

Microsoft is proud to sponsor the 30th Symposium on Operating Systems Principles (SOSP 2024), highlighting its commitment to advancing computing systems research. In an age where digital infrastructure underpins nearly every facet of modern life, SOSP serves as an important forum for showcasing the technologies that shape our interconnected world. Organized annually by the Association for Computing Machinery (ACM), the symposium brings together experts to explore innovations in operating systems, distributed systems, and systems software.
With seven accepted papers, including “Verus: A Practical Foundation for Systems Verification,” which won the Distinguished Artifact Award, as well as two workshops, and a tutorial, Microsoft researchers are presenting groundbreaking work that strengthens the security, efficiency, and scalability of cloud computing and distributed systems. This work not only contributes to theoretical knowledge but also address real-world challenges, helping ensure that as computing systems grow more complex, they remain sustainable, reliable, and secure.
Continue reading to learn more about Microsoft’s contributions to SOSP 2024, including breakthroughs that tackle the evolving demands of modern computing.
Papers
Efficient Reproduction of Fault-Induced Failures in Distributed Systems with Feedback-Driven Fault Injection
Jia Pan, Haoze Wu, Tanakorn Leesatapornwongsa, Suman Nath, Peng Huang

This research introduces Anduril, a fault injection technique that quickly reproduces specific fault-induced failures in production systems. Anduril uses static causal analysis and a novel feedback-driven algorithm to quickly search the fault space for the failure’s cause and timing. Evaluation on 22 real-world fault-induced failures from five large-scale distributed systems demonstrate FIR’s ability to reproduce all failures by identifying and injecting the root-cause faults at the right time.
If At First You Don’t Succeed, Try, Try, Again…? Insights and LLM-informed Tooling for Detecting Retry Bugs in Software Systems
Bogdan Alexandru Stoica, Utsav Sethi, Yiming Su, Cyrus Zhou, Shan Lu, Jonathan Mace, Madan Musuvathi, Suman Nath
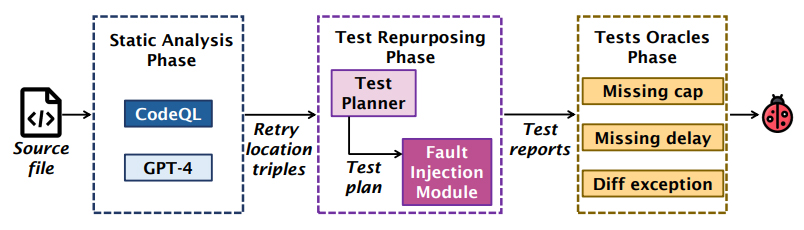
Retry—the re-execution command used when a task fails—is commonly employed to build resilient software systems, but implementing and testing it in modern systems is challenging. Based on real-world retry issues, the authors introduce a suite of static and dynamic techniques to detect retry problems. They found that the ad-hoc nature of retry implementation complicates traditional program analysis but that large language models (LLMs) can address these issues effectively. The research also demonstrates that repurposing unit tests, combined with fault injection, can reveal various retry issues.
Listen to research manager Shan Lu and PhD candidate Bogdan Stoica discuss this work in a recent podcast episode.
Scaling Deep Learning Computation over the Inter-Core Connected Intelligence Processor with T10
Yiqi Liu, Yuqi Xue, Yu Cheng, Lingxiao Ma, Ziming Miao, Jilong Xue, Jian Huang

Despite advances in AI chips that enable high-bandwidth and low-latency inter-core memory access, deep learning compilers lack support for scalable inter-core connections, limiting their potential. To address this, the authors introduce T10, an end-to-end deep learning compiler to take advantage of inter-core communication and distributed on-chip memory. T10 introduces a distributed tensor abstraction, rTensor, and maps the computation and communication of tensor operators with a generalized compute-shift pattern to cores. T10 optimizes on-chip memory consumption and inter-core communication overhead, selecting the best execution plan.
