

Variance Reduction (VR) is a popular topic that is frequently discussed in the context of A/B testing. However, it requires a deeper understanding to maximize its value in an A/B test. In this blog post, we will answer questions including: What does the “variance” in VR refer to? Will VR make A/B tests more trustworthy? How will VR impact the ability to detect true change in A/B metrics?
This blog post provides an overview of ExP’s implementation of VR, a technique called CUPED (Controlled experiment Using Pre-Experiment Data). Other authors have contributed excellent explainers of CUPED’s performance and its ubiquity as an industry-standard variance reduction technique [1][2]. We have covered in previous blog posts how ExP uses CUPED in the experiment lifecycle [3].
In this post, we share the foundations of VR in statistical theory and how it amplifies the power of an A/B testing program without increasing the likelihood of making a wrong decision. [a][4]
[a] Many of the elements covered quickly in this blog are covered in excellent detail in Causal Inference and Its Applications in Online Industry [4].
Variance is a Statistical Property of Estimators
To understand where variance reduction fits in, let’s start with a more fundamental question: What’s our ideal case for analyzing an A/B test? We want to estimate the difference in two potential outcomes for a user: the outcome in a world where the treatment was applied, and the outcome in a world where the treatment was not applied – the counterfactual.
The fundamental challenge of causal inference is that we cannot observe those two worlds simultaneously, and so we must come up with a process for estimating the counterfactual difference. In A/B testing, that process relies on applying treatments to different users. Different users are never perfect substitutes for one another because their outcomes are not only functions of the treatment assignment, but also impacted by many other factors that influence user behavior.
Causal inference is a set of scientific methods to estimate the counterfactual difference in potential outcomes between our two imagined worlds. Any process of estimating this counterfactual difference introduces uncertainty.
Statistical inference is the process of proposing and refining estimators of an average counterfactual difference to improve the estimators’ core statistical properties:
- asymptotic bias, or consistency;
- rate of convergence to this asymptotic bias; and
- variance.
In fact, that’s what the “variance” in variance reduction refers to: the property of the estimator of the average treatment effect. Variance reduction (as in CUPED-VR) is not a reduction in variance of underlying data such as when sample data is modified through outlier removal, capping, or log-transformation. Instead, variance reduction refers to a change in the estimator which produces estimates of the treatment effect with lower standard error.
The Difference-in-Means Estimator Provides Consistency in A/B tests
Random assignment ensures that the difference between treatment and control populations is an unbiased estimator. However, we need to consider how much uncertainty our estimation process has introduced.
To do so, we use the known rate of convergence to the true population difference – called consistency – to estimate the true variance of the average treatment effect using our sample. With the delta estimate from difference-in-means (\( \delta_{DiM}\)) and the sample variance estimate, we report an interval of estimates that is likely to contain the true population difference, called a confidence interval:
\( \begin{aligned} Var(\delta_{DiM}) &=\frac{ \sigma_{Y^T}^2}{{n^T}} + \frac{ \sigma_{Y^C}^2}{n^C} \\ CI_{lb,ub}&= \delta_{DiM} \pm z_{\alpha/2}\sqrt{Var(\delta_{DiM})} \\ \end{aligned} \) [b]
The difference-in-means estimator for the average treatment effect is unbiased, and the variance of the estimator shrinks at a known rate as the sample size grows. When we propose VR estimators, we’ll need to describe their relationship to the bias, variance, and the consistent variance estimate of the difference-in-means estimator to understand if we’re improving.
[b] \( z_{\alpha/2} \) is the standard normal quantile at your acceptable \( \alpha \), or false positive rate. For example, a 95% confidence interval uses 1.96 for \( z_{0.05/2} \).
CUPED-VR Outperforms the Difference-in-Means Estimator
Statistical tests that use variance reduction rely on an additional strategy to reduce the variance of an estimator of average treatment effect, which has a similar power benefit to increasing the A/B test sample size.
This is rooted in the insight that even if we have a single-user treatment and single-user control, if the users are good substitutes for one another, we’ll expect to obtain a treatment effect estimate that’s closer to the true treatment effect than if the users are very different from one another. The assignment procedure can be modified to try to ensure “balanced” treatment and control assignments. Re-randomization of assignments with checks to ensure baseline balance uses this idea [5].
In many online A/B tests, we don’t modify our assignment procedure. Instead, we perform a correction in the analysis phase with VR estimators. VR combines large-sample asymptotic properties of A/B tests with the optimization of comparing similar users through statistical adjustment. Similarity is modeled through use of characteristics known to be independent of the assignment of A or B test feature to the user.
