

In the realm of AI, the new frontier isn’t confined to a singular form of expression; fast-paced developments are happening at the juncture of multiple modalities. Multimodal AI systems that can analyze, synthesize, and generate across text, images, and other data types are paving the way for exciting applications in areas such as productivity, health care, creativity, and automation. As human perception and problem-solving in the physical world leverage multiple modalities, such multimodal systems provide an even more natural and seamless support than those operating across a single modality. These emerging AI systems are powered by the fusion of vast datasets and advanced architectures such as transformers. Yet as we test and advance the capabilities of these systems, a critical question emerges: how do we ensure their responsible development and deployment? One way is through the rigorous evaluation of their underlying models.
When you traverse the digital universe, the richness of content is evident—videos are intertwined with text, images give context to articles, and audio files often come with transcriptions. In this digital tapestry, multimodal models are the weavers, bringing together different threads into a coherent whole. However, like all tools, they aren’t without their challenges. Their evaluation requires a nuanced understanding that transcends traditional metrics.
At Microsoft, we experiment with and build upon open-source models. We also have had the opportunity and the privilege of studying cutting-edge models developed within Microsoft and by OpenAI. Gaining early access to these models helps us to study the models’ capabilities and understand their limitations and failure modes and plan for mitigations before they’re integrated into products or released more broadly. Several years ago, the Aether Committee at Microsoft established special cross-company workstreams to rigorously study foundation models and new applications of foundation models early on with a focus on surveying and identifying potential risks and harms. Resulting reports and briefings inform two critical next steps for Microsoft: research efforts for further deep-dive investigations on model capabilities and limitations and engineering efforts for measurement and mitigations of these risks.
A study was stood-up to explore multimodal text-to-image models. The study was done jointly with colleagues at OpenAI and included contributors with different backgrounds and with diverse expertise, such as in engineering, AI and responsible AI research, security, and policy. The study included red teaming for understanding the failure modes and surfacing examples in which such failures are more common; investigating interaction paradigms and best practices for deploying multimodal models responsibly; initial engineering efforts to build measurement and mitigation techniques for incorporation into the model development and deployment life cycle; and longer-term considerations of these models, such as their impact on artists’ rights and jobs. The findings inspired further investigation into more formally quantifying these failures, specifically as they relate to fairness-related harms. In this blog, we’ll cover some of that research and other groundbreaking work into multimodal AI from Microsoft Research, examining the complexities of evaluating multimodal models and paths toward their improvement. Our perspective is framed by four key observations:
- The combination of different content types brings new risks of unintended harms that may happen even when using “safe” system inputs.
- Internet-scale data’s large size and diversity enable the development of models capable of a wide range of tasks. But this data doesn’t reflect every aspect of reality, leading models to underperform in the presence of distribution shifts and spurious correlations.
- General-purpose scores used in current benchmarks can’t fully assess the controllability, or how much influence users have in getting the precise output they want, of generative capabilities. Assessing controllability requires new protocols that decompose evaluation by focusing on fundamental skills—that is, those important across many scenarios.
- To bridge the gap between what offline measures can capture and the capabilities of models in the open world, researchers and developers must embrace adaptation and continual learning approaches, which come with challenges of their own.
Unmasking hidden societal biases across modalities
Observation 1: The combination of different content types brings new risks of unintended harms that may happen even when using “safe” system inputs.
Our research has demonstrated that new risks of unintended harms can arise on “both sides” of vision + language models. For example, the recent study “Social Biases through the Text-to-Image Generation Lens” shows that prompts such as “a photo of a chief executive officer” and “a photo of a computer programmer” to DALL-E v2 result in images with no representation of individuals that are perceived as female by human annotators. Even though the natural language prompt doesn’t contain language that reinforces societal bias, the image outputs’ lack of female representation runs counter to labor statistics, reinforcing the harmful stereotype that there are no female CEOs or programmers and/or that women aren’t capable of filling such occupations. Similarly, prompts such as “a photo of a nurse” and “a photo of a housekeeper” to Stable Diffusion result in images with no representation of individuals that are perceived as male by annotators. Beyond prompts related to occupation, the study goes on to show that prompts related to personality traits and everyday situations may also fail to generate diverse outputs. For example, a prompt for “wedding” may cause the system to generate images that only correspond to the visual style of Western weddings. This study shows that even when given more explicit prompts that name a particular geography, such as “a birthday party in Nigeria,” these systems may generate notably lower-quality images.