SilvanForge: A Schedule-Guided Retargetable Compiler for Decision Tree Inference
Ashwin Prasad, Sampath Rajendra, Kaushik Rajan, R Govindarajan, Uday Bondhugula
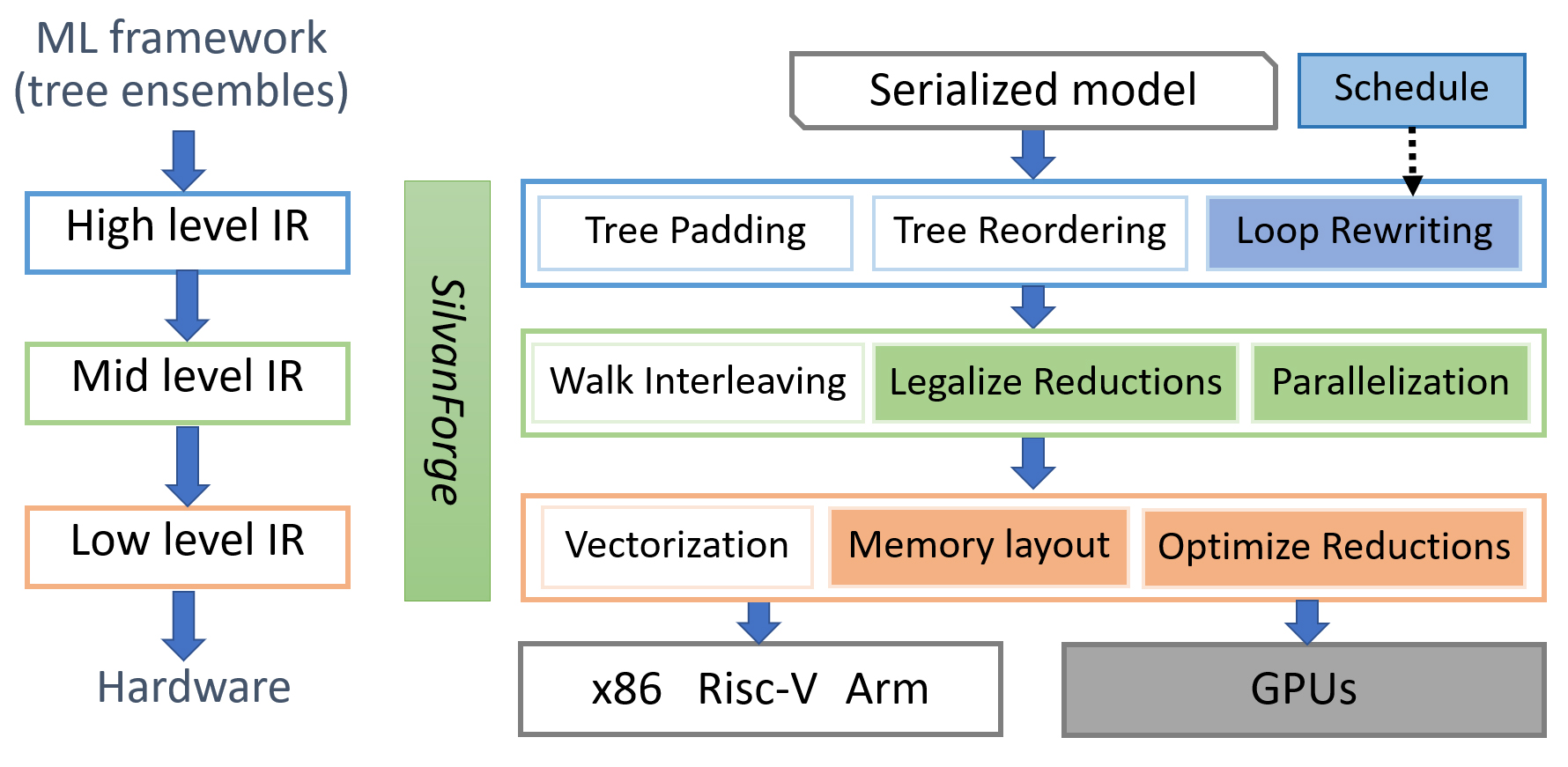
SilvanForge is a schedule-guided retargetable compiler for decision tree-based models that explores various optimization options and automatically generates high-performance inference routines for CPUs and GPUs. It consists of two core components: a scheduling language to efficiently explore the optimization space, and a retargetable compiler that generates code for any specified schedule. By utilizing different data layouts, loop structures, and caching strategies, SilvanForge achieves portable performance across multiple hardware targets.
