

Interactive Learning-from-Observation
Service-robot solutions to empower senior citizens to achieve more and to enhance their lives
About the project
The goal of this project is to develop an interactive learning-from-observation (LfO) system in the service-robot domain so as to empower senior citizens to achieve more and enhance their lives. Currently, many seniors in assisted living facilities would have preferred to remain at their homes. If we can use service robots to assist them, they can stay at home, conduct activities alone and, more importantly, enjoy their lives and achieve more. In order to achieve this goal without increasing too much manpower, we need customized service robots in each home environment. If caregivers or occasionally visiting family members could teach those robots from their demonstrations, we can customize robots’ operations to each home environment. Those robots can work as caregivers’ assistants and relieve caregivers’ workload considerably. Toward this goal, we have been developing an interactive LfO in the service-robot domain, which enables a robot to learn what-to-do and how-to-do from observing human demonstrations at home.
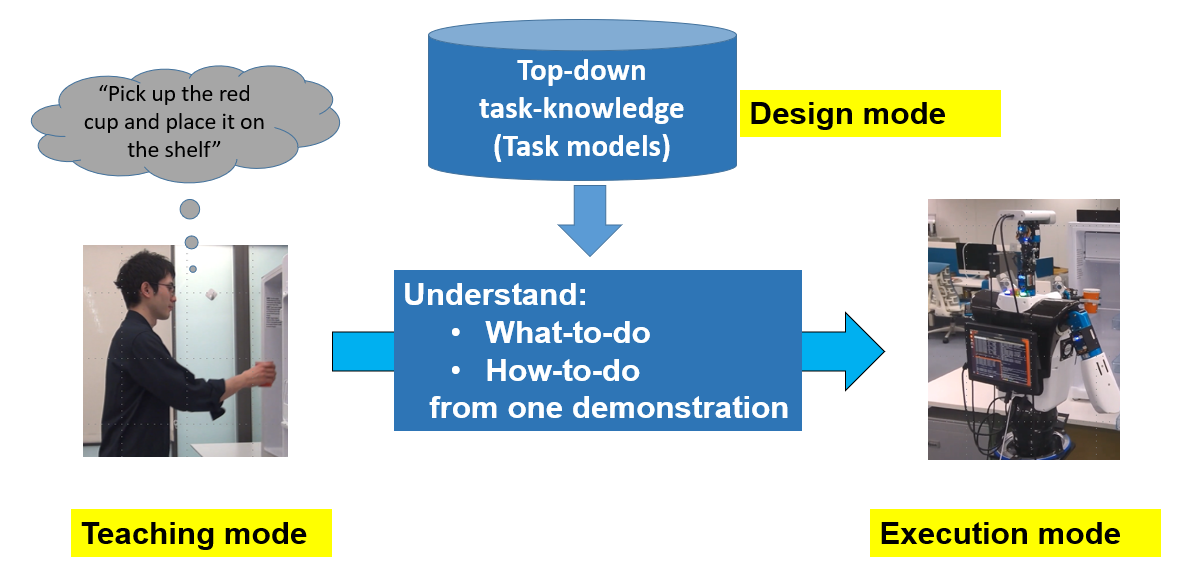
Top-down LfO
There are two approaches in LfO: top-down to utilize some general framework to learn and bottom-up to learn everything from scratch. We have proposed and been developing the top-down approach, of which origin comes from Ikeuchi & Suehiro IEEE TRO 1994. Our approach is based on Minsky’s frame theory (Minsky MIT 1974) that humans recognize the outer world only through some pre-defined frames. Thus, our top-down approach is divided into three modes: design, teaching, and execution. The design mode prepares a domain-specific task-model library, a collection of frames of possible tasks necessary-and-sufficiently covering each domain such as machine assembly and rope-typing. The teaching mode observes human demonstrations and identifies which task, what-to-do, reasonably describes the current human performance demonstrated. Then, it fills skill slots of the corresponding task model, where-to-do, to completely describe the performance. Examples of these skill slots are human postures and grasping strategies. In the mapping mode, task models are converted into a sequence of skill agents, which knows how-to-do such actions while taking into account the constraints of each robot hardware.
Our technologies
Multi-modal learning. For a better understanding of human demonstration, we introduce multi-modal (verbal and visual) learning. Verbal instructions provide the overall task flow as well as where the system should pay attention (i.e., focus-of-attention), while visual information provides the how-to-do such as human postures and grasping strategies. The system can also request the demonstrator to repeat some unclear points.
Common-sense awareness. Human demonstration contains a variety of implicit skills. e.g., grasp type and body postures for efficient task operation. These skills are not taught explicitly because they are common sense to many demonstrators. We have identified a set of skill slots that are implicit but critical to task execution and defined them as top-down knowledge. These slots are recognized from the demonstration, allowing for robust LfO.
A task-model compiler combined with and a bottom-up self-skill-refinement pipeline. For a robust robot execution, we integrate a task-model compiler and a bottom-up self-skill-refinement pipeline using reinforcement learning. The task-model compiler converts task models into robot commands considering its hardware specifications. Then, these initial commands are refined through reinforcement learning to achieve a precise execution of all tasks without robot-dependent hard coding.