

AI at Scale
Models, infrastructure and hardware for next-generation AI applications
-
2021Sep
Microsoft Turing Universal Language Representation model, T-ULRv5, tops XTREME leaderboard and trains 100x faster
Our latest Turing universal language representation model (T-ULRv5), a Microsoft-created model is once again the state of the art and at the top of the Google XTREME public leaderboard (opens in new tab). Resulting from a collaboration between the Microsoft Turing (opens in new tab) team and Microsoft Research, the 2.2 billion-parameter T-ULRv5 XL outperforms the current 2nd best model by an average score of 1.7 points. It is also the state of the art across each of the four subcategories of tasks on the leaderboard. These results demonstrate the strong capabilities of T-ULRv5, which, in addition to being more capable, trains 100 times faster than its predecessors.
-
2021Aug
Make Every feature Binary (MEB)
The Microsoft Bing team developed and operationalized “Make Every feature Binary” (MEB), a large-scale sparse model that complements production Transformer models to improve search relevance. To make search more accurate and dynamic, MEB is a 135B parameter model which harnesses the power of large data and allows for an input feature space with over 200 billion binary features that reflect the subtle relationships between search queries and documents.
-
DeepSpeed powers 8x larger MoE model training with high performance
DeepSpeed continues to innovate, enabling mixture of experts model training with bigger size, fewer resources, excellent throughput, and near-linear scalability. It combines multidimensional parallelism and heterogenous memory technologies to support massively large MoE models. Model scientists of Microsoft use DeepSpeed MoE to train Z-code MoE, a production-quality, multi-lingual, and multi-task language model with 10 billion parameters, achieving state-of-the-art results on machine translation and cross-lingual summarization tasks.
-
2021May
DeepSpeed: 3 times faster, 5 times cheaper inference for large DL models
The DeepSpeed library has improved scale, speed, cost, and usability for large model training by orders of magnitude. Now, the team introduces DeepSpeed Inference — with high-performance multi-GPU inference and mixture of quantization — to significantly reduce the latency and cost of serving large DL models. The team also announce a suite of new features for compressed training, such as progressive layer dropping and 1-bit LAMB, to achieve fast and accurate training with low cost.
-
2021Apr
ZeRO-Infinity

The DeepSpeed Team releases ZeRO-Infinity, a novel heterogeneous system technology that leverages GPU, CPU, and NVMe memory to allow for unprecedented model scale on limited resources without requiring model code refactoring. At the same time it achieves excellent training throughput and scalability, unencumbered by the limited CPU or NVMe bandwidth. ZeRO-Infinity can fit models with tens and even hundreds of trillions of parameters for training on current generation GPU clusters. It can be used to fine-tune trillion parameter models on a single NVIDIA DGX-2 node, making large models more accessible. In terms of training throughput and scalability, it sustains over 25 petaflops on 512 NVIDIA V100 GPUs (40\% of peak), while also demonstrating super linear scalability.
-
2021Mar
The best of AI at Scale: Semantic search capabilities available to Azure customers in preview
Microsoft Bing partnered with Azure Cognitive Search to make state-of-the-art search AI available to Azure customers through semantic search. Semantic search enables modern search experiences such as semantic ranking, extractive summarization, and machine reading comprehension. These features were built through the application of Microsoft Research technology and advancements—including UniLM, Multi-Task Deep Neural Networks, MiniLM, and utilizing graph attention networks for machine reading comprehension—to search scenarios. Deep neural network transfer learning allows the models to run well in Azure. An online A/B experiment in which semantic search was enabled for Microsoft Docs produced a significant 4.5 percent clickthrough rate increase on challenging queries (three or more words)—the largest relevance improvement the Microsoft Docs team has seen.
-
2021Feb
Spell correction at scale
Customers around the world use Microsoft products in over 100 languages, yet most do not come with high-quality spell correction. This prevents customers from maximizing their ability to search for information on the web and enterprise—and even to author content. With AI at Scale, we used deep learning along with language families to solve this problem for customers by building what we believe is the most comprehensive and accurate spelling correction system ever in terms of language coverage and accuracy.