Uncovering Nested Data Parallelism and Data Reuse in DNN Computation with FractalTensor
Siran Liu, Chengxiang Qi, Ying Cao, Chao Yang, Weifang Hu, Xuanhua Shi, Fan Yang, Mao Yang
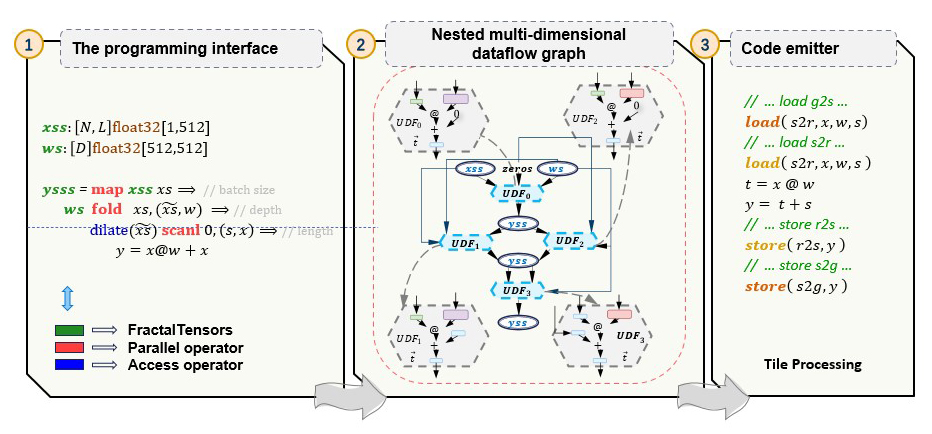
Deep neural networks (DNNs) often use highly optimized tensor operators to speed up computation, but these operators are typically defined empirically, limiting cross-operator analysis and optimization. FractalTensor addresses this by introducing a nested list-based abstract data type (ADT), where each element is either a tensor with a static shape or another FractalTensor. DNNs are then defined using high-order compute operators like map/reduce/scan and data access operators like window/stride, explicitly exposing nested data parallelism and fine-grained access patterns. This approach enables entire program analysis and optimization. This paper will only be available in the SOSP 2024 proceedings.
Unearthing Semantic Checks for Cloud Infrastructure-as-Code Programs
Yiming Qiu, Patrick Tser Jern Kon, Ryan Beckett, Ang Chen
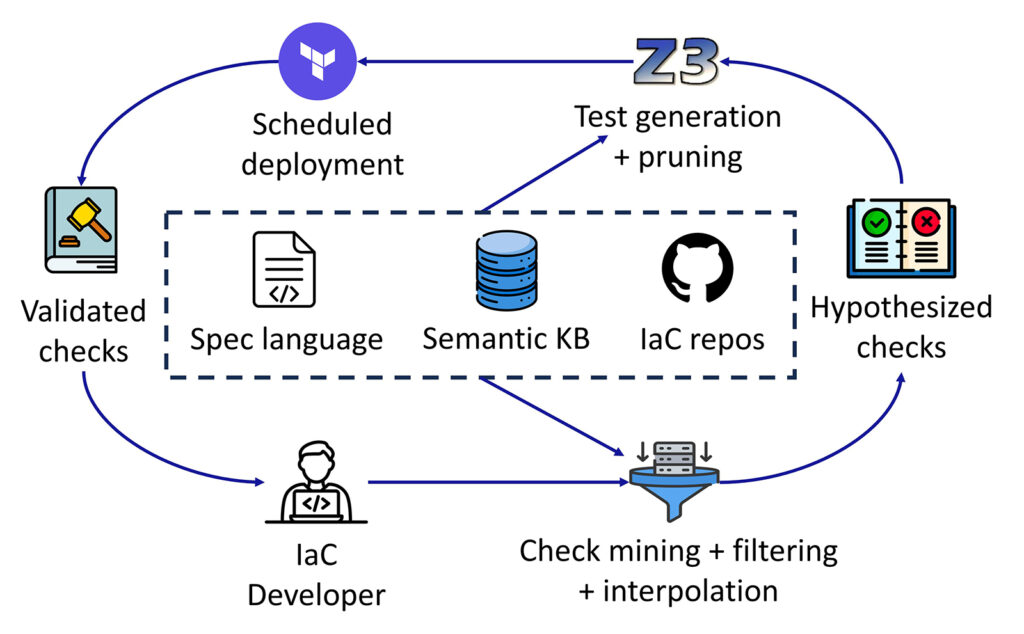
This research introduces Zodiac, a tool that uses semantic-guided mining and deployment-based validation pipelines to automatically uncover cloud IaC semantic checks. When applied to Microsoft Azure resources, Zodiac identified over 400 semantic checks that would cause deployment failures if violated, demonstrating its ability to detect cloud requirements that are difficult for state-of-the-art IaC tools to find.