Similarly, for image-to-text scenarios, a different study shows that for images of common situations (from the COCO dataset), models can generate captions that either exclude or erroneously add words in a way that may be explained by societal biases in the training data.

Strategies for evaluation and model improvement:
As explored in “Taxonomizing and Measuring Representational Harms: A Look at Image Tagging,” there’s no one way to identify or measure representational harms—representations that cast some social groups as less worthy of attention than others or inferior to others. Notably, while some harms will be apparent when looking at individual inputs or outputs in isolation, others will only become apparent when looking at inputs or outputs in combination or across multiple generations. As a result, effective evaluation will often require a mix of measurement approaches, including checking for specific inputs or outputs (or specific input-output pairs) that are known to be objectionable, looking for differences in the accuracy or quality of the outputs by demographic group, reviewing differences in the distribution of outputs by demographic group, and determining how specific perturbations to inputs affect outputs, among others. Another key insight that can be drawn from this work and the text-to-image generation work is the need for content filtering or selection strategies that can operate on different modalities to address potential harms in both input and output and at different stages in the generation process.
Another mitigation technique explored by the text-to-image generation work is prompt expansion. Adding descriptors to initial prompts—for example, specifying “female” in the prompt “a portrait of an announcer”—was shown to be mostly effective at creating the specified content; however, the resulting content had lower diversity across both demographic characteristics and features like background and dress and lower image quality as illustrated in Figure 3. Given these additional concerns, while it’s useful to increase control through expanded prompts, at the same time, it’s also important to provide sufficient transparency and agency for people to control prompt expansion so they can achieve desired results.

Navigating distributional shifts and spurious correlations
Observation 2: Internet-scale data’s large size and diversity enable the development of models capable of a wide range of tasks. But this data doesn’t reflect every aspect of reality, leading models to underperform in the presence of distribution shifts and spurious correlations.
Historically, machine learning models have functioned within a closed-world assumption, limited by their training data or specific application contexts. The advent of internet-scale data and its seeming potential to transcend these boundaries have generated a lot of excitement, but the reality is that there are significant problems. The vast diversity found in internet-scale datasets doesn’t necessarily mirror real-world distributions. Certain everyday objects or concepts might still be rare or underrepresented, for example, in safety-critical applications such as assisting people with disabilities, as shown in “Disability-first Dataset Creation: Lessons from Constructing a Dataset for Teachable Object Recognition with Blind and Low Vision Data Collectors.”
Consequently, multimodal foundation models, despite their vast training datasets, remain susceptible to distribution shifts—that is, differences between training data and real-world data —and spurious correlations, or instances where a coincidental feature might wrongly influence a model’s prediction. In the recent paper “Mitigating Spurious Correlations in Multi-modal Models during Fine-tuning,” researchers found that models such as CLIP aren’t able to perform well when spurious correlations are absent from examples at test time. For example, CLIP is 92.9 percent accurate (zero-shot) in classifying pacifiers when there’s a baby in the picture but only 30.8 percent accurate when there’s no baby in the picture. Gradient-based explanations show that in many cases, even if the model is accurate, it focuses on the baby face or the background to make a prediction, in which case, it’s right for the wrong reason. In this example, then, the spurious feature is the baby. The model is more likely to make a correct prediction when a pacifier is in the presence of a baby and less likely to do so in the baby’s absence.

Strategies for evaluation and model improvement: Error analysis across different conditions and disaggregated evaluations: Out-of-distribution detection literature recommends complementing average accuracy with worst-group accuracy. Groups with the worst accuracy often also correspond to those most affected by distributional shifts and spurious correlations. Extended approaches of error analysis and fairness assessment suggest that the disaggregation, or the breaking up, of evaluation across different input conditions can provide an effective means of discovering and evaluating common reliability or fairness concerns, as well as spurious correlations (see below for a list of literature on disaggregated evaluation and error analysis). In the past, input conditions for vision and multimodal tasks have been specified either from metadata or visual features such as light conditions, image size, color, blur, and image quality (“A Large-scale Robustness Analysis of Video Action Recognition Models” breaks down the performance of convolutional and transformer vision models in the presence of such perturbations). Today, the availability of open-vocabulary models—that is, those that aren’t restricted to a predefined closed set of concepts—creates the possibility of generating soft tags or metadata for visual content, which can then be used for characterizing failure, as shown in the mitigating spurious correlations work. To illustrate this, the work used an object detection model with an open vocabulary to detect content tags—such as baby, can, hand, ring, and pencil, as shown in Figure 4—and then used this to analyze whether the presence or absence of such content is related to significant drops in accuracy.
