
Cloud Intelligence/AIOps blog series
In the first two blog posts in this series, we presented our vision for Cloud Intelligence/AIOps (AIOps) research, and scenarios where innovations in AI technologies can help build and operate complex cloud platforms and services effectively and efficiently at scale. In this blog post, we dive deeper into our efforts to automatically manage large-scale cloud services in deployment. In particular, we focus on an important post-deployment cloud management task that is pervasive across cloud services – tuning configuration parameters. And we discuss SelfTune, a horizontal reinforcement learning (RL) platform for successful configuration management of various cloud services in deployment.
Post-deployment management of cloud applications
Managing cloud applications includes mission-critical tasks such as resource allocation, scheduling, pre-provisioning, capacity planning and provisioning, and autoscaling. Currently, several of these tasks rely on hand-tuned and manually designed algorithms, heuristics, and domain knowledge. For a large cloud company like Microsoft, a hand-tuned, manually designed algorithm works well only to a certain extent, because deployments are extremely varied, large-scale, and involve complex interactions of various components. Moreover, user, customer, and application behavior can change over time, making yesterday’s hand-tuning not as relevant today and even less so in the future. The varied nature of today’s cloud technologies forces our engineers to spend an inordinate amount of time on special casing, introducing new configuration parameters, and writing or rewriting heuristics to set them appropriately. This also creates a lot of undocumented domain knowledge and dependence on a few individuals to solve significant problems. All of this, we believe, is unsustainable in the long term.
As we discussed in the earlier posts in this blog series, the right AI/ML formulations and techniques could help to alleviate this problem. Specifically, cloud management tasks are a natural fit for adopting the reinforcement learning paradigm. These tasks are repetitive in space and time; they run simultaneously on multiple machines, clusters, datacenters, and/or regions, and they run once every hour, day, week, or month. For instance, the VM pre-provisioning service for Azure Functions is a continuously running process, pre-provisioning for every application. Scheduling of background jobs on substrate runs separately on every machine. Reinforcement learning also needs a repetitive and iterative platform to converge on an optimized setup and, hence, can go together with the basic functioning of the cloud management task.
video series

On Second Thought
A video series with Sinead Bovell built around the questions everyone’s asking about AI. With expert voices from across Microsoft, we break down the tension and promise of this rapidly changing technology, exploring what’s evolving and what’s possible.
Our goal is to reduce manual effort in ensuring service efficiency, performance, and reliability by augmenting, complimenting, or replacing existing heuristics for various management tasks with general RL-based solutions. In this blog post, we present our recent solution frameworks for cloud applications, to automatically tune their configuration parameters and to design policies for managing the parameters over time. Our solutions require minimal engineering effort and no AI expertise from the application developers or cloud operators.
Example Microsoft scenarios
O365 Workload Manager: Workload Manager (WLM) is a process that runs on each of the backend Exchange Online (EXO) servers to help schedule resources (CPU, disk, network) to background jobs that periodically execute. WLM has several configuration parameters that need to be carefully set so that the throughput of the scheduler is maximized while also ensuring that the resources are not too strained to execute low-latency user-facing jobs (e.g., Outlook search). Could we help EXO infrastructure manage the various knobs that dictate the control logic implemented in the scheduler for optimizing resource management and user latency?
Azure ML/Spark: Spark is the platform for performing distributed data analytics, and it comes with various configuration knobs that need to be appropriately set by developers based on their job context: Does the query involve JOIN clauses? How big are the data shards? The workload patterns change over time, and pre-trained models for choosing optimal configurations may not suffice. Can we help developers dynamically choose the deployment configuration based on workload signals?
Azure Functions VM management: Can we tune the VM management policy implemented in Azure Functions for VM pre-fetching/eviction to minimize cold starts and memory wastage over time? Our results in simulations are quite encouraging. We want to engage with the Azure and MSR Redmond teams to discuss the possibility of tuning the policy in the production setting.
Azure Kubernetes Service: AKS is chosen by first-party as well as third-party Azure customers for facilitating containerized development and deployment of cloud applications. The in-built workload autoscaling policies in AKS use several configuration parameters, which can be far from optimal in several scenarios. Can we help automatically adjust the parameters that govern resource allocation to containers running microservices based on applications’ workload patterns?
Horizontal solution design for configuration tuning
We see three main reasons why this is the right time to design and incorporate an RL-based solution framework across cloud management tasks:
- As the size and complexity of services in the cloud continue to increase, as our hardware footprint continues to include many SKUs, and as configuration and code get larger and more complex, heuristics and hand-tuning cannot provide optimal operations at all times. Not without significant and proportionate investment in human experts and engineers.
