
By Rob Knies, Managing Editor, Microsoft Research
These days, more than ever, it’s important for computing to be energy-efficient. Particularly in data centers, energy requirements represent a significant portion of operational costs, and power and cooling needs help dictate where data centers can be located, how close to capacity they can operate, and how robust they are to failure.
In part, however, this is true because computers are precision machines. They’re hard-wired that way. Ask a computer what the average daily temperature is in Seattle on May 16, and you might get an answer such as 57.942368 degrees. While most of us would be hard-pressed to discern the atmospheric difference between 57.942368 degrees and 58, computers are able to provide that precision—even when such precision is all but useless.
Microsoft research podcast

Abstracts: August 15, 2024
Advanced AI may make it easier for bad actors to deceive others online. A multidisciplinary research team is exploring one solution: a credential that allows people to show they’re not bots without sharing identifying information. Shrey Jain and Zoë Hitzig explain.
Surely, there must be a way to save the energy utilized to offer such superfluous exactitude. And if you could do so, given the thousands upon thousands of machines housed in a typical data center, surely significant savings would result.
Trishul Chilimbi certainly believes so. Chilimbi, senior researcher and manager of the Runtime Analysis and Design team within Microsoft Research Redmond’s Research in Software Engineering organization, is leading an effort to underscore the importance of energy-efficient computing, as evidenced in the paper Green: A System for Supporting Energy-Conscious Programming Using Principled Approximation.

Trishul Chilimbi
“The Green project,” Chilimbi explains, “is looking at how we can save energy efficiency purely looking at software. The high-level goal is to give programmers high-level abstractions that they can use to express domain knowledge to the underlying system so it can take advantage.”
In other words, round that temperature off to the nearest degree, please.
“Especially in the cloud-computing space and data centers,” Chilimbi says, “there are service-level agreements that you’re not always going to get a very precise answer. And even where they’re not in place, programmers know that there is an asymmetric importance of results in certain domains.
“Let’s take search for an example. My query results on the first few pages are very important. The ones on the 100th page might not be as important. We’d like to devote more resources to focusing on the first several pages and not as much to those much lower down the rank system.”
So, with a bit of programmer-defined approximation, computers can take much less time to provide results that, while not as precise as possible, deliver valuable information for real-world problems in a fraction of the time and the resource requirements necessitated by precision measurements.
“Computer programming languages have been built on a mathematical foundation to provide very precise answers,” Chilimbi says, “and in domains where you don’t need that precision, you end up overcomputing and throwing away results. If programmers specify what their requirements are, we’ll avoid this and do exactly what you need to meet those requirements, but no more.”
The energy savings, of course, depend upon the level of approximation the programmer specifies.
“Say 99.999 percent of all results should be similar as if you didn’t have this Green system in place,” Chilimbi says. “That’s a very high threshold. And with that, we see savings of about 20 percent, which translates directly into energy, because if you do less work, you’re consuming fewer resources and less energy.
“We found that if you’re willing to tolerate even lower levels of accuracy—say I have a speech-recognition program, and I can tolerate a loss of accuracy of 5 percent—maybe I can get it back with smart algorithms and understanding use context and get a factor of 2X improvement.”
Such results might seem astounding, but not when you stop to think about it.
“It’s not surprising there’s this diminishing margin of returns,” Chilimbi says. “As you go for the last improvement, you’re using more and more resources, and as you’re willing to scale back, you get fairly large savings. It can be very significant, and it’s up to the programmer to intelligently specify what’s realistic for the domain.
“In many domains, such as graphics in a video game, anything beyond 60 frames per second the user can’t distinguish. You have potential for a graceful degradation, and it’s fairly significant.”
Unnecessary Precision
But, he stresses, the savings depend on the domain.
“You don’t want to do this for banking,” Chilimbi smiles. “There are certain domains in which you need absolute precision. But I think there are more domains for which you don’t need this precision. A lot of them are concerned with who the consumers of the information are. If they are human, they’re limited by audio and visual sensory perception. There is leeway to play around with that.”
