

LLM2CLIP
Enabling existing pretrained models to become stronger with minimal fine-tuning
CLIP is one of the most important multimodal foundational models today, aligning visual and textual signals into a shared feature space using a simple contrastive learning loss on large-scale image-text pairs. What powers CLIP’s capabilities? The rich supervision signals provided by natural language — the carrier of human knowledge — shape a powerful cross-modal representation space. As a result, CLIP supports a variety of tasks, including zero-shot classification, detection, segmentation, and cross-modal retrieval, significantly influencing the entire multimodal domain.
However, with the rapid advancements in large language models (LLMs) like GPT-4 and LLaMA, the boundaries of language comprehension and generation are continually being pushed. This raises an intriguing question: can the capabilities of LLMs be harnessed to further improve multimodal representation learning?
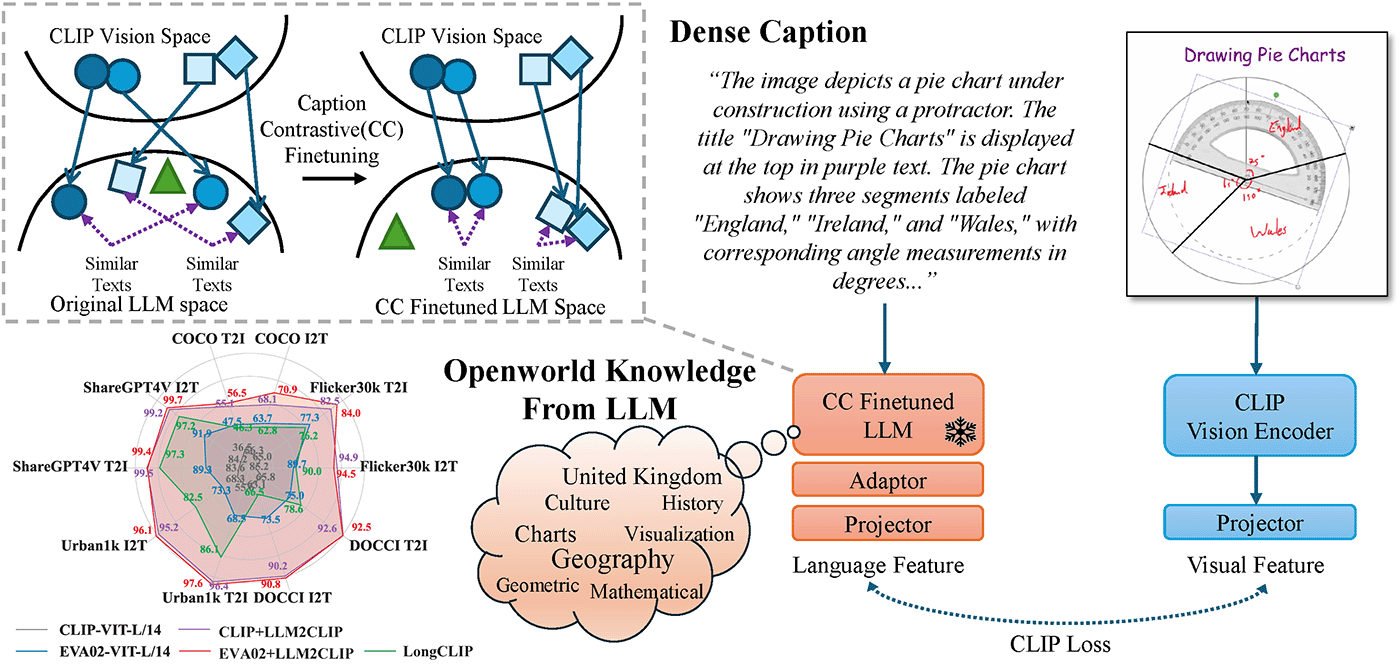
The potential benefits of incorporating LLMs into CLIP are clear. LLMs’ strong textual understanding can fundamentally improve CLIP’s ability to handle image captions, drastically enhancing its ability to process long and complex texts — a well-known limitation of vanilla CLIP. Moreover, LLMs are trained on a vast corpus of text, possessing open-world knowledge. This allows them to expand on caption information during training, increasing the efficiency of the learning process.
However, realizing this potential is challenging. Despite LLMs’ powerful internal comprehension, their autoregressive nature hides this capability within the model, leading to output features with poor discriminability. Our experiments show that directly integrating LLMs into CLIP results in catastrophic performance drops.
We propose LLM2CLIP, a novel approach that embraces the power of LLMs to unlock CLIP’s potential. By fine-tuning the LLM in the caption space with contrastive learning, we extract its textual capabilities into the output embeddings, significantly improving the output layer’s textual discriminabil. We then design an efficient training process where the fine-tuned LLM acts as a powerful teacher for CLIP’s visual encoder. Thanks to the LLM’s presence, we can now incorporate longer and more complex captions without being restricted by vanilla CLIP text encoder’s context window and ability limitations. Our experiments demonstrate that this approach brings substantial improvements in cross-modal tasks. Our method directly boosted the performance of the previously SOTA EVA02 model by 16.5% on both long-text and short-text retrieval tasks, transforming a CLIP model trained solely on English data into a state-of-the-art cross-lingual model. Moreover, when integrated into multimodal training with models like Llava 1.5, it consistently outperformed CLIP across nearly all benchmarks, demonstrating comprehensive performance improvements.