

With advancements in science and technology happening at a mind-boggling pace, the formal recognition and classification of new concepts and fields of study is a constant struggle. Over the past year the Microsoft Academic Graph (MAG) team has tried to tackle this problem head-on with changes to both how we find and how we categorize new fields of study.
These efforts have resulted in MAG now understanding over 700k fields of study, with nearly 75% included in our field of study hierarchy. That marks a 3x increase from our most recent disclosure in our 2018 ACL demo paper (opens in new tab).
New Fields of Study
Since the publication of our 2018 ACL demo paper (opens in new tab), we have released two new field of study batches. The first batch is the result of a one-time effort which seeded concepts using the Unified Medical Language System (UMLS) (opens in new tab) vocabulary, allowing MAG to dramatically increase its understanding of biomedical research. The second batch is the result of an on-going effort that allows us to automatically discover and understand new concepts directly from academic literature, without the need to use pre-existing vocabulary seeds such as Wikipedia or UMLS.
Metrics for each release:

January 2019 update – Concepts seeded from Unified Medical Language System (UMLS)
The Unified Medical Language System (UMLS) (opens in new tab) is a repository of biomedical vocabularies developed by the US National Library of Medicine (NLM) (opens in new tab) with sources from multiple datasets and standards (opens in new tab). The latest 2019AB release (opens in new tab) contains more than 4 million medical concepts.
Large, complex data sources such as this typically have numerous, inherent limitations on their data quality. For UMLS these include structural inconsistencies such as cycles in graph hierarchy, semantic inconsistencies between different vocabularies and missing hierarchal relationships. See this journal article (opens in new tab) and this presentation (opens in new tab), both from the UMLS authors at NLM, for more detailed information.
To account for these issues, we conducted a rigorous process to determine which UMLS concepts met the bar to be included in MAG:
- Generated term frequency (TF) metrics for each UMLS concept in the full MAG document corpus
- Narrowed concepts to those not already in MAG, but with enough coverage in MAG documents
- Isolated paragraphs containing the concepts from documents on reputable websites (i.e. well-known publishers, academic news sources, etc.) with the help of the Bing index
- Applied concept modeling (as described here (opens in new tab)) to generate descriptions
This resulted in over 435k new, high quality biomedical concepts being identified and ingested as fields of study in MAG. To get a better sense for how much this benefited MAGs understanding of Biology and Medicine, it is worth looking at field of study distribution across top level fields over the past few years:
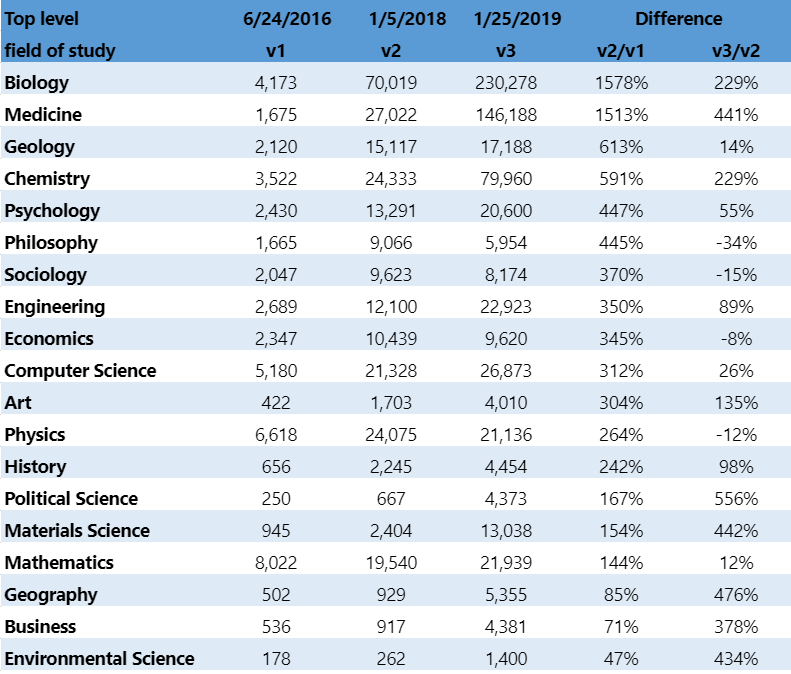
Not surprisingly, Biology, Medicine and Chemistry are the fields with the most benefits from the new concepts seeded using the UMLS vocabularies.
November/December 2019 update – Detection of emerging concepts from academic documents
