
This content was given as a keynote at the Workshop of Applied Data Science for Healthcare and covered during a tutorial at the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (opens in new tab), a premier forum for advancement, education, and adoption of the discipline of knowledge discovering and data mining.
Recent and noteworthy advancements in generative AI and large language models (LLMs) are leading to profound transformations in various domains. This blog explores how these breakthroughs can accelerate progress in precision health. In addition to the keynote I delivered, “Applications and New Fronters of Generative Models for Healthcare (opens in new tab),” it includes part of a tutorial (opens in new tab) (LS-21) being given at KDD 2023 (opens in new tab). This tutorial surveys the broader research area of “Precision Health at the Age of Large Language Models,” delivered by Sheng Zhang, Javier González Hernández, Tristan Naumann, and myself.
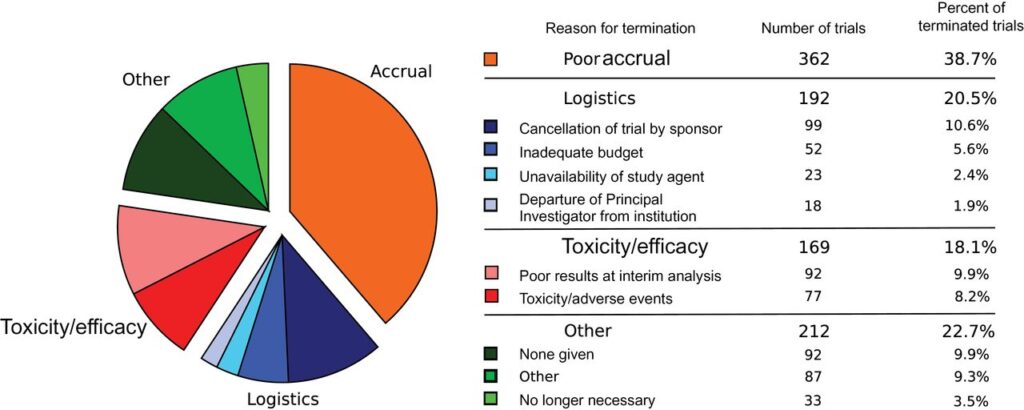
A longstanding objective within precision health is the development of a continuous learning system capable of seamlessly integrating novel information to enhance healthcare delivery and expedite advancements in biomedicine. The National Academy of Medicine has gathered leading experts to explore this key initiative, as documented in its Learning Health System (opens in new tab) series. However, the current state of health systems is far removed from this ideal. The burden of extensive unstructured data and labor-intensive manual processing hinder progress. This is evident, for instance, in the context of cancer treatment, where the traditional standard of care frequently falls short, leaving clinical trials as a last resort. Yet a lack of awareness renders these trials inaccessible, with only 3 percent of US patients finding a suitable trial. This enrollment deficiency contributes to nearly 40 percent of trial failures, as shown in Figure 1. Consequently, the process of drug discovery is exceedingly slow, demanding billions of dollars and a timeline of over a decade.
On an encouraging note, advances in generative AI provide unparalleled opportunities in harnessing real-world observational data to improve patient care—a long-standing goal in the realm of real-world evidence (RWE), which the US Food and Drug Administration (FDA) relies on to monitor and evaluate post-market drug safety (opens in new tab). Large language models (LLMs) like GPT-4 have the capability of “universal structuring,” enabling efficient abstraction of patient information from clinical text at a large scale. This potential can be likened to the transformative impact LLMs are currently making in other domains, such as software development and productivity tools.
PODCAST SERIES

AI Testing and Evaluation: Learnings from Science and Industry
Discover how Microsoft is learning from other domains to advance evaluation and testing as a pillar of AI governance.
Digital transformation leads to an intelligence revolution
The large-scale digitization of human knowledge on the internet has facilitated the pretraining of powerful large language models. As a result, we are witnessing revolutionary changes in general software categories like programming and search. Similarly, the past couple of decades have seen rapid digitization in biomedicine, with advancements like sequencing technologies, electronic medical records (EMRs), and health sensors. By unleashing the power of generative AI in the field of biomedicine, we can achieve similarly amazing transformations in precision health, as shown in Figure 2.