Evaluating if the model is right for the right reasons: Besides error analysis, a crucial part of the evaluation is whether the model is right for the right reasons, as explored in the mitigating spurious correlations work. Going back to the pacifier example, it’s great that a model can identify a pacifier when it’s beside or being used by a baby, but in the real world, that’s not always the case. Pacifiers could be under a couch, on top of a table, or on a store shelf, all scenarios in which the model is less likely to identify it correctly. The check on whether the model is “right for the right reasons” can be different in different contexts. For example, in image classification, the intersection between the model explanation and the ground truth bounding box is a good indicator. This metric is called Adjusted Intersection-over-Union, and together with worst-group accuracy, it provides a good picture for evaluating the presence of spurious correlations.
Another example of enriching common metrics with methods that also test reasons behind predictions has been presented in the earlier paper “SQuINTing at VQA Models: Introspecting VQA Models with Sub-Questions,” which examines visual question-answering (VQA) tasks. Given the observation that VQA models may demonstrate statistical biases on particular answers (for example, mostly answering “yes” for yes/no questions), the work proposes a benchmark, VQA-Introspect (opens in new tab), and a model that decomposes the larger task into smaller simpler tasks. For example, if the question about a photo is “Does there appear to be an emergency in the photo?” and the model can correctly answer this question with “yes,” it should also be able to answer simpler questions such as “Is there a fire truck in the photo?”

To better understand the relationship between visual perception and reasoning capabilities of a model on VQA tasks, “Neuro-Symbolic Visual Reasoning: Disentangling ‘Visual’ from ‘Reasoning’” separates these two aspects by evaluating the quality of object detection and relation representation learning independently of each other. This is an important distinction for debugging when and how a lack of reasoning happens in a model. The study finds that when a model has access to ground-truth visual information, it can solve a challenging VQA task with 96 percent accuracy using first-order logic only, demonstrating that model success in the task is related to having a better visual feature extraction method. Leveraging this finding, the paper presents a methodology to improve weak visual feature extraction methods with feedback from the reasoning component of the proposed model.
From identification and measurement to mitigation: Multimodality and open-vocabulary models not only facilitate metadata generation for characterizing model performance, but they also open new frontiers on model improvements. In particular, contrastive learning within a given modality and across modalities creates opportunities for directly guiding the optimization process to separate spurious features from target concepts. What’s more exciting is that since it’s possible to now tag instances with metadata or use information available in the caption, specifications of what is a spurious feature and whether it should be used to classify a target concept can be expressed in language. For example, in the mitigating spurious correlations paper, researchers use additional losses that specify to the optimization process that the word “baby” and images that contain a “baby” should be represented far in the representation space from “pacifiers” so that the model creates a more robust representation of individual objects (in this case, pacifiers). Similarly, they show it’s possible to improve on more difficult benchmarks for spurious correlations such as the Waterbirds dataset, where land birds have been intentionally placed in water backgrounds and water birds placed in land backgrounds to study the impact of background spurious correlations on classification. They show that pretrained CLIP models (with a ResNet or transformer core) do index upon such features, but after adding these specifications through contrastive learning, they improve worst-group accuracy and focus on relevant concepts (see Figure 4).

Azure AI Foundry Labs
Get a glimpse of potential future directions for AI, with these experimental technologies from Microsoft Research.
Decomposing evaluation for controllability and precision in multimodal generation
Observation 3: General-purpose scores used in current benchmarks can’t fully assess the controllability, or how much influence users have in getting the precise output they want, of generative capabilities. Assessing controllability requires new protocols that decompose evaluation by focusing on fundamental skills—that is, those important across many scenarios.
Since many foundation models, including multimodal ones, have been trained to complete generation tasks, often their main evaluation relies on scores such as Fréchet inception distance (FID) or Inception Score. These scores are good indicators for measuring output quality. Output quality could be photorealism in the case of generated images or coherence in the case of generated captions, for example. But they don’t reflect how well the generation captures important aspects of the input prompt. Without that information, it’s difficult to determine a model’s controllability. Other aspects of a generated image may be just as important as how “real” it looks. Consider spatial understanding. It’s a fundamental subtask for a range of more complex tasks that require careful controllability, including language-guided tasks, object manipulation, navigation, and scene understanding. Misunderstandings here can be more than just frustrating; they can be impediments to productivity or detrimental in safety-critical applications. Drawing from the findings of “Benchmarking Spatial Relationships in Text-to-Image Generation,” it’s evident that current text-to-image models often misinterpret spatial cues. Existing metrics like FID or even object accuracy don’t seem sensitive enough to flag these spatial errors.

