

LLMLingua
Effectively Deliver Information to LLMs via Prompt Compression
Paper: https://arxiv.org/abs/2310.05736 (opens in new tab)
Demo: https://huggingface.co/spaces/microsoft/LLMLingua (opens in new tab)
Project Page: https://llmlingua.com/llmlingua.html (opens in new tab)
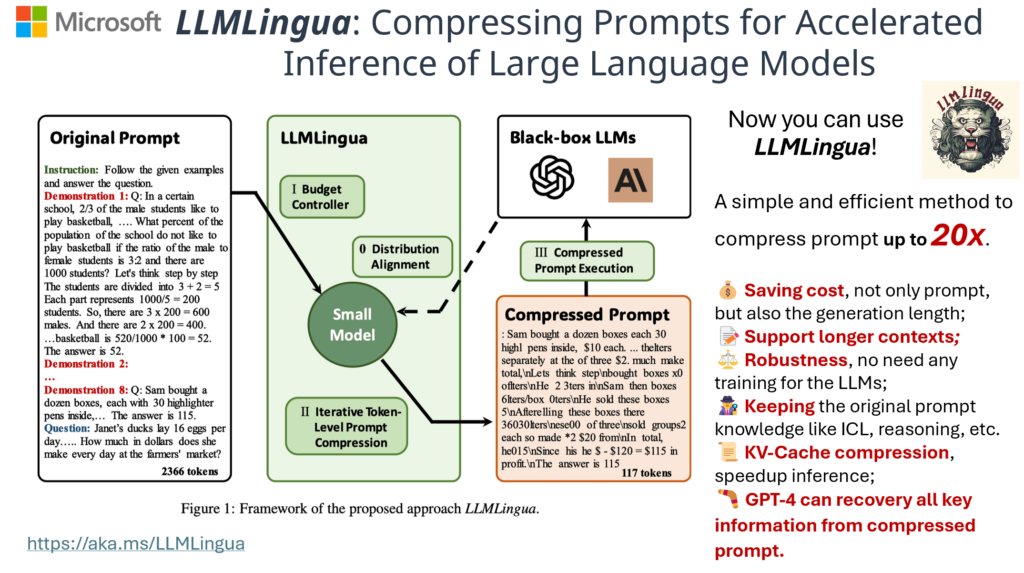
To accelerate model inference and reduce cost, we introduce LLMLingua, which employs a well-trained small language model after alignment, such as GPT2-small or LLaMA-7B, detects unimportant tokens in the prompt and enables inference with the compressed prompt in black-box LLMs, achieving up to 20x compression with minimal performance loss. It’s worth noting that token-level compressed prompts are a format that is difficult for humans to understand but can be well interpreted by LLMs.
To evaluate the effectiveness of compressed prompts, especially the unique capabilities of LLMs, we conducted experiments in four different scenarios, i.e., GSM8K, BBH, ShareGPT, and Arxiv-March23, which cover ICL, Reasoning, Summarization, and Conversation. The results show that our approach can effectively retain the original prompt’s capabilities, particularly in ICL and reasoning.
Furthermore, we demonstrated the efficiency and practical acceleration of LLMLingua through latency tests and computational workload estimation.
Insights
- Natural language is redundant, amount of information varies.
- LLMs can understand compressed prompt.
- There is a trade-off between language completeness and compression ratio. (LLMLingua)
- GPT-4 can recover all the key information from a compressed prompt-emergent ability. (LLMLingua)
For more details, please refer to the paper LLMLingua (opens in new tab).
Why LLMLingua?
Building on the intuition mentioned earlier, LLMLingua leverages small models’ perplexity to measure the redundancy within a prompt. It has designed three modules, as illustrated above, to assign varying compression rates to different segments within the prompt. This approach takes into account the conditional probabilities between compressed tokens and other tokens to better establish a sensitive distribution. Moreover, to make small models more attuned to various black-box models, LLMLingua introduces an alignment mechanism that aligns small models more closely with the semantic distributions of LLMs.
LLMLingua offers the following advantages:
- It can be directly used for black-box LLMs and helps save computation and financial costs, up to 20x.
- It is a highly robust method that requires no training of the LLMs and is applicable to different LLMs, such as GPT-4, GPT-3.5-Turbo, Claude, Mistral, etc.
- After compression, it allows the model to support longer context inputs.
- LLMLingua effectively retains the capabilities of LLMs, including reasoning, in-context learning, etc.
- LLMLingua effectively retains the capabilities of LLMs, including reasoning, in-context learning, etc.
- Prompts compressed by LLMLingua can be effectively decompressed by GPT-4, retaining vital information.
BibTeX
@inproceedings{jiang-etal-2023-llmlingua,
title = "{LLML}ingua: Compressing Prompts for Accelerated Inference of Large Language Models",
author = "Huiqiang Jiang and Qianhui Wu and Chin-Yew Lin and Yuqing Yang and Lili Qiu",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.emnlp-main.825",
doi = "10.18653/v1/2023.emnlp-main.825",
pages = "13358--13376",
}