CUPED-VR Procedure
CUPED is one method of VR, with the following steps:
- Linear models \( \vec Y_i \sim \vec \theta \vec X_i \) are estimated separately for treatment and control (or with an assignment group indicator).
- The product of \( \hat \theta\) and the overall mean \( \overline X_i \) is subtracted from \( Y_i \), giving adjusted metric values \( Y_{CUPED,T} \) and \( Y_{CUPED,C} \). In each group, users’ adjusted metrics are shifted as a function of their similar prior characteristics.
- The difference in the average adjusted metric values gives a still-consistent and lower-variance estimate of the average treatment effect estimand.
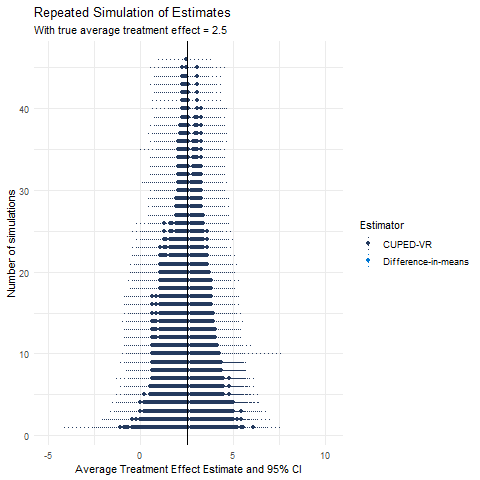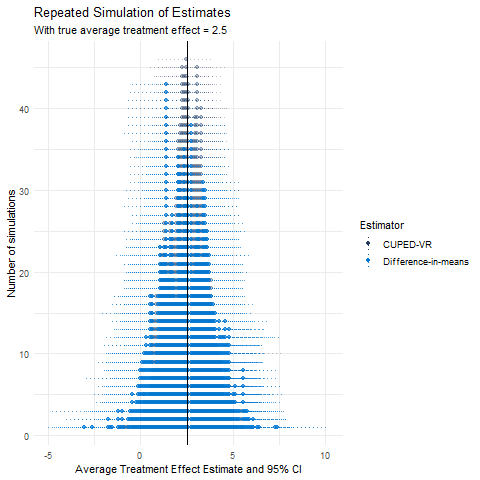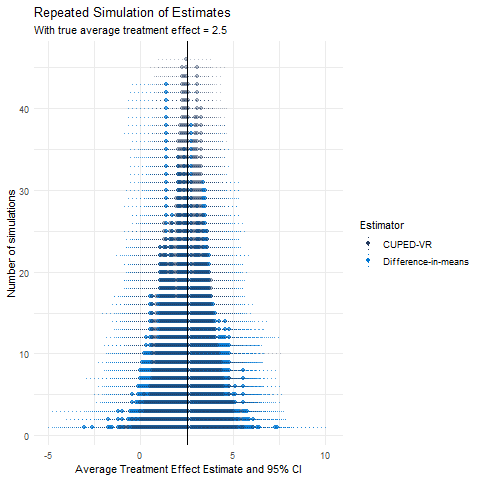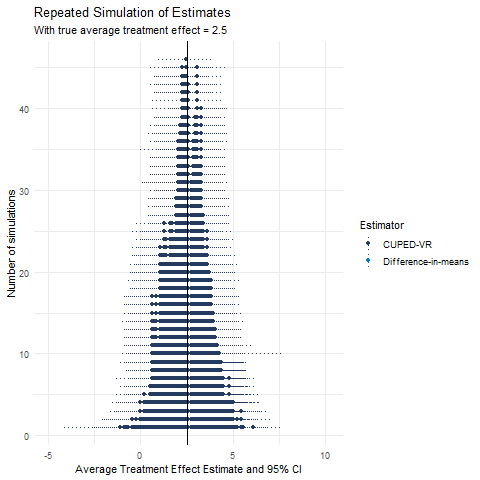
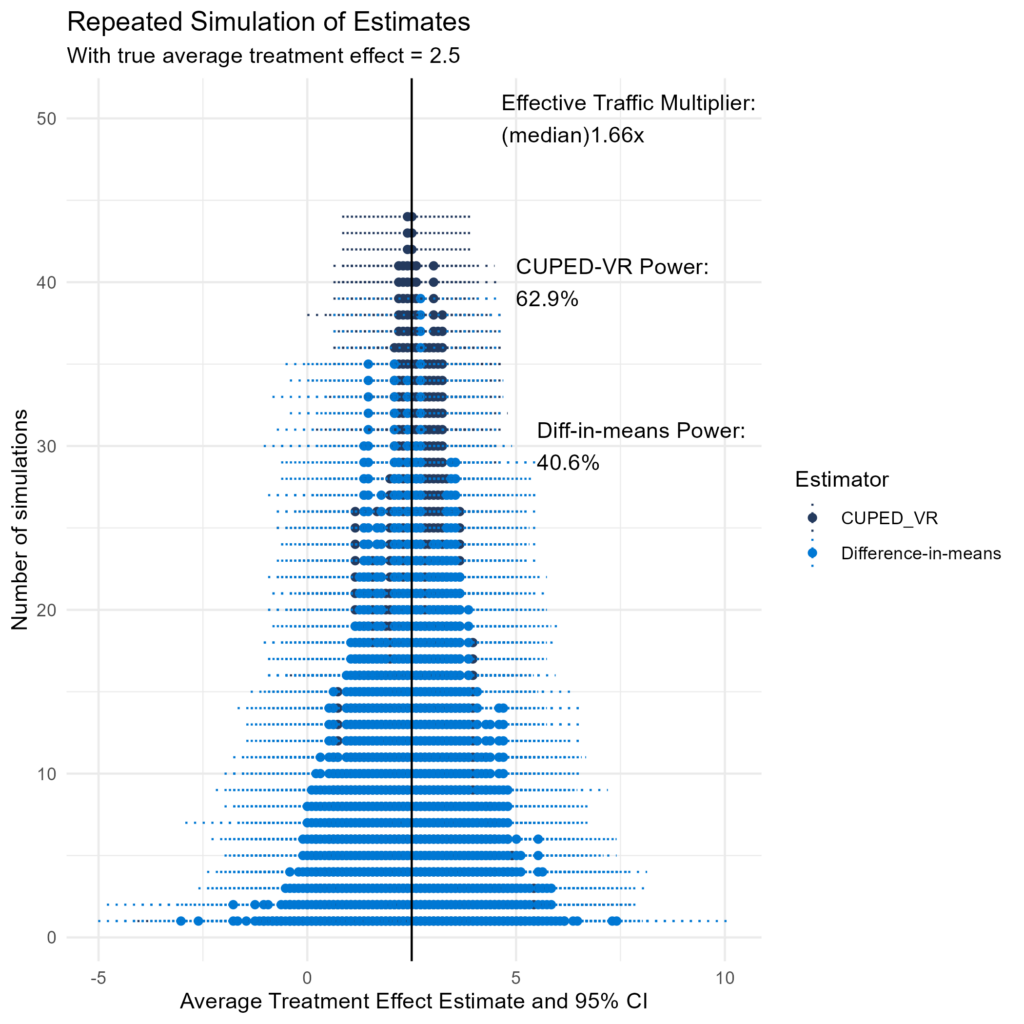
From simulating CUPED-VR’s performance versus difference-in-means on repeated samples of the same data, we can observe the extent of variance reduction for the estimator (plot below). In this plot of estimates, the set of estimates that are closer to the true effect of 2.5 compared to the difference-in-means estimates on the same trial are shifted because, in those trials, CUPED-adjusted metrics accounted for chance imbalance in the pre-A/B test period.
