

MInference
Million-Tokens Prompt Inference for Long-context LLMs
Q: How to effectively evaluate the impact of dynamic sparse attention on the capabilities of long-context LLMs?
To evaluate long-context LLM capabilities using models like LLaMA-3-8B-Instruct-1M and GLM-4-9B-1M, we tested: 1) context window with RULER, 2) general tasks with InfiniteBench, 3) retrieval tasks with Needle in a Haystack, and 4) language model prediction with PG-19.
We found traditional methods perform poorly in retrieval tasks, with difficulty levels as follows: KV retrieval > Needle in a Haystack > Retrieval.Number > Retrieval PassKey. The main challenge is the semantic difference between needles and the haystack. Traditional methods excel when this difference is larger, as in passkey tasks. KV retrieval requires higher retrieval capabilities since any key can be a target, and multi-needle tasks are even more complex.
We will continue to update our results with more models and datasets in future versions.
Q: Does this dynamic sparse attention pattern only exist in long-context LLMs that are not fully trained?
Firstly, attention is dynamically sparse, a characteristic inherent to the mechanism. We selected state-of-the-art long-context LLMs, GLM-4-9B-1M and LLaMA-3-8B-Instruct-1M, with effective context windows of 64K and 16K. With MInference, these can be extended to 64K and 32K, respectively. We will continue to adapt our method to other advanced long-context LLMs and update our results, as well as explore the theoretical basis for this dynamic sparse attention pattern.
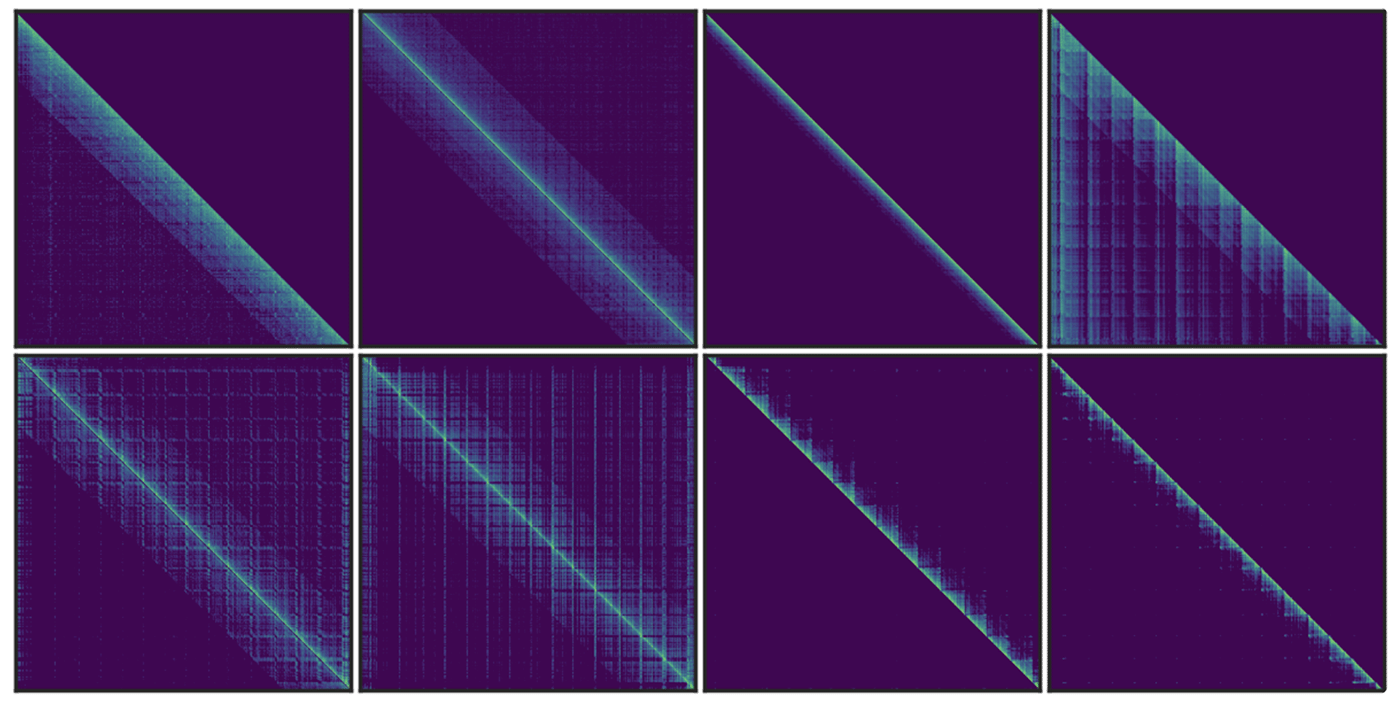
Q: Does this dynamic sparse attention pattern only exist in Auto-regressive LMs or RoPE based LLMs?
Similar vertical and slash line sparse patterns have been discovered in BERT[1] and multi-modal LLMs[2]. Our analysis of T5’s attention patterns, shown in the figure, reveals these patterns persist across different heads, even in bidirectional attention.
[1] SparseBERT: Rethinking the Importance Analysis in Self-Attention, ICML 2021.
[2] LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference, 2024.
Q: What is the relationship between MInference, SSM, Linear Attention, and Sparse Attention?
All four approaches (MInference, SSM, Linear Attention, and Sparse Attention) efficiently optimize attention complexity in Transformers, each introducing inductive bias differently. The latter three require training from scratch. Recent works like Mamba-2 and Unified Implicit Attention Representation unify SSM and Linear Attention as static sparse attention, with Mamba-2 itself being a block-wise sparse method. While these approaches show potential due to sparse redundancy in attention, static sparse attention may struggle with dynamic semantic associations in complex tasks. In contrast, dynamic sparse attention is better suited for managing these relationships.