
Your Pad or MiPad
It only took one scientist mumbling at a monitor to give birth to the idea that a computer should be able to listen, understand, and even talk back. But years of effort haven’t gotten us closer to the Jetson dream: a computer that listens better than your spouse, better than your boss, and even better than your dog Spot.
Using state-of-the-art speech recognition, and strengthening this new science with pen input, Microsoft’s speech technology experts have been able to develop a clever way to communicate with a machine.
Their code name for the project is MiPad, pronounced “my pad,” and short for “multimodal interactive notepad.” Mipad’s speech input addresses the defects of the handheld, such as the struggle to wrap your hands around a small pen and hit the tiny target known as an on-screen keyboard. Some of the current limitations of speech recognition: background noise, multiple users, accents, and idioms, can be helped with pen input. The advantage of speech is the weakness of the pen and vice versa. MiPad is a marriage of these two input forms. The research group started work on MiPad in 1998 and had a first public demonstration by 2000
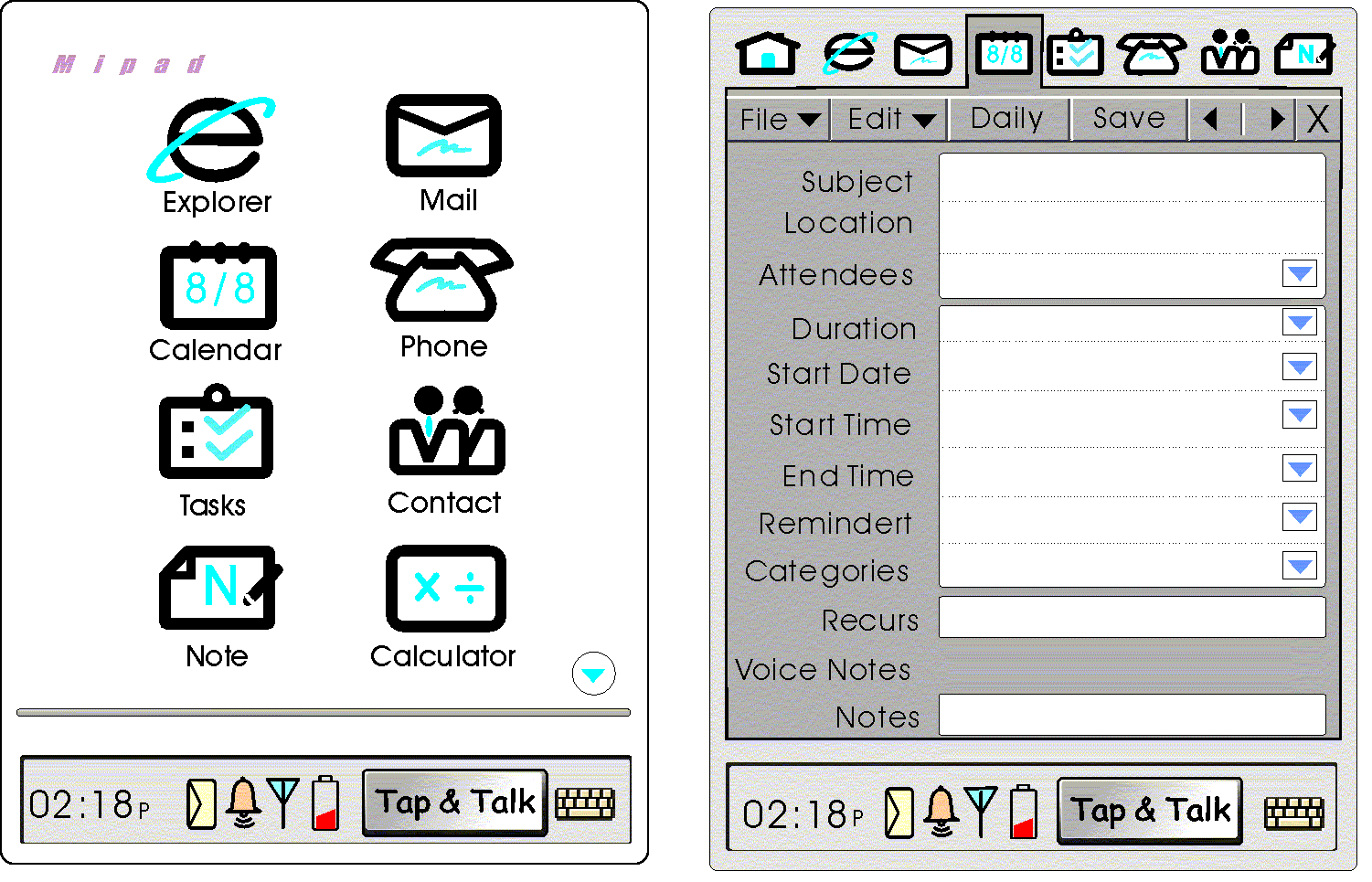
MiPad cleverly sidesteps some of the problems of speech technology by letting the user touch the pen to a field on the screen, directing the speech recognition engine to expect certain types of input. The Speech group calls this technology “Tap and Talk.” If you’re sending an e-mail, and you tap the “To” field with the pen before you speak, the system knows to expect a name. It won’t try to translate “Helena Bayer” into “Hello there.” The semantic information related to this field is limited, leading to a reduced error rate.