- While we will have to rely on domain experts for key changes in systems and the services landscape on the cloud, using RL sub-systems can help reduce dependence on expert decisions and domain-knowledge over time.
- It is important to have a horizontal framework with a simple yet expressive API, with appropriate algorithms for tuning configuration parameters in an online fashion to optimize a developer-specific metric of interest or reward.
SelfTune framework
We have designed and deployed the SelfTune framework to help cloud service developers automatically tune the configuration parameters in their codebase, which would otherwise be manually set or heuristically tweaked. SelfTune is an RL-based framework that helps developers automate complex post-deployment cloud management tasks such as parameter tuning and performance engineering.
SelfTune is hosted as a service on the public Azure cloud. First-party applications that are interested in post-deployment parameter tuning can use RestAPI calls to access SelfTune endpoints. The SelfTune framework has two components:
- Client API provides necessary support to access the SelfTune endpoints via RestAPI calls, namely, Predict for getting the parameters from the framework and SetReward for providing reward/feedback to the framework.
- RL Engine implements a suite of ML/RL algorithms for periodically updating the parameters and returning the latest values to the clients as well as for periodically computing the reward metrics.
At the core of the SelfTune framework is the formulation of the post-deployment parameter tuning problem as that of “online learning from bandit feedback.” SelfTune assumes that the only interaction possible with the external system (i.e., the application being tuned) is a black-box access to some form of feedback (e.g., daily P95 latency of the service). The framework repeatedly deploys configuration parameters and observes the corresponding rewards after a developer-defined period. As the operational environment (e.g., production cluster running certain types of workloads) is constantly in flux, there is no single setting of parameters that will remain optimal throughout. Thus, SelfTune continuously runs the explore-exploit paradigm of RL techniques – explore new parameters in the vicinity of the currently deployed parameters, observe rewards, update its internal model based on the reward, and exploit parameters that tend to give high rewards over time.
We have designed a bandit learning algorithm called Bluefinin SelfTune that crystallizes the aforementioned idea. Our algorithm has lower sample complexity, which means it takes a lower number of rounds for the algorithm to converge to desired values when we want to tune multiple real-valued parameters simultaneously, compared to peer techniques like multi-arm bandits (which is the base of Azure Personalizer), Bayesian Optimization (used by the MLOS framework), or genetic algorithms. This is provable under some assumptions on the reward function, but we observe, across multiple deployments, that the algorithm converges to good solutions in practice even when theoretical assumptions are often violated.
We have open-sourced Bluefin through Vowpal Wabbit, a popular RL library for practitioners, which houses the core algorithms of Azure Personalizer. We are continuing to work on designing vertical RL algorithms and horizontal feature learning for the systems domain. Besides Bluefin, SelfTune supports a suite of black-box optimization (e.g. Bayesian Optimization) and RL techniques (e.g., Deep Deterministic Policy Gradients) that the cloud applications can choose from, based on their needs.
A simple integration use case: Consider the scenario of setting PySpark cluster configuration parameters for Azure ML jobs that are spawned for ML workloads in the O365 MS-AI organization. The workloads are composed of various data processing jobs and run on various Azure ML clusters with different capacities and hardware. It is non-trivial to set parameters for various jobs, such that the workloads complete quickly, and not fail in the middle due to resourcing issues thereby losing all computations.
Basic SelfTune workflow: The basic integration of SelfTune in the AzureML pipeline is illustrated in the figure below. Here, the developer wants to tune seven key Apache PySpark parameters per job, namely driver memory, driver cores, executor cores, number executors, executor memory, spark.sql.shuffle.partitions, and spark.default.parallelism.
