

About
Lijuan Wang is Principal Research Manager in Microsoft Cloud & AI. She joined Microsoft Research Asia as a researcher in 2006 after she received her PhD from Tsinghua University, China. In 2016, she joined Microsoft Research in Redmond. Her research areas include deep learning and machine learning on multimodal perception intelligence. Over the years, she has been the key contributor in developing technologies on vision-language pretraining, image captioning, object detection, and other associated areas. These technologies have been shipped in many Microsoft products, from Cognitive Services to Office 365. She has published 50+ papers on top conferences and journals, and she is the inventor/co-inventor of more than 15+ granted or pending US patents. She is a senior member of IEEE.
Featured content

AI advances in image captioning: Describing images as well as people do webinar
Vision-language pretraining (VLP) is pushing AI forward in novel object captioning and image caption generation more broadly. In a webinar, learn about powerful new VLP methods and how advances permit captioning without image-text pairs. Register now.
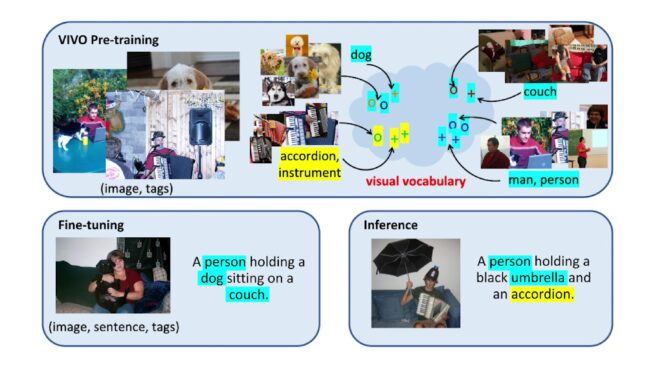
Novel object captioning surpasses human performance on benchmarks
Consider for a moment what it takes to visually identify and describe something to another person. Now imagine that the other person can’t see the object or image, so every detail matters. How do you decide what information is important…
VIVO: Surpassing Human Performance in Novel Object Captioning with Visual Vocabulary Pre-Training
It is highly desirable yet challenging to generate image captions that can describe novel objects which are unseen in caption-labeled training data, a capability that is evaluated in the novel object captioning challenge (nocaps). In this challenge, no additional image-caption…
Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
Large-scale pre-training methods of learning cross-modal representations on image-text pairs are becoming popular for vision-language tasks. While existing methods simply concatenate image region features and text features as input to the model to be pre-trained and use self-attention to learn…
Skeletal Tracking on Azure Kinect
Microsoft has released a new RGB-D sensor called Azure Kinect. I'm involved in developing the skeletral tracking for Azure Kinect. It consists of 2D pose estimation and 3D model fitting. The 2D pose estimation is a neural network based solution and its input is thje IR image of the depth sensor.
High Quality Lip-Sync Animation for 3D Photo-Realistic Talking Head
We propose a new 3D photo-realistic talking head with high quality, lip-sync animation. It extends our prior high-quality 2D photo-realistic talking head to 3D. An a/v recording of a person speaking a set of prompted sentences with good phonetic coverage…
Text-driven 3D Photo-Realistic Talking Head
We propose a new 3D photo-realistic talking head with a personalized, photo realistic appearance. Different head motions and facial expressions can be freely controlled and rendered. It extends our prior, high-quality, 2D photo-realistic talking head to 3D. Around 20-minutes of…