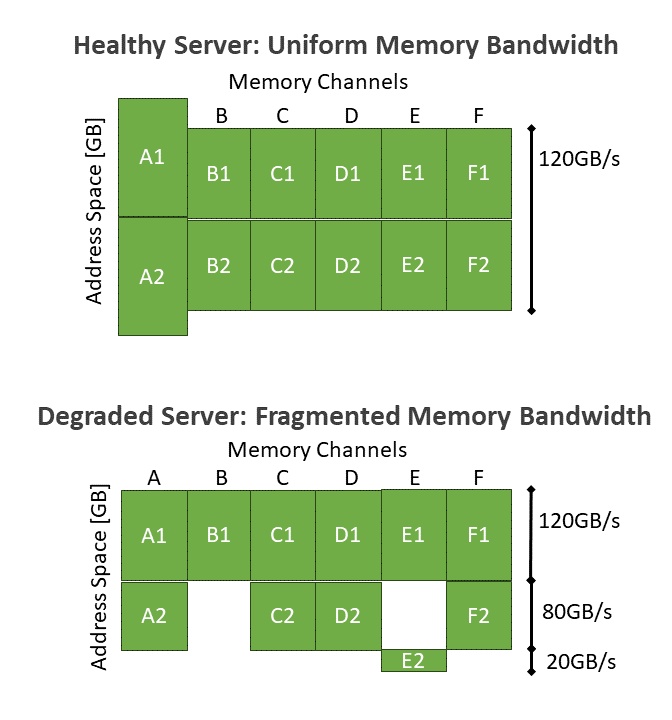
Hyrax enables cloud platforms to work around this issue by scheduling VMs on only the parts of the address space that offer sufficient performance for that VM’s requirements. Our paper discusses how this works in more detail.
Implications and looking forward
Hyrax is the first fail-in-place system for cloud computing servers, paving the way for future improvements. One potential enhancement involves reconsidering the approach to memory regions with 20 GB/sec memory bandwidth. Instead of using them only for small VMs, we could potentially allocate these regions to accommodate large data structures, such as by adding buffers for input-output devices that require more than 20 GB/sec of bandwidth.
Failing-in-place offers significant flexibility when it comes to repairs. For example, instead of conducting daily repair trips to individual servers scattered throughout a datacenter, we are exploring the concept of batching repairs, where technicians would visit a row of server racks once every few weeks to address issues across multiple servers simultaneously. By doing so, we can save valuable time and resources while creating new research avenues for optimizing repair schedules that intelligently balance capacity loss and repair efforts.
Achieving sustainability goals demands collective efforts across society. In this context, we introduce fail-in-place as a research direction for both datacenter hardware and software systems, directly tied to water and carbon efficiency. Beyond refining the fail-in-place concept itself and exploring new server designs, this new paradigm also opens up new pathways for improving maintenance processes using an environmentally friendly approach.







