

ASL Citizen
A Community-sourced Dataset for Advancing Isolated Sign Language Recognition
ASL Citizen is the first crowdsourced isolated sign language video dataset. The dataset contains about 84k video recordings of 2.7k isolated signs from American Sign Language (ASL), and is about four times larger than prior single-sign datasets. Our videos were recorded by 52 Deaf or hard of hearing signers through our novel sign language crowdsourcing platform, first proposed in our prior work (opens in new tab) exploring crowdsourcing for sign language video collection, and enhanced for scalability. Because the data is crowdsourced, it contains examples of everyday signers in everyday environments, providing more representative data for data-driven machine learning models intended to generalize in real-world settings, such as Isolated Sign Language Recognition (ISLR) models deployed for applications like sign language dictionary retrieval.
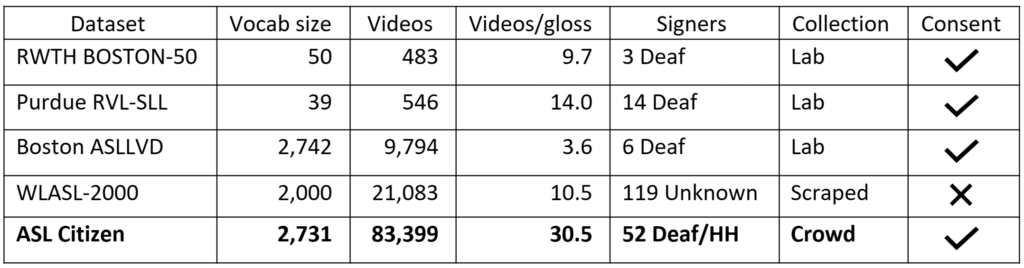
On the platform, signers contributed videos for two simultaneous purposes: 1) to help build a community-sourced dictionary, and 2) to contribute to a dataset for research purposes. This dual-purpose design enables the creation of a direct community resource, while also enabling longer-term research. On the website, participants were prompted by a series of videos of isolated signs (as demonstrated by a highly proficient ASL model, who we refer to as the “seed signer”), and recorded their own version of each. This setup allowed us to capture a range of backgrounds and lighting conditions, similar to those present in everyday dictionary lookup queries. Our task design also enabled us to automatically label each video with the prompt sign, largely eliminating post-hoc labelling challenges that have limited large sign language data collections in the past. Finally, this setup enabled participants to engage in a full consent process, unlike past scraped sign language video collections. Table 1 below provides a comparison to past datasets.
The sign vocabulary we use is taken from ASL-LEX (opens in new tab), which also provides detailed linguistic analysis of each sign. The signs in our corpus map onto the signs in their linguistic corpus, using the unique identifier token (referred to as the sign “Code” in ASL-LEX resources).
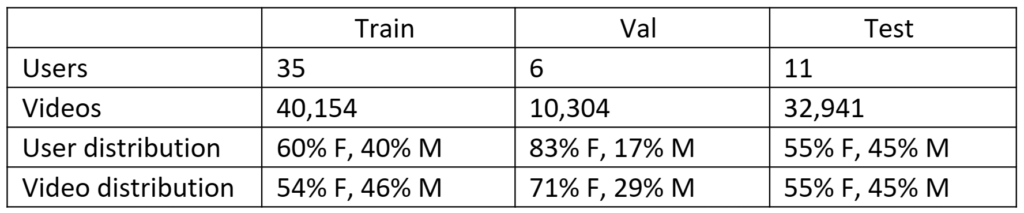
We release our dataset along with training, validation, and test splits (shown in Table 2 below). Each dataset participant has been assigned to one split. By creating signer-independent splits, we provide a setup for methods development that more aligns with real-world recognition applications, where users querying a model are unlikely to be previously seen in training data. The distribution of signers across splits was chosen to balance female-male gender ratio. We also provide generalized user demographics and gloss metadata to support further analysis. Please note that the seed signer is included in the dataset as P52.
The video counts displayed in publications and on this page may differ slightly. This is due to small dataset updates that occurred during preparation and analysis (e.g. to remove a small number of videos that displayed an error message during webcam recording). All collection and release procedures were reviewed and approved by our ethics review board and IRB.
| Version | # Videos | # Signs | # Signers | Date, Publication(s) |
| Version 0.9 | 83,912 | 2,731 | 52 | April 2023, arXiv initial publication |
| Version 1.0 | 83,399 | 2,731 | 52 | June 2023 |
For additional details on the dataset, please see the datasheet in the supporting tab, and check out our publications.