
Fast Autoregressive Video Generation with Diagonal Decoding
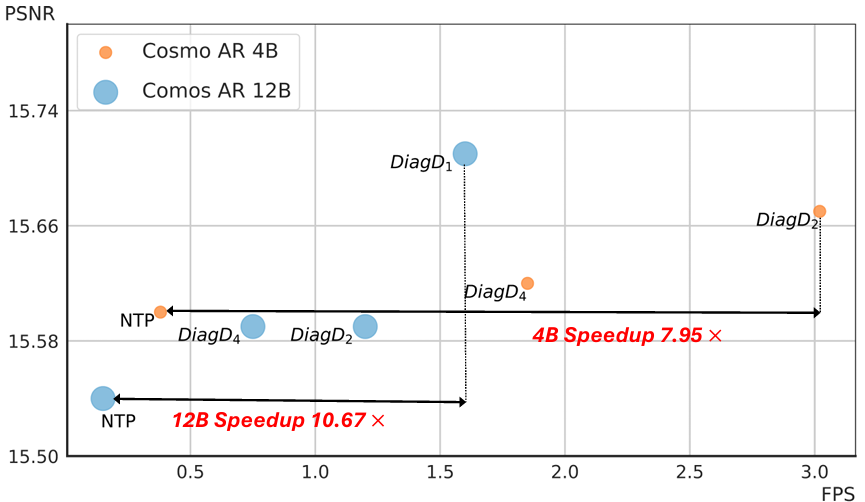
Autoregressive Transformer models have demonstrated impressive performance in video generation, but their sequential token-by-token decoding process poses a major bottleneck, particularly for long videos represented by tens of thousands of tokens. Here, we propose Diagonal Decoding (DiagD), a training-free inference acceleration algorithm for autoregressively pre-trained models that exploits spatial and temporal correlations in videos. Our method generates tokens along diagonal paths in the spatial-temporal token grid, enabling parallel decoding within each frame as well as partially overlapping across consecutive frames. The proposed algorithm is versatile and adaptive to various generative models and tasks, while providing flexible control over the trade-off between inference speed and visual quality. Experiments on multiple autoregressive video generation models and datasets demonstrate that DiagD achieves up to 10x speedup compared to naive sequential decoding, while maintaining comparable visual fidelity.
Method

The motivation of our method arises from intuitive observations on consecutive frames in a video, which can be summarized in two key insights. As shown above, the first insight is that patches exhibit stronger correlations with their spatial neighbors than with sequential ones. Secondly, due to the temporal redundancy of videos, patches from consecutive frames that occupy similar relative positions are highly likely to be similar to each other.
As a result, we propose Diagonal Decoding, an iterative algorithm that generates tokens along diagonal paths in the spatial-temporal token grid. Spatially, within each frame, tokens along the same diagonal are generated in parallel, leveraging the strong local dependencies between neighboring patches. And temporally, by stacking frames together, our method generates the top-left tokens of the next frame before completing the current frame, as these tokens are less likely to depend on the bottom-right tokens that have not yet been generated.
Case: Cosmos 12B Autoregressive Model
Next Token Prediction
DiagD (k=1)
DiagD (k=2)









Case: WHAM 1.6B Model
Next Token Prediction
DiagD (k=1)
DiagD (k=2)