When the estimated coefficients are weighted by assignment probability, the CUPED-VR estimator is equivalent to another popular regression adjustment estimator for A/B tests: ANCOVA2, or Lin’s estimator [6][7] [Table 1].
Measuring CUPED-VR Performance with Effective Traffic Multiplier
The CUPED-VR estimator has known analytic results [7] of how its variance compares to the variance of the difference-in-means estimator:
\(\begin{aligned} Var(\delta_{VR}) &=(\frac{ \sigma_{Y^T}^2}{n^T} + \frac{ \sigma_{Y^C}^2}{n^C}) (1 – R^2) \\ Var(\delta_{DiM}) &=\frac{ \sigma_{Y^T}^2}{n^T} + \frac{ \sigma_{Y^C}^2}{n^C} \\ \end{aligned} \)The variance is reduced in proportion to the amount of variance explained by the linear model in treatment and control, or the total \( R^2 \). And, importantly, the estimator is still consistent: We don’t sacrifice bias in favor of lower variance. This means that when we estimate the variance of our \( \delta_{VR} \) , we can build narrower confidence intervals, with values that are closer to the \( \delta_{VR} \) but reflect the same level of confidence about the range. This also means that if the true treatment effect is non-zero, we are more likely to detect a statistically significant effect. Indeed, the ratio of raw variance to VR variance \( \frac{1}{1-R^2} \) represents the amount of traffic that would need to be added to the simple difference estimator to provide the same level of variance reduction as VR.
