

Generative Neural Visual Artist (GeNeVA)
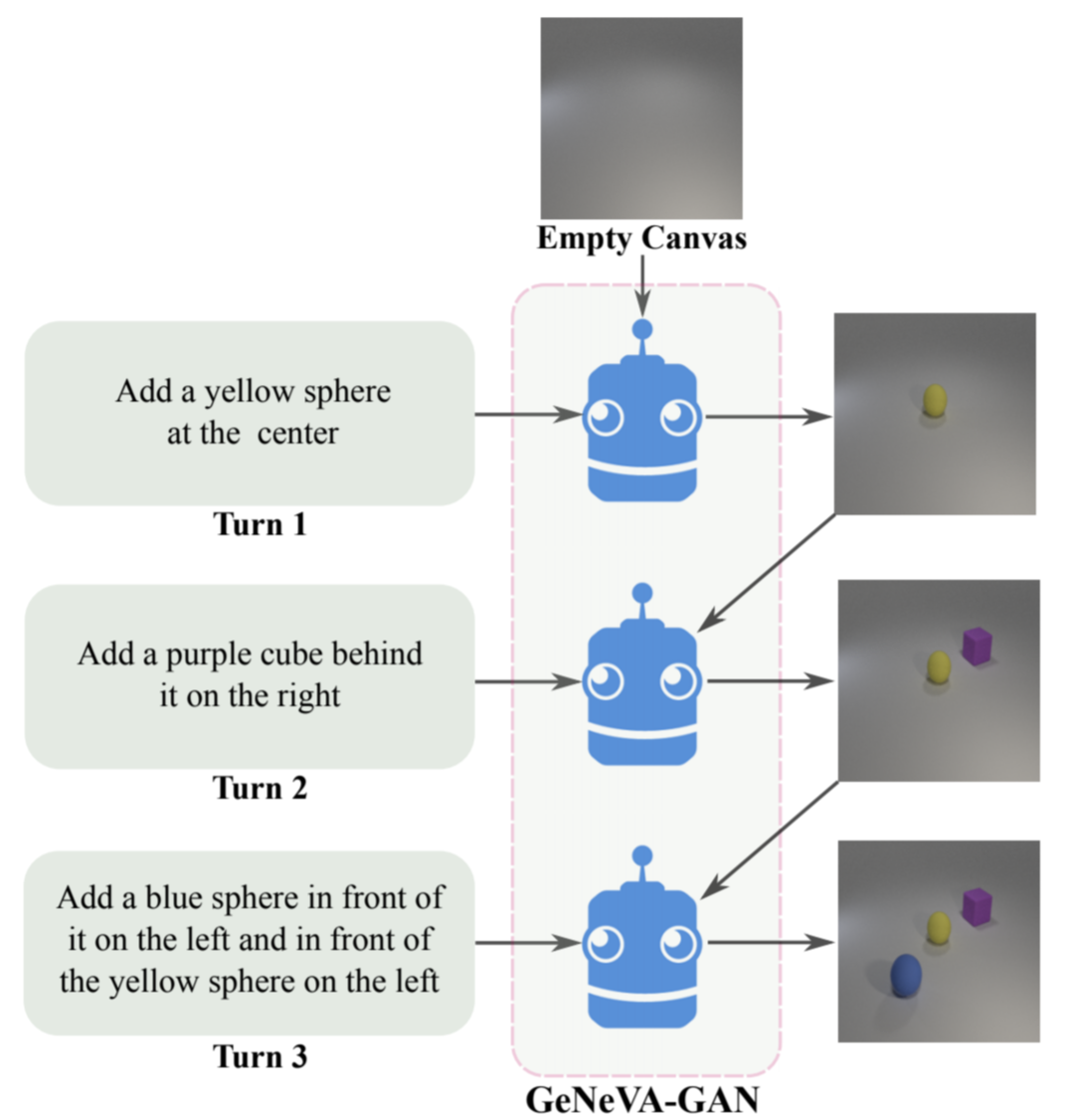
The Generative Neural Visual Artist (GeNeVA) task
The GeNeVA task involves a Teller giving a sequence of linguistic instructions to a Drawer for the ultimate goal of image generation.
The Teller is able to gauge progress through visual feedback of the generated image. This is a challenging task because the Drawer needs to learn how to map complex linguistic instructions to realistic objects on a canvas, maintaining not only object properties but relationships between objects (e.g., relative location). The Drawer also needs to modify the existing drawing in a manner consistent with previous images and instructions, so it needs to remember previous instructions. All of these involve understanding a complex relationship between objects in the scene and how those relationships are expressed in the image in a way that is consistent with all instructions given.
An example instruction sequence for the GeNeVA task is shown in the figure on the right.
We introduce the GeNeVA task and a model (GeNeVA-GAN) for performing this task in our paper Tell, Draw, and Repeat: Generating and modifying images based on continual linguistic instruction.