You’ve heard the question: If a tree falls in a forest and nobody’s around to hear it, does it make a sound? Now, try this one: If a human isn’t able to perceive the difference between a 10-millisecond response time and one that takes 5 milliseconds, why not save the energy the extra speed demands?
Graphics is one such domain. Speech recognition is another.
“There is a certain amount of fidelity we can deal with,” Chilimbi says. “If my battery is going to die, and I really want to see the end of this movie, I might be willing to compromise image quality for a little bit. Search is another classic example.”
Lest you get the idea that the Green project is applied research just to squeeze more capability out of data centers, think again. As Chilimbi notes, there are legitimate, intriguing, basic research questions being refined as part of this effort. One is to rethink programming languages from the perspective of a requirement of approximate versus absolute precision. How do you provide guarantees to support your approximation techniques? And how can programmers communicate their high-level knowledge about programs and application domains to underlying hardware?
The answer to the latter question might require designing hardware and software in tandem.
“One idea might be to use lower-energy components,” Chilimbi says, “but to get the performance back, you could have software communicate more of its intent, so hardware doesn’t have to infer it. That’s another high-level goal: How can we co-design software and hardware so that the whole system is energy-efficient, rather than trying to deal with these pieces in isolation?”
Quality of Service
Providing quality-of-service guarantees is equally challenging.
“Say I have a function in a program,” Chilimbi explains, “and there is a quality-of-service contract this function enforces. We have modular programs that have a notion of abstraction—I don’t need to know how this contract is implemented, just that this is the contract this module enforces. You could have a similar kind of quality-of-service contract in modules. Then the hard part becomes: How do I compose these quality-of-service agreements and construct an overall quality of service for the program?
“That’s a challenge, because you can have non-linear effects of combining these things. What kind of guarantees can you give? Can you give static guarantees, or are they only runtime guarantees?”
So, if you have approximated certain procedures sufficiently that they provide good-enough results while using fewer resources, and you analyze the level of precision necessary for a specific task, you’re home-free, right?
Not so fast. What, now, can you do with the model you have just constructed?
“You could say, ‘Well, I’m done if I have the model,’ “Chilimbi says. “I’m going to use the problem, and I’m going to assume that everything follows this model, and if that’s true, everything will be good because the model has been designed so that it is only approximate when it guarantees that it can meet whatever quality of service is required.”
The problem is, the real world isn’t always as accepting of lab-derived models as researchers would like.
“Unfortunately,” Chilimbi states, “in the real world, you might get unanticipated scenarios or inputs. You have to prepare for all possibilities. That’s why the static model is a good starting point, but it’s not sufficient, especially if you have a scenario very different from the ones you’re seen. To handle that, you need a third part that says, ‘Every once in a while, I’m going to check the scenarios I’ve seen, the usage I’ve seen, to ensure that I’m still meeting the quality-of-service requirement.
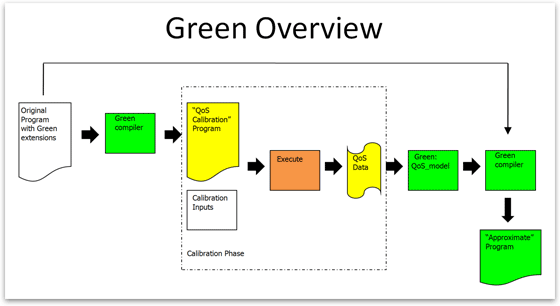
This diagram outlines how the Green project is designed to work.
“The way we check that is, on the same scenario, we execute both the precise version and the approximate version our model suggests and measure the quality-of-service error and see if it’s still above the threshold. If everything is fine, we’re OK. But if the scenario is very different from what we anticipated, then we might recalibrate the model to cope with this. You need this third part to guarantee that no matter what the situation is, you will meet quality of service. That is crucial, because you want to have this guarantee for your users, and just modeling limited inputs doesn’t allow you to give that guarantee.”