-
2021Jan
DeBERTa
Updates to the Transformer-based DeBERTa neural language model boost its performance, topping the SuperGLUE and GLUE benchmark leaderboards. The updates include training a larger version of the model that contains 48 Transformer layers and 1.5 billion parameters. The updated single version of DeBERTa surpasses human performance on the SuperGLUE benchmark for the first time based on macro-average score, while the ensemble model outperforms the single version to top both leaderboards. DeBERTa is being incorporated into the next iteration of the Microsoft Turing natural language representation model, Turing NLRv4.
-
VinVL
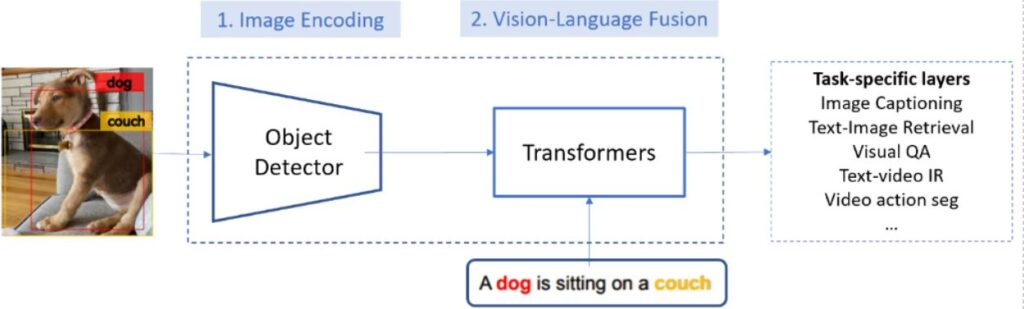
Researchers from Microsoft have developed a new object-attribute detection model for image encoding, dubbed VinVL (Visual features in Vision-Language), and performed a comprehensive empirical study to show that visual features matter significantly in VL models.
-
2020Dec
Project Brainwave + Microsoft Floating Point
Microsoft researchers and engineers announced Microsoft Floating Point, a data type that brings together the efficiency of integer data types with accuracy comparable to floating point. It’s being used in Project Brainwave architecture to power real-time production-scale deep neural network inference in the cloud, and it enables features in many Microsoft products, including Office 365 and Bing. Project Brainwave architecture—to be turbocharged by silicon-hardened Microsoft Floating Point—is expected to have a pivotal role in the future of algorithm codesign in hardware.
-
2020Nov
SC-GPT model: Using few-shot natural language generation for task-oriented dialog
In this work, Microsoft researchers set out to improve generalization with limited labelled data for natural language generation (NLG) models. To do so, they developed the first NLG benchmark to simulate few-shot learning in task-oriented dialog systems. They also created the SC-GPT model, a multi-layer Transformer neural language model, which generates semantically controlled responses conditioned on a given semantic form and requires much fewer domain labels to generalize to new domains.
-
2020Oct
Turing Universal Language Representation model takes top spot on XTREME leaderboard
TULRv2, the Turing Universal Language Representation model for cross-lingual generalization, tops the Google XTREME leaderboard. The model uses another recent Microsoft innovation, InfoXLM, to create a universal model that represents 94 languages in the same vector space, and it is being used to power features in Microsoft Word, Outlook, and Teams. The XTREME leaderboard covers 40 languages spanning 12 language families, and it challenges models to reason about syntax and semantics at varying levels.
-
2020Sep
Bing announces updates that make use of Turing Natural Language Generation and expanded use of Turing Natural Language Representation
Bing announces new updates for search utilizing Microsoft Turing capabilities (opens in new tab). These included improvements for Autosuggest, the “People Also Ask” (PAA) feature, an expansion of cross-lingual intelligent answers to over 100 languages and 200 regions, and semantic highlighting for captions to better highlight answers in search.