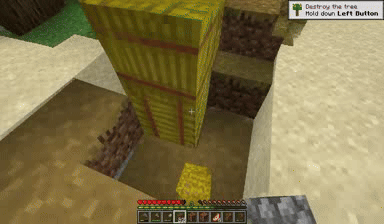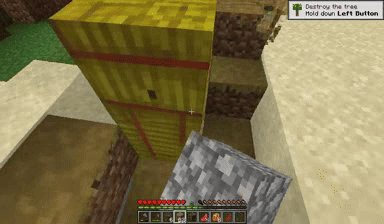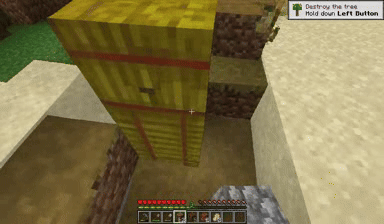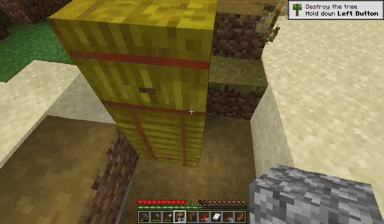
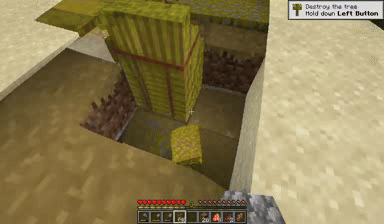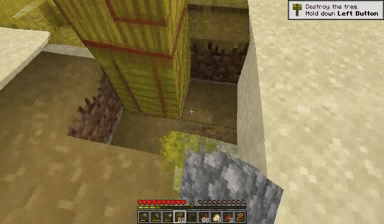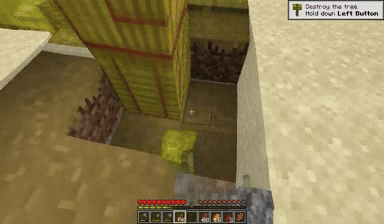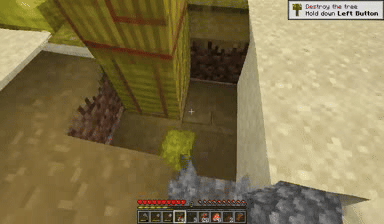
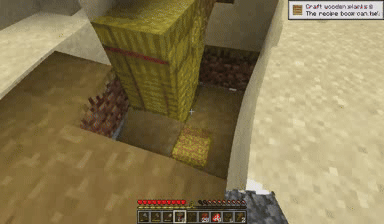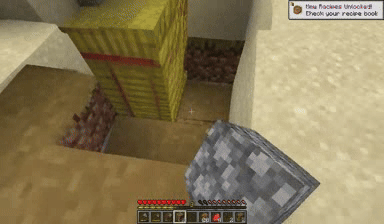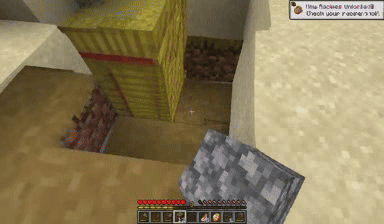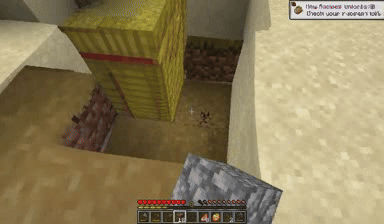
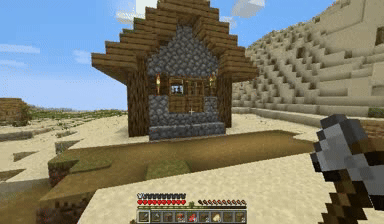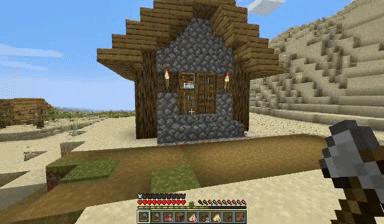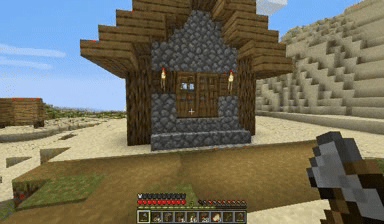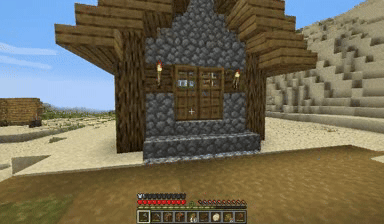
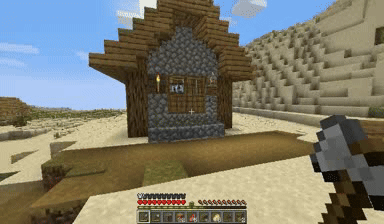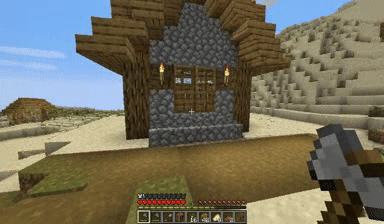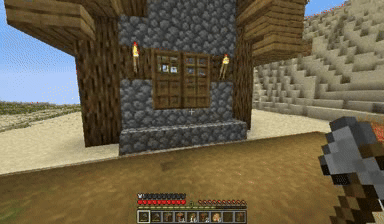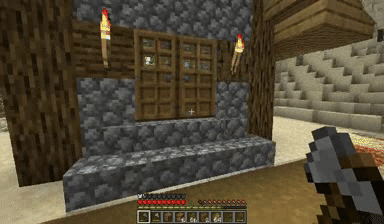
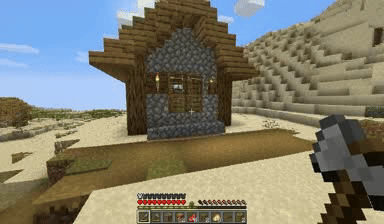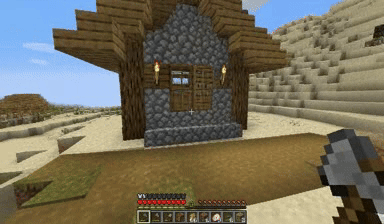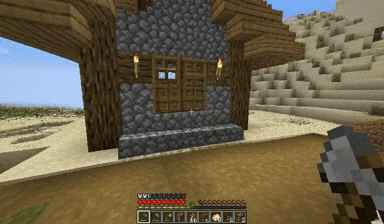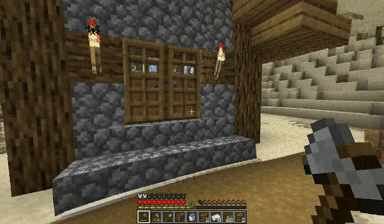
Case: Autoregressive Model on Minecraft
Next Token Prediction
DiagD w/o Finetune
DiagD w/ Finetune
BibTex
@article{ye2025fast,
title={Fast Autoregressive Video Generation with Diagonal Decoding},
author={Ye, Yang and Guo, Junliang and Wu, Haoyu and He, Tianyu and Pearce, Tim and Rashid, Tabish and Hofmann, Katja and Bian, Jiang},
journal={arXiv preprint arXiv:2503.14070},
year={2025},
}