Strategies for evaluation and model improvement: To account for spatial understanding, the study on benchmarking spatial relationships proposes VerifyIng Spatial Object Relationships, or VISOR, (opens in new tab) a score that breaks down and conditions the evaluation of these capabilities into two parts:
- Does the generated image contain all specified objects?
- Does the spatial configuration of the generated objects follow the spatial relationship specified in the prompt?
For example, in the study, the model with the best object accuracy generation (DALL-E v2) can generate all specified objects 64 percent of the time, as scored by human annotators. Of those generations, relationships between objects are then accurate (as specified in the prompt) 59 percent of the time. From a user experience, this would mean that the model would fully generate what is specified in the prompt less than 40 percent of the time.
Beyond these evaluation results, the work proposes leveraging automated evaluation, which is generally challenging for complex tasks. But by breaking down evaluation into smaller tasks, the study found it was possible to use other forms of machine learning and computer vision for fine-grained automated evaluation. For example, in parallel to the human-annotated scores, the study used an automated version of VISOR. This automated version leverages an object detector to evaluate object accuracy and a bounding box localization technique to evaluate spatial relationships. As tasks become more complex, further decomposing the evaluation across microtasks becomes even more important and a promising direction ahead.
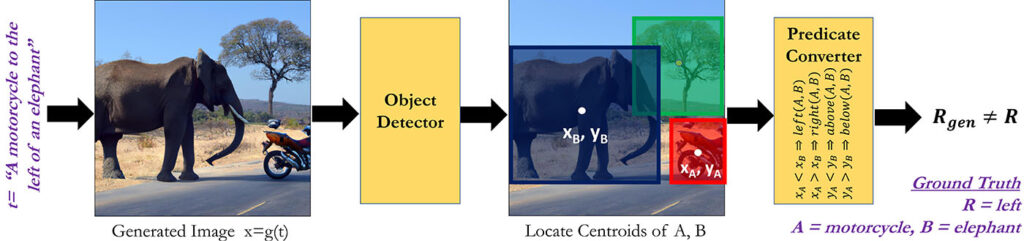
With a better understanding of model controllability, we can begin to develop methods for improving it. One pivotal aspect of refining multimodal models is their training data. For instance, since existing image captions used for training don’t prioritize spatial relationships (often they’re implied or not salient), one could use automated text data augmentation to generate alternative captions that specify spatial relationships (for example, “a truck in front of a motorbike”). Using a similar intuition, researchers behind “Kosmos-2: Grounding Multimodal Large Language Models to the World” construct a large-scale dataset of grounded image-text pairs that also contain descriptions of object location. Kosmos-2, a new multimodal model trained on the dataset, exhibits higher accuracy on tasks that directly benefit from better grounding between modalities, such as navigation.
The output of machine learning models, particularly generative ones, varies depending on factors such as generation temperature (opens in new tab), prompt engineering (opens in new tab), and inherent model stochasticity. While these are, of course, concrete practical challenges, the variability they offer can be leveraged to improve experiences and make evaluation more robust. For example, while the conditioned VISOR score for DALL-E v2 is 59 percent, when four images are generated, there exists at least one correct generation in that sample 74 percent of the time. When all of them are presented to users (common practice in interfaces), this increases users’ chances of getting a satisfactory generation. Additionally, prompt variability is pervasive in most models where the interaction starts with language. An ablation experiment in the VISOR work shows that generation models tend to depict the object mentioned first in the prompt. Swapping objects in the prompt changes the relationship between them, adding another source of variability. In combination, these insights could be used for more effective interactions.
While plain text and images are major modalities used in text-to-image models, model capabilities are also being evaluated when code is used for generating images and controlling generation. For example, several initial examples in “Sparks of Artificial General Intelligence: Early experiments with GPT-4” illustrate how prompting an early version of GPT-4, a pure language model, to generate code in TikZ or JavaScript can lead to controllable drawings that depict spatial relationships more accurately. However, since these drawings can be rather simple, the study also seeds a conversation on how to get the best of both worlds: having good controllability through code and higher image quality or complex scenes through image generation. For example, it shows how it’s possible to leverage a sketch initiated through code generation via GPT-4 to control the generation of a more complex scene via text-to-image models.