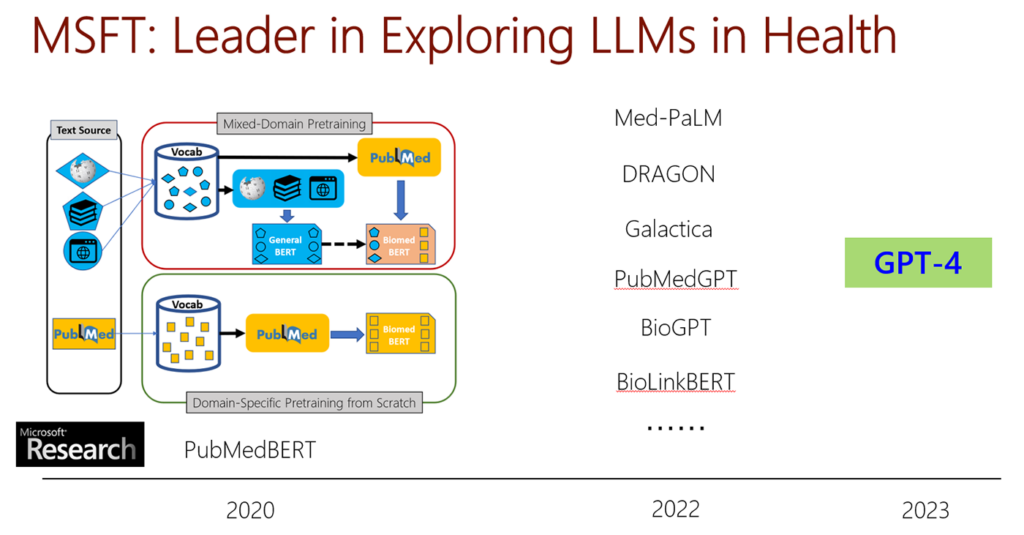
Microsoft is at the forefront of exploring the applications of LLMs in the health field, as depicted in Figure 3. Our PubMedBERT models, pretrained on biomedical abstracts (opens in new tab) and full texts (opens in new tab), were released three years ago. They have sparked immense interest in biomedical pretraining and continue to receive an overwhelming number of downloads each month, with over one million in July 2023 alone. Numerous recent investigations have followed suit, delving deeper into this promising direction. Now, with next-generation models like GPT-4 being widely accessible, progress can be further accelerated.
Although pretrained on general web content, GPT-4 has demonstrated impressive competence in biomedical tasks straightaway and has the potential to perform previously unseen natural language processing (NLP) tasks in the biomedical domain with exceptional accuracy. Notably, research studies show that GPT-4 can achieve expert-level performance on medical question-answer datasets, like MedQA (USMLE exam), without the need for costly task-specific fine-tuning or intricate self-refinement.
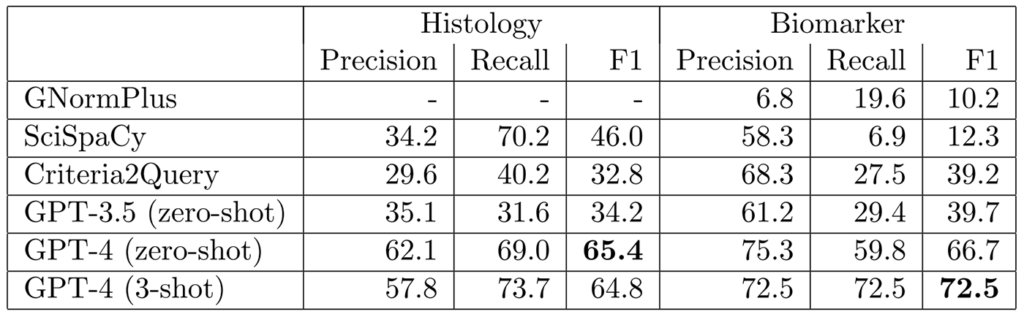
Similarly, with simple prompts, GPT-4 can effectively structure complex clinical trial matching logic from eligibility criteria, surpassing prior state-of-the-art systems like Criteria2Query, which were specifically designed for this purpose, as shown in Figure 4.
Transforming real-world data into a discovery engine
In the context of clinical trial matching, besides structuring trial eligibility criteria, the bigger challenge lies in structuring patient records at scale. Cancer patients may have hundreds of notes where critical information like histopathology or staging may be scattered across multiple entries, as shown in Figure 5. To tackle this, Microsoft and Providence, a large US-based health system, have developed state-of-the-art self-supervised LLMs like OncoBERT (opens in new tab) to extract such details. More recently, preliminary studies have found that GPT-4 can also excel at structuring such vital information. Drawing on these advancements, we developed a research system for clinical trial matching, powered by LLMs. This system is now used daily on a molecular tumor board at Providence, as well as in high-profile trials such as this adoptive T-cell trial, as reported by the New York Times (opens in new tab).