Paper and tutorial
Verus: A Practical Foundation for Systems Verification
Distinguished Artifact Award
Chris Hawblitzel, Jay Lorch
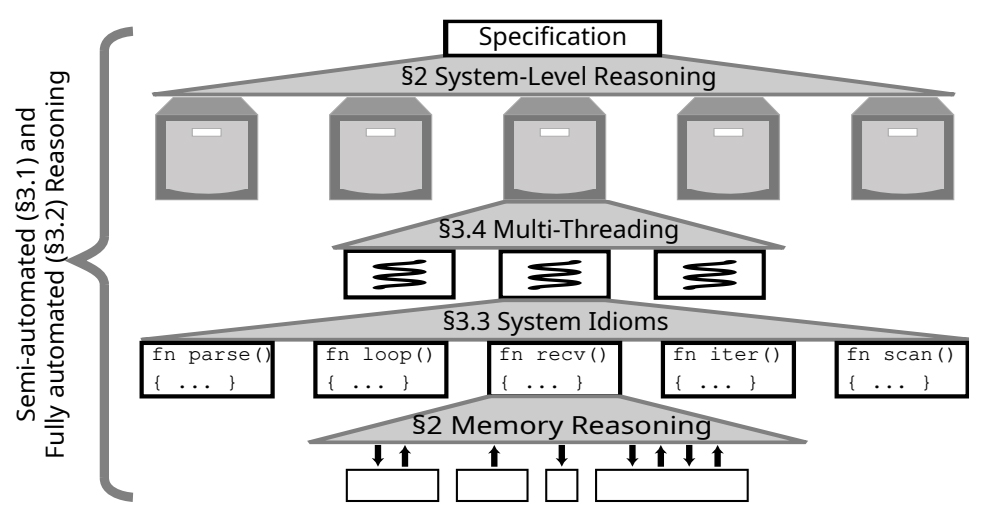
This work presents an updated version of Verus, a tool that accelerates and simplifies formal verification of system software. It builds on previous advances for faster and more cost-effective verification of complex properties in realistic systems and now verifies code up to 61 times faster than existing methods. It has been evaluated on various systems encompassing 6,100 lines of code and 31,000 lines of proof. Verus is ready for broader adoption by developers using Rust who want to create more robust systems.
Listen to principal researchers Chris Hawblitzel and Jay Lorch discuss this work in a recent podcast episode.
Workshops
Hot Topics in System Infrastructure (opens in new tab)
Inigo Goiri (opens in new tab), Pantea Zardoshti
Researchers and engineers share recent findings and experiences while exploring new challenges and opportunities in building next-generation infrastructures, including AI, sustainable datacenters, and edge and cloud computing. Topics span the entire system stack, focusing on design and implementation, hardware architecture, operating systems, runtimes, and applications.
Practical Adoption Challenges of ML for Systems (opens in new tab)
Despite significant progress in machine learning, deploying it in computer systems is rare due to non-machine learning challenges like feature stability, reliability, and availability. This workshop brings together researchers from academia and industry communities to foster communication and collaboration in addressing these practical issues and aligning research with real-world system deployment needs.
Discover how interdisciplinary systems research is driving innovation at Microsoft.