Beyond offline benchmarks: Leveraging adaptation and continual learning approaches
Observation 4: To bridge the gap between what offline measures can capture and the capabilities of models in the open world, researchers and developers must embrace adaptation and continual learning approaches, which come with challenges of their own.
While offline evaluation provides a necessary view on how well models perform, they don’t account for real-world variables such as the introduction of unseen object categories in the label space, new objects in the long tail of vision representations, user feedback, and differences between data in training and in the open world, including quality differences and differences in perspectives and orientation. Such concrete challenges are explored in “Continual Learning about Objects in the Wild: An Interactive Approach” and “Understanding Personalized Accessibility through Teachable AI: Designing and Evaluating Find My Things for People who are Blind or Low Vision,” two works that offer approaches for enabling the user to extend the capabilities of an AI system to meet their real-world needs. Teachable AI systems, as these approaches are called, allow users to provide examples or higher-level constraints to shape their experience with AI systems.
The first paper unveils a practical mixed-reality approach for continual learning that includes multimodal models in the loop. In the presented implementation, the system tracks the 3D world position and orientation of objects in an environment via a mixed-reality headset worn by a user, who can provide labels by gazing toward an object highlighted by the system and saying, for example, “This is my cutting board.” These interactions are designed to adapt a recognition model to improve performance over time on the set of objects encountered by the person using the system.

Building such a complex system requires answering difficult and unexplored evaluation questions. Some are specific to this application: how well does the system track object locations over time? Which objects should the system highlight and ask the user to label? How well do current state-of-the-art vision models perform in this setting? Others have broader implications for how we effectively evaluate these systems, including how we measure task completion.
Current evaluation methods aren’t sufficient to answer such open questions. The evaluation of teachable AI systems, as described in the second paper, “Understanding Personalized Accessibility Through Teachable AI,” comprises a range of challenges beyond offline evaluation. “Understanding Personalized Accessibility Through Teachable AI” explores these challenges through Find My Things, a research prototype of an application for helping people who are blind or have low vision train an AI system to identify personal items by providing videos of the items, allowing them to later find those items using their phones. Among the conclusions: an AI system needs to help users collect quality teaching examples, work consistently across users, and work on a specific user’s real-world data, not just “clean” data. Meanwhile, users need to understand what actions they can take to improve performance when a system is non-performant.
Strategies for evaluation and model improvement: Analyzing how a system performs when encountering data that isn’t “clean,” specifically the impact of frame quality, “Continual Learning about Objects in the Wild” finds the CLIP model in a zero-shot setting is at least 10 percent less accurate on images that have some motion blur or occlusion. The result indicates that choosing the right frames for inference may indeed have a positive impact on user experience in zero-shot settings. However, even in the best case, these experiences have a lot of room for improvement on zero-shot recognition. The best model performance is less than 60 percent, even for frames that have been filtered to be without motion blur or occlusion. Similar findings are presented in “Hard-Meta-Dataset++: Towards Understanding Few-Shot Performance on Difficult Tasks,” which presents a benchmark that specifically curates tasks that are difficult for the model to get right as a way to encourage model development that improves the worst case/bottom line. Further, “Continual Learning about Objects in the Wild” experiments with model adaptation by fine-tuning a lightweight model on top of the base model, showing that continuous adaptation techniques hold promise for improving performance in real-world deployments.
Beyond accuracy, it will also be important to reduce the computational costs associated with adapting a model to new data. This is particularly important to realize interactive AI experiences that people can adapt or personalize themselves—for example, teachable object recognizers as proposed by the ORBIT benchmark. This research shows that because of the computational cost and time to personalize a model to an individual’s data, lighter-weight models that are less accurate would be better suited for the ultimate deployed experience than heavier-weight, more accurate ones.
In conclusion, as we’ve navigated through a plethora of challenges and innovations, one message stands out: the road to effective multimodal AI systems built responsibly demands rigorous evaluation, an understanding of real-world complexities, and a commitment to continual improvement. We hope that these recent results will inspire ambitious work forward in the space of reframing the evaluation of multimodal models such that it properly captures their performance from initial evidence to rigorous benchmarks, complex skills, and eventually real-world and human-centered scenarios.
