
This research was accepted by the 2023 International Conference on Learning Representations (ICLR) (opens in new tab), which is dedicated to the advancement of the branch of artificial intelligence generally referred to as deep learning.
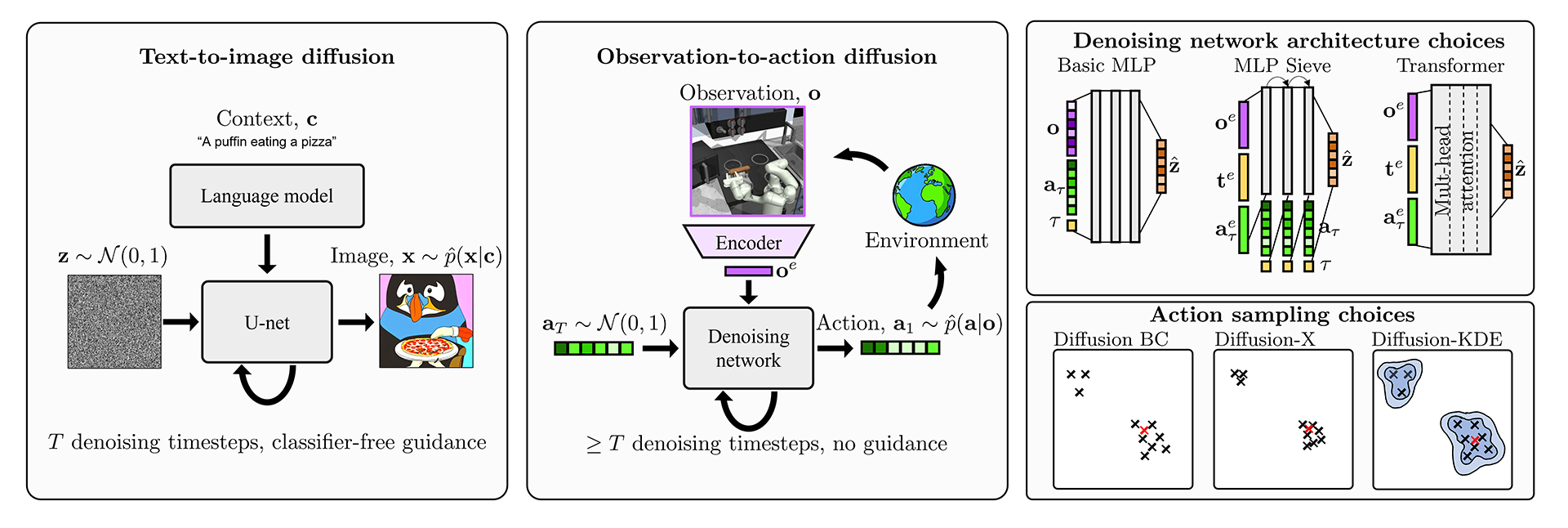
Diffusion models have emerged as a powerful class of generative AI models. They have been used to generate photorealistic images and short videos, compose music, and synthesize speech. And their uses don’t stop there. In our new paper, Imitating Human Behaviour with Diffusion Models, we explore how they can be used to imitate human behavior in interactive environments.
This capability is valuable in many applications. For instance, it could help automate repetitive manipulation tasks in robotics, or it could be used to create humanlike AI in video games, which could lead to exciting new game experiences—a goal particularly dear to our team.
We follow a machine learning paradigm known as imitation learning (more specifically behavior cloning). In this paradigm, we are provided with a dataset containing observations a person saw, and the actions they took, when acting in an environment, which we would like an AI agent to mimic. In interactive environments, at each time step, an observation \( o_t \) is received (e.g. a screenshot of a video game), and an action \( a_t \) is then selected (e.g. the mouse movement). With this dataset of many \( o \)’s and \( a \)’s performed by some demonstrator, a model \( \pi \) could try to learn this mapping of observation-to-action, \( \pi(o) \to a \).
Spotlight: Microsoft research newsletter

Microsoft Research Newsletter
When the actions are continuous, training a model to learn this mapping introduces some interesting challenges. In particular, what loss function should be used? A simple choice is mean squared error, as often used in supervised regression tasks. In an interactive environment, this objective encourages an agent to learn the average of all the behaviors in the dataset.
If the goal of the application is to generate diverse human behaviors, the average might not be very useful. After all, humans are stochastic (they act on whims) and multimodal creatures (different humans might make different decisions). Figure 2 depicts the failure of mean squared error to mimic the true action distribution (marked in yellow) when it is multimodal. It also includes several other popular choices for the loss function when doing behavior cloning.

Ideally, we’d like our models to learn the full variety of human behaviors. And this is where generative models help. Diffusion models are a specific class of generative model that are both stable to train and easy to sample from. They have been very successful in the text-to-image domain, which shares this one-to-many challenge—a single text caption might be matched by multiple different images.
Our work adapts ideas that have been developed for text-to-image diffusion models, to this new paradigm of observation-to-action diffusion. Figure 1 highlights some differences. One obvious point is that the object we are generating is now a low-dimensional action vector (rather than an image). This calls for a new design for the denoising network architecture. In image generation, heavy convolutional U-Nets are in vogue, but these are less applicable for low-dimensional vectors. Instead, we innovated and tested three different architectures shown in Figure 1.
In observation-to-action models, sampling a single bad action during an episode can throw an agent off course, and hence we were motivated to develop sampling schemes that would more reliably return good action samples (also shown in Figure 1). This problem is less severe in text-to-image models, since users often have the luxury of selecting a single image from among several generated samples and ignoring any bad images. Figure 3 shows an example of this, where a user might cherry-pick their favorite, while ignoring the one with nonsensical text.
We tested our diffusion agents in two different environments. The first, a simulated kitchen environment, is a challenging high-dimensional continuous control problem where a robotic arm must manipulate various objects. The demonstration dataset is collected from a variety of humans performing various tasks in differing orders. Hence there is rich multimodality in the dataset.
We found that diffusion agents outperformed baselines in two aspects. 1) The diversity of behaviors they learned were broader, and closer to the human demonstrations. 2) The rate of task completion (a proxy for reward) was better.
The videos below highlight the ability of diffusion to capture multimodal behavior–starting from the same initial conditions, we roll out the diffusion agent eight times. Each time it selects a different sequence of tasks to complete.








The second environment tested was a modern 3D video game, Counter-strike. We refer interested readers to the paper for results.
In summary, our work has demonstrated how exciting recent advances in generative modeling can be leveraged to build agents that can behave in humanlike ways in interactive environments. We’re excited to continue exploring this direction – watch this space for future work.
For more detail on our work, please see our paper (opens in new tab) and code repo (opens in new tab).