The volume of new research being published is rapidly increasing, with MAG adding over 1 million new papers every month. This creates a unique challenge, as the new research comes along with a rich, ever-evolving set of emerging concepts. Identifying, describing and categorizing these new concepts in a timely fashion is an incredibly difficult task, which means timely inclusion in the data sources we traditionally use for seeds (Wikipedia, UMLS) virtually impossible.
To tackle this challenge, we have come up with a two-stage approach that allows us to extract both known and emerging concepts directly from MAG documents:
- Analyze document vocabulary (words, phrases) to identify field of study mentions; this is a binary label that does not indicate which field of study just that a given word/phrase should map to something
- Run classifier to map mentions to specific fields of studies; these can be either existing or new fields
In the first stage, we formulate the concept detection as a self-supervised sequence labeling (opens in new tab) problem. On a sampled set of MAG documents, we do lexical matching using the synonyms of our existing fields of study, which allows us to generate a binary label for each word indicating if we think it mentions a field of study or not. After generating these training labels, we fine-tune a transformer-based BERT model (opens in new tab) (e.g. BERT base) as a context encoder, and use a Conditional Random Field (CRF) (opens in new tab) layer as a tag decoder to train a binary classifier on each word in a sentence to detect field of study mentions. We then infer field of study mentions using the trained model on a larger set of high-quality MAG documents, i.e. those published in prestigious journals/conferences.
During the second stage, we classify the field of study mentions detected in the first stage into three broad categories:
- Existing concept
- New concept
- Low-quality word/phrase
This is accomplished by searching for each mention using the Bing Web Search API (opens in new tab) and clustering mentions into field of study “identities” based on the URL relevance/reputation and the consistency of the mention among top search results.
To ensure that this approach works for documents across various scientific domains, we conducted experiments training our model using documents in a single top domain (e.g. computer science) and with documents from mixed domains (e.g. computer science, biology). We observed that higher quality mentions are generated using models trained from a single domain rather than a mixture of multiple domains.
Based on this outcome, we applied this method to MAG documents from the Computer Science domain in November/December 2019. The result is over 45k new fields of study being identified, described and categorized in MAG.
An example of one of these new fields of study is Graph Neural Networks (opens in new tab) (GNN). As shown in the snapshot below, it is tagged with the most relevant and influential works in the GNN domain, such as node2vec and Graph Attention Networks (GAN); it also successfully identified the authors who pioneered the field (i.e. Jure Leskovec) together with other highly related (and newly discovered!) fields of study Network Embedding (opens in new tab) and Network Representation Learning (opens in new tab).
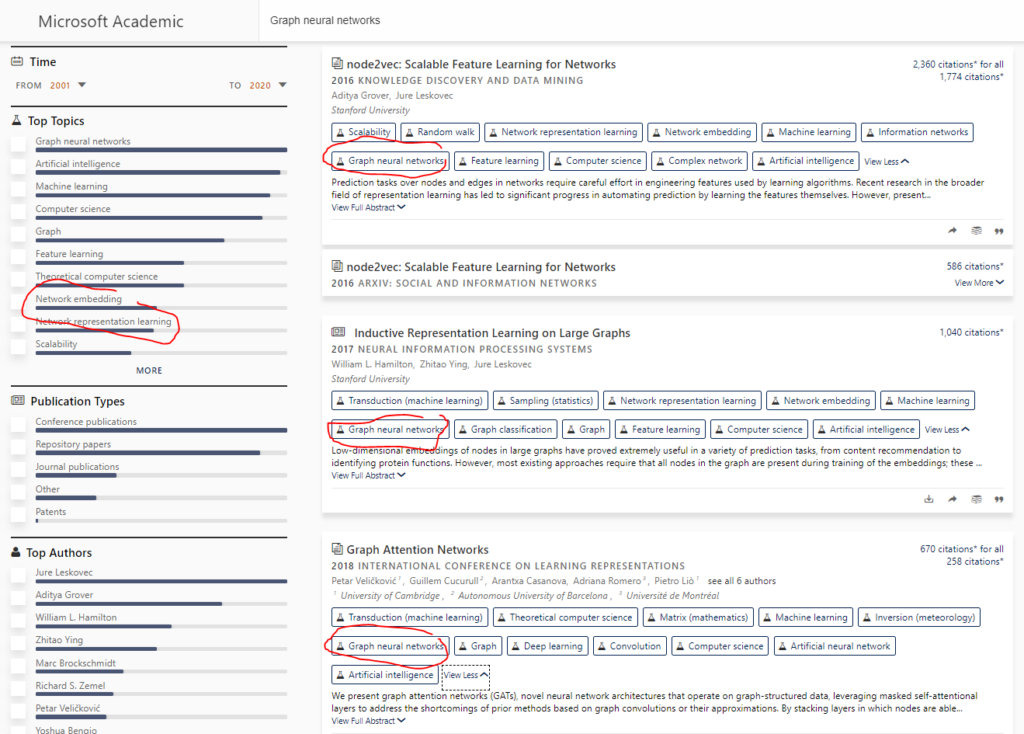
We have also enabled acronym detection for these new emerging concepts, which you can see the benefit of in Microsoft Academic’s query formulation experience:

Field of Study Hierarchy Updates
Whenever we generate major new field of study updates for MAG, we also reconstruct our field of study hierarchy to include the new fields. To accomplish this, we manually curate the two top-most levels of the hierarchy to ensure accuracy, and then use the subsumption-based model described here to generate the remaining levels.
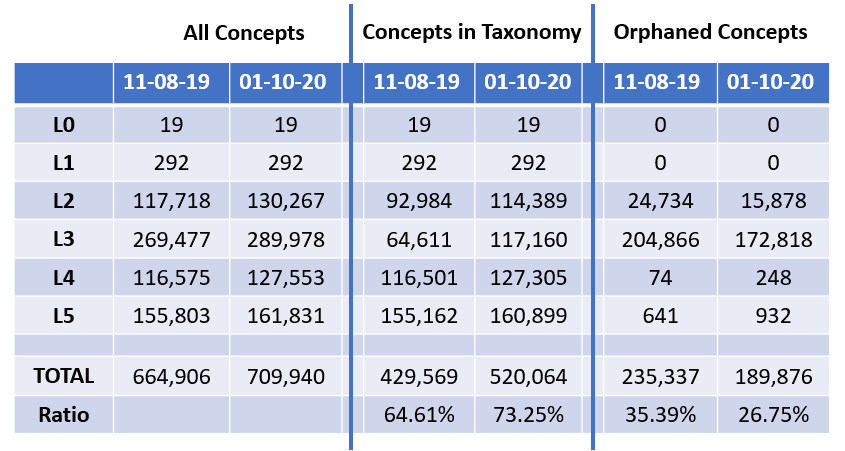
Unfortunately, one known limitation of the subsumption-based model is missing relationships among fields of study with sparse references in the document corpus. In this case we treat the field of study as an orphan, meaning it does not have sufficient evidence to identify an immediate parent or child hierarchical relationship, which is a requirement for placement in MAG’s formal hierarchy (FieldOfStudyChildren) (opens in new tab). As shown in the table above, this occurs for approximately 25% of all fields of study.
When this happens we still attempt to identify an appropriate hierarchical level for each orphaned field of study:
- For ~90% of orphaned fields of study we lack sufficient data to associate the field of study with another field of study. These are associated with a default value of L3.
- For ~10% of orphaned fields of study we have sufficient data to associate the field of study with an L0 domain (i.e. Computer Science, Biology), but know that based on the quantity of papers labeled with it, it does not qualify as an L1 field of study. These are associated as L2.
- For <1% of orphaned fields of study, we have data to associate the field of study with an L3/L4 field of study, but it is insufficient to form a concrete link. These are associated as L4/L5.
Regardless, equipped with the new 45K+ emerging concepts, our machine reading agents have been able to understand a significantly larger portion of MAG documents. Between the two MAG versions where the new emerging concepts were released (11-08-19 version vs. 01-10-20 version), we observed a 13.4% improvement (from 64.61% to 73.25%) in field of study coverage in the hierarchy.
Another example that spans both the emerging field of study detection and hierarchy updates is network embedding (opens in new tab), a research topic popularized in recent years among machine learning and deep learning communities. In our hierarchy, it is an L4 concept, with embedding (opens in new tab) as a parent field of study. As you can see in the screenshot below, its popularity as an emerging field of study is obvious by the fast-growing counts of publications and citations since 2016.

It is also shown as one of the top five trending topics under embedding.

Hierarchy data quality issue identified in December 2019/January 2020
Unfortunately, along with amazing progress also comes the occasional mistake.
During December 2019 and early January 2020, there were discussions on social media regarding some unexpected changes in relationships between L0 and L1 domains in our field of study hierarchy. It was the result of an unintended update due to backend engineering glitches and has since been fixed since our Jan-10-2020 graph release. We apologize for any issues this may have caused, and advise our customers not to use the L0 and L1 field of study hierarchy relationships in the following MAG versions:
- Nov-22-2019
- Dec-05-2019
- Dec-13-2019
- Dec-26-2019
We love feedback!
We would love to hear about your experiences in exploring the new expanded fields of study in MAG! Feel free to share your experiences using the feedback link at the bottom right of Microsoft Academic (opens in new tab), or if so inclined on Twitter @MSFTAcademic.
Happy researching!