Decision-makers understand that having more traffic in an A/B test for a given time period helps decrease time-to-decision or increase confidence in a decision if evaluating at a fixed time. And at ExP, we have found this to be an easy-to-interpret representation of VR’s efficacy for Microsoft experimenters. We surface it for each variance-reduced metric and refer to it as the “effective traffic multiplier”.
The effectiveness of CUPED-VR is influenced by various attributes of the product, telemetry, experiment, and metric. At Microsoft, we see substantial difference in efficacy across different product surfaces and metric types.
Based on a recent 12-week sample of week-long experiments, groups of VR metrics from two different surfaces for the same product have very different average performance. In one Microsoft product surface, VR is not effective for most metrics: a majority of metrics (>68%) have effective traffic multiplier <=1.05x. In contrast, another product surface sees substantial gain from VR methods: a majority of metrics (>55%) have effective traffic multiplier >1.2x.
Summary
Variance reduction is the use of alternative estimators, like CUPED, to improve difference-in-means and effectively multiply observed traffic in an A/B test. Its variance-reducing properties are rooted in the foundations of design-based statistical inference, which makes it a trustworthy estimator at scale.
– Laura Cosgrove, Jen Townsend, and Jonathan Litz, Microsoft Experimentation Platform
CUPED-VR and ANCOVA2 Comparison Table
| Estimator | Procedure |
| ANCOVA2[6][7] | \(\begin{aligned} \\ Y_i &= \beta_0 + \delta T_i + \beta ( X_i – \overline X) + \gamma ( X_i – \overline X) T_i + \epsilon_i \\ \delta &= \hat \delta \end{aligned} \) |
| CUPED-VR | \( \begin{aligned}\\ Y_i^T &= \beta_0^T + \theta^T X_i^T + \epsilon_i^T \\ Y_i^C &= \beta_0^C + \theta^C X_i^C + \epsilon_i^C \\ Y_i^{CUPED, T} &= Y_i^T – (p\hat {\theta^C} + (1-p) \hat {\theta^T})* X_i^T \\ Y_i^{CUPED, C} &= Y_i^C – (p\hat {\theta^C} + (1-p)\hat {\theta^T})*X_i^C \\ \delta &= \overline Y^{CUPED, T} – \overline Y^{CUPED, T} \end{aligned} \) |
References
[1] Berk, M. (2021) How to Double A/B Testing Speed with Cuped, Towards Data Science. Available at: https://towardsdatascience.com/how-to-double-a-b-testing-speed-with-cuped-f80460825a90 (opens in new tab) (Accessed: November 1, 2022).
[2] Craig (2022) Cuped on Statsig, Medium. Available at: https://blog.statsig.com/cuped-on-statsig-d57f23122d0e (opens in new tab)(Accessed: November 1, 2022).
[3] Machmouchi, W., et al. (2021) Patterns of Trustworthy Experimentation: Pre-Experiment Stage, Microsoft Research. Available at: http://approjects.co.za/?big=en-us/research/group/experimentation-platform-exp/articles/patterns-of-trustworthy-experimentation-pre-experiment-stage/ (Accessed: November 1, 2022).
[4] Deng, A., 2021. Causal Inference and Its Applications in Online Industry. [online] Alexdeng.github.io. Available at: <https://alexdeng.github.io/causal/index.html (opens in new tab)> [Accessed 5 July 2022].
[5] Zhao, A. and Ding, P. (2021) No star is good news: A unified look at rerandomization based on $p$-values from covariate balance tests, arXiv.org. Available at: https://arxiv.org/abs/2112.10545 (opens in new tab) (Accessed: November 1, 2022).
[6] Lin, W. (2013). Agnostic notes on regression adjustments to experimental data: Reexamining Freedman’s critique. Annals of Applied Statistics, 7, 295–318.
[7] Deng, A., 2021. Chapter 10: Improving Metric Sensitivity. Causal Inference and Its Applications in Online Industry. [online] alexdeng.github.io. Available at: <https://alexdeng.github.io/causal/index.html (opens in new tab)> [Accessed 5 July 2022].