


Machine learning models are increasingly running on edge hardware, such as mobile phones or Internet of Things (IoT) devices. Motivations include protection of private data and avoidance of networking latency, for example with applications that recognize speech. Ensuring efficient inference is especially important on battery-powered devices with constrained processor, memory and power budgets. Several approaches have proven fruitful.
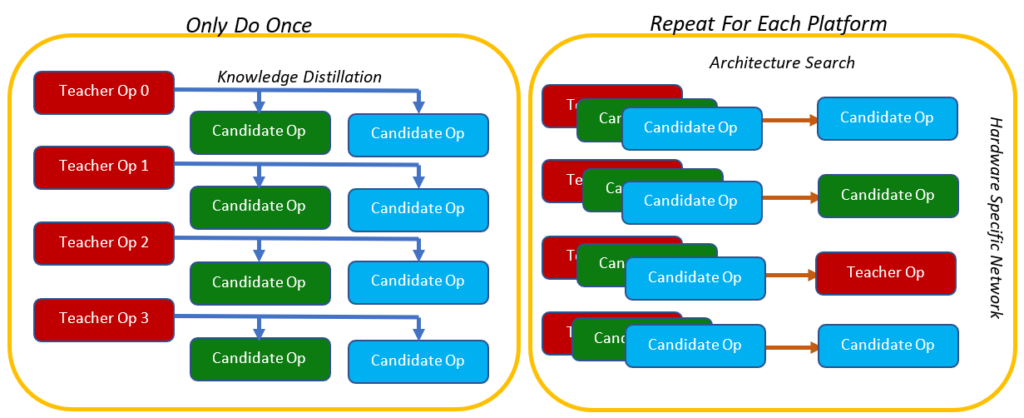
In collaboration with NVIDIA, we’ve developed efficient Neural Architecture Search (NAS) to find network architectures that will run efficiently on hardware with specific constraints, such as low power consumption for mobile devices. Hardware-Aware Network Transformation (HANT) employs a two-level strategy to achieve this goal. First, knowledge distillation is used to train a library of efficient operators, once. HANT can then search this library quickly and repeatedly to generate energy-efficient, hardware-specific architectures. This highly efficient method can find high-performing architectures in minutes, enabling carbon savings compared to previous methods.
AsyMo takes a different approach that focuses on deep learning inference latency and energy efficiency on the asymmetric processors found in mobile phones. Mobile CPUs have multiple cores with different characteristics, such as a larger core intended for high performance, and a smaller core for when energy conservation is more important than performance. AsyMo incorporates knowledge of the processor asymmetry and model architecture into the partitioning of neural network inferencing tasks to reduce inference latency. AsyMo also identifies that high CPU clock speeds do not benefit (and can actually harm) models that are memory-bandwidth limited. Leveraging this insight, AsyMo intelligently sets the CPU clock speed based on the hardware and model architecture, to improve energy efficiency. Depending on the deep learning framework and model evaluated, AsyMo achieved improvements of 46% or more for inference latency, and up to 37% for energy efficiency.