Chilimbi says he always has been interested in computer performance and optimization, but in recent years, he has seen his interests shift a little bit.
“As we’ve been moving to cloud computing with data centers and software as a service,” he says, “energy becomes, from a business perspective, very important, both on the data-center side and on the client side. On the data-center side, it’s about monthly operating costs and power bills. On the client side, it’s about battery life.”
And then there’s a new focus on the environment.
“I’m still interested in performance, but it’s not just performance at any cost—it’s performance per joule,” he says. “Energy efficiency is a natural extension. Data centers have interesting new workloads, I want to do research there, and it’s not just pure performance. It’s performance per joule and energy efficiency.”
In fact, the Green project is part of a bigger effort—one that includes a broad swath of personnel across Microsoft—to examine what would happen if the entire software and hardware stack were rebuilt with energy efficiency in mind.
“What if we could start from scratch?” Chilimbi ponders. “How could we rethink all parts of it—the programming language, the runtime system, the operating system, the microarchitectural design—so that everything is up for grabs?
“Are we going to design a microprocessor from scratch? Maybe not. But what we can do is see what current microprocessors are good at and what they’re bad at and add things like hardware accelerators to make them better. Rather than starting with something that’s very high-performance, expensive, and inefficient, you could start with something that’s very efficient but not very high-performance and see what parts of that inefficient piece are crucial for data-center workloads that would deliver high performance but still be energy-efficient?”
Of course, it helps when considering such scenarios to have Microsoft-scale resources behind you.
“Being at Microsoft,” Chilimbi says, “I feel I have an advantage, because I have access to data centers and data-center workloads that a lot of people don’t. By looking at that, you get access to interesting real problems.”
One of the real problems Chilimbi and colleagues have been examining has been search.
“The search domain was what we first focused on,” Chilimbi says. “It’s our largest property, we care about energy efficiency, let’s see what we can do.”
Search Expense
They identified the expensive functions in search and what they did, specifically the portions that identify all documents that match a query and then rank these documents.
“What we found,” Chilimbi reports, “is that, many times, you return a certain set of results, but to return those, you look at many more documents than needed. If you had an oracle, you would look at just a certain set of documents and return those. But you don’t have that. You need to look at more and rank them.
“So we said, ‘We can design an algorithm that can look at fewer documents but give the same results by deciding to stop early.’ When we started with that, we said, ‘Hey, wait a second! This is generalizable. We can this for other programs, as well.’ That’s where the whole framework and abstraction came about. But it was really targeted at search initially. The search people told us, ‘We have so many machines that if you improve it by this percent, it goes into millions of dollars really fast. That seemed motivating, so we decided to focus on search and how we could search fewer documents but return pretty much the same results. And then we can use those savings to improve the quality of ranking the documents that really matter.”
For Microsoft’s search efforts, it wasn’t so much a way to save money as it was a way to be efficient and use the savings to improve other parts of the search experience. And the technology is being used in Bing search today.
Chilimbi and his colleagues—including, at various points, Woongki Baek, a Stanford University Ph.D. candidate; Kushagra Vaid, from the Microsoft Global Foundation Services group; Utkarsh Jain, from Bing; and Benjamin Lee from Microsoft Research Redmond’s Computer Architecture Group—aren’t done yet. They hope to find a way to automate more of the approximation process, to learn how to compose quality-of-service metrics, and to identify the information software can communicate to hardware to make the two work together more efficiently.
“It’s a different way of looking at computing,” Chilimbi says. “We’ve been programmed to think of computers as these mathematical units that compute functions, whereas real-world problems are often much more fuzzy and approximate. We’ve forced these real-world problems into mathematical-function form.
“We want to see how far we can go with the results we have to date with more approximate models of computing. In the long run, this might make perfect sense. Green has been the first few steps, but the results are pretty good, so they justify continuing along this very interesting, novel path. Approximate computing is very interesting, especially if we can bound and guarantee a specified level of approximation, and I think we should continue investigating it. There’s a lot of opportunity there.”