-
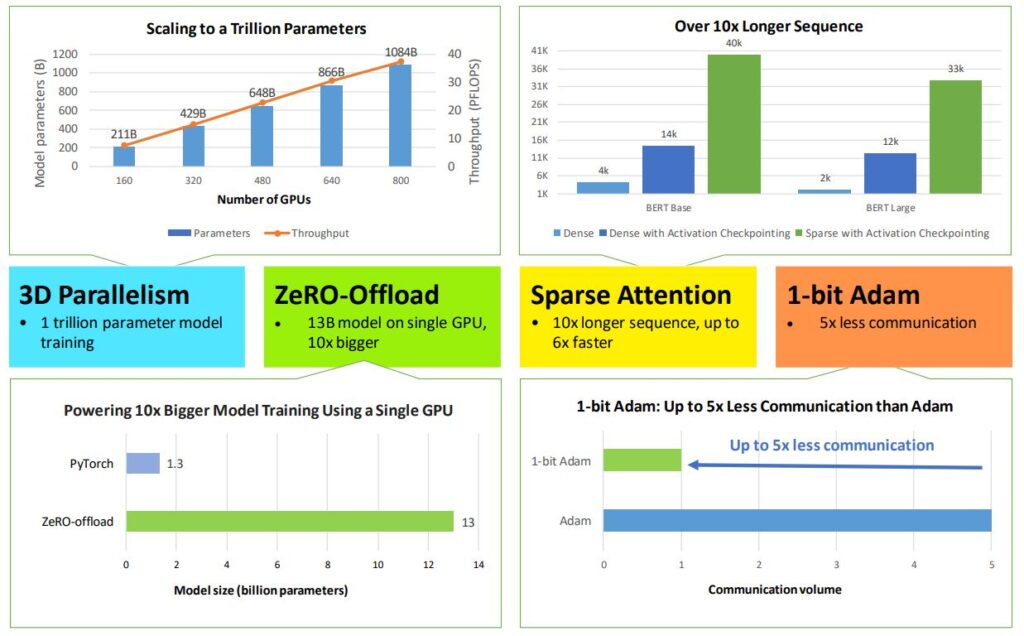
Updates and optimizations for the DeepSpeed library announced
Microsoft researchers worked hard all year to make significant updates to the DeepSpeed deep learning training optimization library. In this release, researchers introduced 3D parallelism, ZeRO-Offload, DeepSpeed Sparse Attention, and 1-bit Adam. These updates, among other advances, allowed more people to use DeepSpeed with fewer resources and expanded the scope of its efficiency across compute, memory, and communication, enabling training of models up to 1 trillion parameters.
-
2020Jun
DeBERTa: Decoding enhanced BERT with disentangled attention
Microsoft researchers created DeBERTa (Decoding enhanced BERT with disentangled attention), a Transformer-based neural language model that makes two changes to BERT. It uses disentangled attention for self-attention, with each word represented by two vectors that encode content and position. The attention weights for these words are then computed using their contents and relative positions. DeBERTa also enhances the output layer of BERT for pretraining, by replacing the output softmax layer in BERT with an enhanced masked decoder (EMD) to predict the masked tokens during pretraining.
- Download DeBERTa
-
Microsoft researchers release XGLUE, a benchmark dataset for cross-lingual transfer learning in language models
To test language models’ ability to perform zero-shot cross-lingual transfer capability, Microsoft researchers announce the release of the XGLUE benchmark dataset. Using training data available only in English, the dataset comprises 11 downstream tasks covering 19 languages, including Italian, Portuguese, Swahili, and Urdu. The tasks included cover cross-lingual natural language understanding and generation, as well as tests unique to creating and evaluating search engine and news site scenarios.
-
2020May
Turing Natural Language Representation updates for Bing announced
Microsoft Bing shares how Turing language model capabilities are powering features in the search engine (opens in new tab). Features included synthesizing a simple “yes” or “no” response to applicable search queries, using a zero-shot approach to fine-tune only an English language model for translation into 100 different languages that had pretrained models, and improving query intent understanding.