Read the paperGeNeVA – Examples
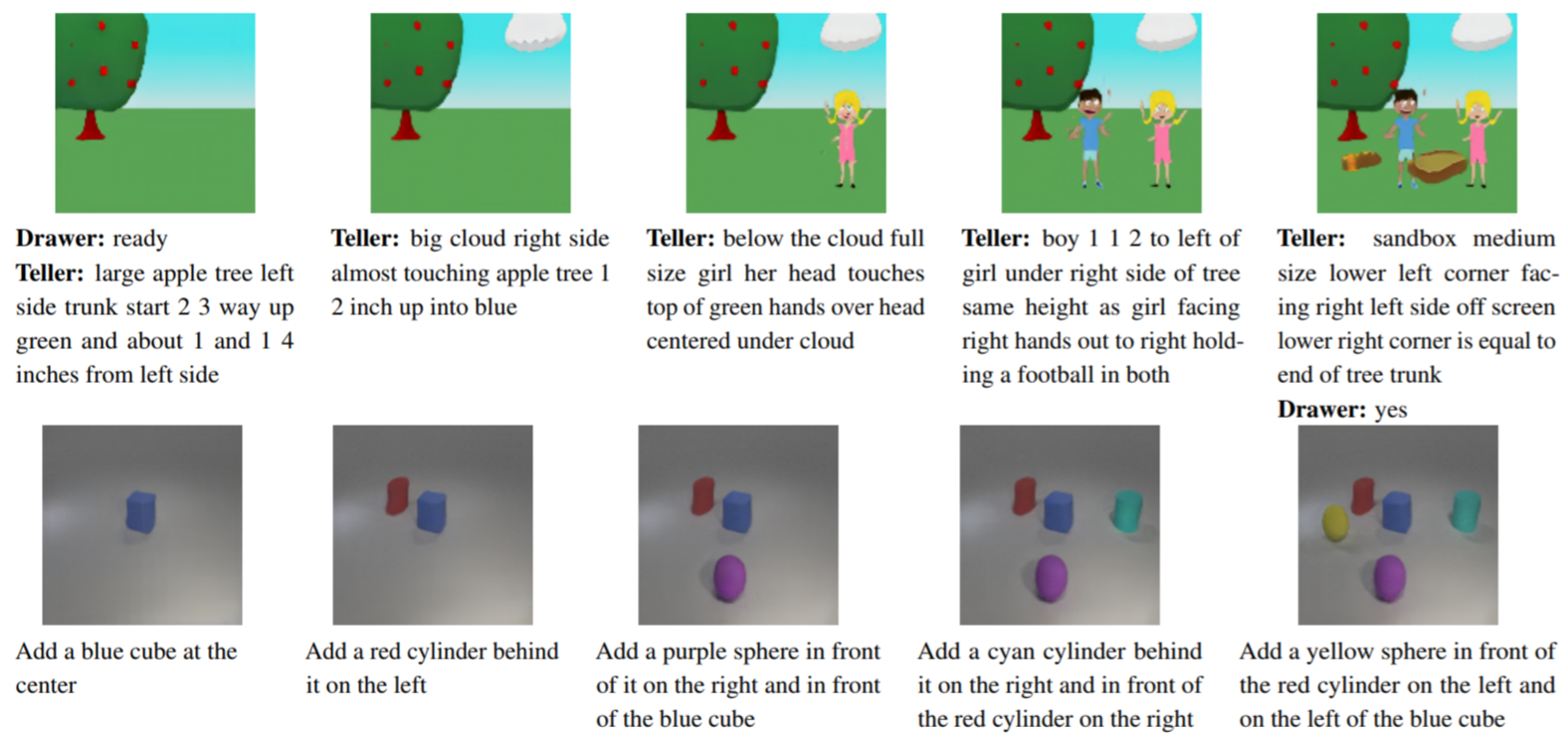
Images generated by the GeNeVA-GAN model described in Tell, Draw, and Repeat: Generating and modifying images based on continual linguistic instruction on CoDraw (top row) and i-CLEVR (bottom row) datasets are shown with the provided instructions below:
GeNeVA – Datasets
For re-creating the CoDraw and i-CLEVR datasets used for the GeNeVA task, you will have to download the data files and then run the dataset generation code as shown in the following links:
Download the GeNeVA Data Files GeNeVA Datasets - Generation Code
GeNeVA – Pre-trained Models
The pre-trained models for the object detector and localizer model that we used for evaluating the metrics can be downloaded from the following links:
CoDraw Object Detector and Localizer i-CLEVR Object Detector and Localizer
GeNeVA – Training and Evaluation Code
Code to train and evaluate the GeNeVA-GAN model for the GeNeVA task can be obtained from the following link:
GeNeVA - Training and Evaluation CodeReference
If you use the GeNeVA task, code, or datasets as part of any published research, please cite the following paper:
Alaaeldin El-Nouby, Shikhar Sharma, Hannes Schulz, Devon Hjelm, Layla El Asri, Samira Ebrahimi Kahou, Yoshua Bengio, and Graham W. Taylor. “Tell, Draw, and Repeat: Generating and modifying images based on continual linguistic instruction”. Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2019.
@InProceedings{El-Nouby_2019_ICCV,
author = {El{-}Nouby, Alaaeldin and
Sharma, Shikhar and
Schulz, Hannes and
Hjelm, Devon and
El Asri, Layla and
Ebrahimi Kahou, Samira and
Bengio, Yoshua and
Taylor, Graham W.},
title = {Tell, Draw, and Repeat: Generating and modifying images based on continual linguistic instruction},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {Oct},
year = {2019}
}