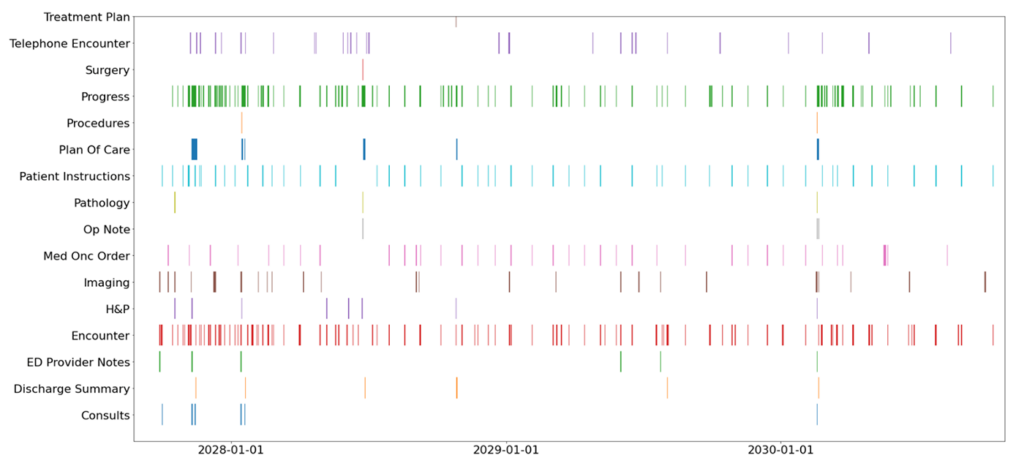
Clinical trial matching is important in its own right, and the same underlying technologies can be used to unlock other beneficial applications. For example, in collaboration with Providence researchers, we demonstrated how real-world data can be harnessed to simulate prominent lung cancer trials under various eligibility settings. By combining the structuring capabilities of LLMs with state-of-the-art causal inference methods, we effectively transform real-world data into a discovery engine. This enables instant evaluation of clinical hypotheses, with applications spanning clinical trial design, synthetic control, post-market surveillance, comparative effectiveness, among others.
Towards precision health copilots
The significance of generative AI lies not in achieving incremental improvements, but in enabling entirely new possibilities in applications. LLM’s universal structuring capability allows for the scaling of RWE generation from patient data at the population level. Additionally, LLMs can serve as “universal annotators,” generating examples from unlabeled data to train high-performance student models. Furthermore, LLMs possess remarkable reasoning capabilities, functioning as “universal reasoners” and accelerating causal discovery from real-world data at the population level. These models can also fact-check their own answers, providing easily verifiable rationale to enhance their accuracy and facilitate human-in-the-loop verification and interactive learning.
Beyond textual data, there is immense growth potential for LLMs in health applications, particularly when dealing with multimodal and longitudinal patient data. Crucial patient information may reside in various information-rich modalities, such as imaging and multi-omics. We have explored pretraining large biomedical multimodal models by assembling the largest collection of public biomedical image-text pairs (opens in new tab) from biomedical research articles, comprising 15 million images and over 30 million image-text pairs. Recently, we investigated using GPT-4 to generate instruction-following data to train a multimodal conversational copilot called LLaVA-Med, enabling researchers to interact with biomedical imaging data. Additionally, we are collaborating with clinical stakeholders to train LMMs for precision immuno-oncology, utilizing multimodal fusion to combine EMRs, radiology images, digital pathology, and multi-omics in longitudinal data on cancer patients.
Our ultimate aspiration is to develop precision health copilots that empower all stakeholders in biomedicine and scale real-world evidence generation, optimizing healthcare delivery and accelerating discoveries. We envision a future where clinical research and care are seamlessly integrated, where every clinical observation instantly updates a patient’s health status, and decisions are supported by population-level patient-like-me information. Patients in need of advanced intervention are continuously evaluated for just-in-time clinical trial matching. Life sciences researchers have access to a global real-world data dashboard in real time, initiating in silico trials to generate and test counterfactual hypotheses. Payors and regulators base approval and care decisions on the most comprehensive and up-to-date clinical evidence at the finest granular level. This vision embodies the dream of evidence-based precision health. Generative AI, including large language models, will play a pivotal role in propelling us towards this exciting and transformative future.