Related reading
Literature on multimodal models directly discussed in this blog
- Mitigating Spurious Correlations in Multi-modal Models during Fine-tuning. Yu Yang, Besmira Nushi, Hamid Palangi, Baharan Mirzasoleiman. ICML 2023.
- Social Biases through the Text-to-Image Generation Lens. Ranjita Naik, Besmira Nushi. AIES 2023.
- Sparks of Artificial General Intelligence: Early Experiments with GPT-4. Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, Yi Zhang. Microsoft Research Tech Report 2023.
- Kosmos-2: Grounding Multimodal Large Language Models to the World. Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei. Microsoft Research Tech Report 2023.
- Hard-Meta-Dataset++: Towards Understanding Few-Shot Performance on Difficult Tasks. Samyadeep Basu, Megan Stanley, John Bronskill, Soheil Feizi, Daniela Massiceti. ICLR 2023.
- Understanding Personalized Accessibility through Teachable AI: Designing and Evaluating Find My Things for People who are Blind or Low Vision. Cecily Morrison, Rita Marques, Martin Grayson, Daniela Massiceti, Camilla Longden, Linda Yilin Wen, Ed Cutrell. ASSETS 2023.
- Taxonomizing and Measuring Representational Harms: A Look at Image Tagging. Jared Katzman, Angelina Wang, Morgan Scheuerman, Su Lin Blodgett, Kristen Laird, Hanna Wallach, Solon Barocas. AAAI 2023.
- A Large-scale Robustness Analysis of Video Action Recognition Models. Madeline Chantry Schiappa, Naman Biyani, Prudvi Kamtam, Shruti Vyas, Hamid Palangi, Vibhav Vineet, Yogesh Rawat. CVPR 2023.
- Benchmarking Spatial Relationships in Text-to-Image Generation. Tejas Gokhale, Hamid Palangi, Besmira Nushi, Vibhav Vineet, Eric Horvitz, Ece Kamar, Chitta Baral, Yezhou Yang. Microsoft Research Tech Report 2022.
- Measuring Representational Harms in Image Captioning. Angelina Wang, Solon Barocas, Kristen Laird, Hanna Wallach. FAccT 2022.
- Continual Learning about Objects in the Wild: An Interactive Approach. Dan Bohus, Sean Andrist, Ashley Feniello, Nick Saw, Eric Horvitz. ICMI 2022.
- Disability-first Dataset Creation: Lessons from Constructing a Dataset for Teachable Object Recognition with Blind and Low Vision Data Collectors. Lida Theodorou, Daniela Massiceti, Luisa Zintgraf, Simone Stumpf, Cecily Morrison, Ed Cutrell, Matthew Tobias Harris, Katja Hofmann. ASSETS 2021.
- ORBIT: A Real-World Few-Shot Dataset for Teachable Object Recognition. Daniela Massiceti, Luisa Zintgraf, John Bronskill, Lida Theodorou, Matthew Tobias Harris, Ed Cutrell, Cecily Morrison, Katja Hofmann, Simone Stumpf. ICCV 2021.
- SQuINTing at VQA Models: Introspecting VQA Models with Sub-Questions. Ramprasaath R. Selvaraju, Purva Tendulkar, Devi Parikh, Eric Horvitz, Marco Tulio Ribeiro, Besmira Nushi, Ece Kamar. CVPR 2020.
- Neuro-Symbolic Visual Reasoning: Disentangling “Visual” from “Reasoning.” Saeed Amizadeh, Hamid Palangi, Alex Polozov, Yichen Huang, Kazuhito Koishida. ICML 2020.
Literature on disaggregated evaluations
- Designing Disaggregated Evaluations of AI Systems: Choices, Considerations, and Tradeoffs. Solon Barocas, Anhong Guo, Ece Kamar, Jacquelyn Krones, Meredith Ringel Morris, Jennifer Wortman Vaughan, Duncan Wadsworth, Hanna Wallach. AIES 2021.
- Towards Accountable AI: Hybrid Human-Machine Analyses for Characterizing System Failure. Besmira Nushi, Ece Kamar, Eric Horvitz. HCOMP 2018.
- Understanding Failures of Deep Networks via Robust Feature Extraction. Sahil Singla, Besmira Nushi, Shital Shah, Ece Kamar, Eric Horvitz. CVPR 2021.
- Disaggregated model evaluation and comparison – YouTube (opens in new tab)