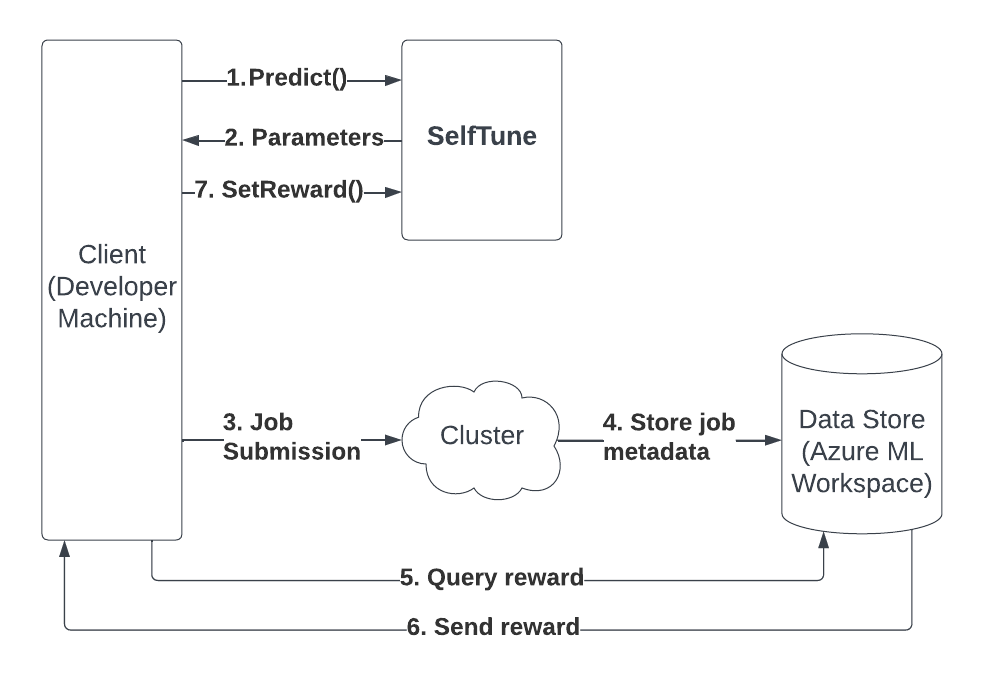
- Developer invokes Predict on the SelfTune instance, asking for the parameters for the next job.
- SelfTune service responds with the predicted parameters for the next job.
- The developer submits a job using SelfTune’s predicted parameters. //outside SelfTune’s purview
- Once the job is complete, the cluster sends job meta data to the data store. // outside SelfTune’s purview
- Developer queries rewards for previously completed jobs, if any, from Data Store (e.g., Azure ML workspace).
- Data Store responds with the rewards (e.g., job completion times, which is part of the job meta-data) from previously completed jobs.
- If the rewards exist in the store, the developer invokes SetReward for those jobs (which pushes the rewards to the SelfTune service endpoint hosted somewhere).
Self-tuning substrate background jobs scheduler
User-level background job scheduling: All the substrate backend servers in EXO datacenters (that host user mailboxes) run hundreds of low-priority, latency-insensitive, periodic workloads locally (e.g., mailbox replication, encryption, event-driven assistants, etc.). Workload Management (WLM) is a core substrate service that runs on all such backend servers. It helps with the user-level scheduling of workloads on the servers: a) with the goal of completing the tasks when resources become available (at micro-granular timescales), and b) mindful of the fact that high-priority, latency-sensitive workloads will bypass this scheduler. Thus, ensuring high availability of resources especially during peak hours is critical, besides meeting workload SLAs.
Tuning real-valued configuration parameters: The scheduler is implemented today as part of a huge codebase in the substrate core. The scheduler trades off resource utilization and completion rates by dynamically ramping up and ramping down the number of concurrent background tasks requiring access for the resources. This is achieved by carefully setting several configuration settings (hundreds of real-valued parameters). At a server level, we can achieve better resource utilization and throughput, by automatically tuning the key parameters, based on the workloads it receives and the ensuing resource health fluctuations.
Impact of using SelfTune in WLM: We have integrated SelfTune with the substrate background scheduler codebase (the change required is simple, on the order of tens of lines of code, as shown in the figure below). We first deployed in the inner rings of substrate (over 3000+ servers). The results gathered over 4-5 weeks of deployment clearly indicate that tuning helps on most of the deployed servers, increasing throughput at least 20% across multiple forests in their heavily throttled servers, with a marginal increase in CPU health and insignificant-to-mild degradation of disk health. Based on this validation, we have now rolled out SelfTune integration to most EXO backend servers (nearly 200,000) across the worldwide production ring.

Ongoing work and future AI+systems research
SelfTune is a general platform and can be readily applied to many RL-for-cloud scenarios without any additional feature engineering or onboarding efforts (which are typically required in AIOps). We expect that developers can define a suitable spatial and temporal tuning scope in the service/system, tuning the parameters of the service running in the cluster, at the level of machines, every hour of every day. Thus, instead of hand-coding the optimal operating points for various machines or various clusters that the service operates in, we could integrate SelfTune in the service codebase to dynamically figure them out over time, based on the real-time feedback at a determined temporal granularity.
Our work poses a lot of interesting design and algorithmic questions in this space. For instance, can we automatically scope the tuning problem based on some observed context such as cluster type, hardware, workload volumes, etc., and find optimal parameters per scope? Given that typical cloud applications have hundreds, if not thousands, of knobs to tune, can we automatically identify the knobs that impact the performance metric of interest, and then tune those knobs more efficiently?
A combination of system insights, ML formulations, and cross-layer optimization is vital for effective post-deployment management of cloud applications and services. We will post an update to this blog post on our ongoing work in this space soon. Meanwhile, the final blog post in this series will explore how AIOps can be made more comprehensive by spanning the entire cloud stack.