On the other hand, if you’re filling in the subject field and using free-text dictation, the engine behind MiPad knows to expect anything. This is where the “Tap and Talk” technology comes in handy again. If the speech recognition engine has translated your spoken “I saw a bear,” into the text “I saw a hair,” you can use the stylus to tap on the word “hair” and repeat “bear,” to correct the input. This focused correction, an evolution of the mouse pointer, is easy and painless compared to having to re-type or repeat the complete sentence.
The “Tap and Talk” interface is always available on your MiPad device. The user can give spontaneous commands by tapping the Command button and talking to the handheld. You might tell your MiPad device, “I want to make an appointment,” and the MiPad will obediently bring up an appointment form for you to fill in with speech, pen, or both.
Computers are getting better at continuous speech recognition: hearing human speech and turning it into words on a screen, says researcher Hsiao-Wuen Hon. Hon specializes in acoustic modeling—teaching the machine to recognize speech as wave form patterns and matching them to patterns it already knows. The system can consider multiple interpretations of a user’s spoken command, says Milind Mahajan, who improved the speech recognizer’s capacity to interpret words and phrases using a pattern recognition system.
Kuansan Wang, Ye-Yi Wang and their colleagues use those patterns to help the machine decipher what the user’s intent is from the context, and to translate those commands into actions. Recognizing what someone is saying is only one part of the equation, understanding what they want is a second, and perhaps more important part. Imagine asking your computer to call Barb later, and ask her for a date, because you’re free tonight. The computer sends Barb an e-mail with “Hey Later” in the ‘To’ field, and in the subject field prints “I would like a date, it will be no charge tonight.” This misunderstanding is less than useless, you don’t have a date, and Barb now thinks you’re a kook with a big ego.
Kuansan Wang says, “One of my jobs is trying to normalize a sentence in a way so the same query can be asked in all sorts of ways. I have to understand all of them.” For instance, let’s say two different people are both looking for the same thing from an online restaurant guide. This is how Character A might ask her question: “I want fancy food, not too expensive though, and in Redmond.” Character B says, “I want gourmet food, cheap, and in Redmond.” The computer would have to parse the request and understand that “not too expensive” and “cheap” were the same thing, that “gourmet” and “fancy” were also the same thing, and that the only clear information given was the location.
Wang would also like the device to be able to tell if the customer was using a cell phone, a handheld, or a PC, and offer information that conveniently fit the medium. In the scenario above, a cell phone user might be able to press “1” on the keypad when the computer read the appropriate name in the list. A PC user would get the complete list on screen, and could click on the name for more information or a link to the restaurant’s Web site. A handheld user might get four or five names at a time, with a “next” button to press to view other choices.
The MiPad prototype demonstrated in 2000 uses a Compaq handheld device as a client. Researchers at Microsoft Research have “eaten their own dogfood,” and this technology is now being productized by the Speech Products Group.
Though the scientists in the Speech group hope to someday add the ability to interact with any other device, the first version only implemented e-mail, calendar, and contact list functions. In addition, the MiPad continuous speech recognition and spoken language functions were performed on a Windows 2000 server through a wireless LAN connection, but will eventually use a cellular modem. The client was based on Microsoft Windows CE and contains signal processing and user interface logic modules. With the advent of more powerful procesors, speech recognition could take place in the device itself.
Though the speech experts at Microsoft Research continue to work on improving speech recognition and spoken language understanding, the MiPad application allows them to bring speech-enabled mobile computing to the market while they continue to improve noise cancellation, variable speaker input, and find all the different ways people say the same thing. That last challenge might be the toughest yet, since most humans haven’t quite solved that one either.
People
Hsiao-Wuen Hon
Emeritus Researcher