-
DeepSpeed team announce ZeRO-2 and optimizations that set the fastest BERT training record at the time

Improvements to the DeepSpeed library allow Microsoft researchers to set the fastest BERT training record at the time: 44 minutes on 1,024 NVIDIA GPUs. To do this, they used new technology that used kernel optimizations to boost single GPU performance of models like BERT by more than 30%. These optimizations also allowed for better scaling of large models. In ZeRO-2, memory footprints were reduced in gradients, activation memory, and fragmented memory to improve the scale and speed of deep learning training with DeepSpeed by an order of magnitude.
-
2020Apr
Microsoft researchers introduce Oscar for vision and language pretraining

Oscar (Object-Semantics Aligned Pretraining) (opens in new tab) arose from the observation that objects can be used as anchor points to make learning semantic alignments between images and texts easier. By coupling images with language in a shared space, Oscar allows objects to act as anchor points in aligning the semantics between images and words. The vision and language pretraining (VLP) framework set state-of-the-art performance on six well-established vision-and-language tasks.
-
SMART: Using principled regularized optimization for pre-trained natural language model fine-tuning
In transfer learning, fine-tuning pretrained natural language processing (NLP) models can cause the model to overfit training data of downstream tasks and fail to generalize unseen data. The SMART framework uses smoothness-inducing regularization, in order to manage the complexity of the model, and Bregman proximal point optimization, which can prevent aggressive updating.
-
Adversarial training for large neural language models
This work shared a comprehensive study of adversarial training in all stages of training for large neural language models: pretraining from scratch, continual pretraining on a well-trained model, and fine-tuning for specific tasks. The researchers also created a general algorithm to maximize adversarial loss, called ALUM, which obtained substantial gains over BERT on many NLP tasks.
-
Effects of the adaptive learning rate on stochastic gradient-based optimization
Microsoft researchers and collaborators looked more closely at how warmup should be conducted in stochastic gradient-based optimization. More specifically, they zeroed in on the variance issue in adaptive learning rate and observe its root cause: limited amount of training samples used cause undesirably large variance in early stages of training. They also presented a new variant of Adam, called RAdam, to correct this problem of variance, and compares well with heuristic warmup.
-
2020Feb
Microsoft Project Turing team announces Turing-NLG language model, clocking in at 17 billion parameters
In February, the Turing Natural Language Generation (Turing-NLG) model made waves as the largest language model at the time. To train the Transformer-based generative model, researchers used a novel model parallelism technique, courtesy of the Zero Redundancy Optimizer (ZeRO), and tensor slicing to shard the model across four NVIDIA V100 GPUs on the NVIDIA Megatron-LM framework. Among its capabilities, the team highlighted direct question answering, zero-shot question answering, and abstractive summarization with less supervision.
-
Microsoft DeepSpeed team releases open-source library, including ZeRO, a novel zero redundancy optimizer
In conjunction with Turing-NLG, Microsoft researchers released the open-source DeepSpeed library, which improved large model training in four key areas: scale, speed, cost, and usability. Initially, the library included ZeRO-1, which decreased the resources needed for model and data parallelism while greatly increasing the number of parameters able to be trained, up to 100 billion.
DeepSpeed, along with other distributed training tools are being incorporated into the ONNX (Open Neural Network Exchange) runtime (opens in new tab), an open-source high performance tool for machine learning models.
- Project DeepSpeed
- Download ONNX Runtime
-
UniLMv2: Pseudo-Masked Language Models for Unified Language Model Pre-Training
This paper introduced a new method for pretraining unified language models using a pseudo-masked language model (PSLM). This method can be used for both autoencoding and partially autoregressive language modeling tasks, and the results with UniLMv2, a model trained using PSLM, achieved state of the art on a number of natural language understanding and generation tasks across widely used benchmarks.