

VALL-E Family
Neural codec language models for speech synthesis
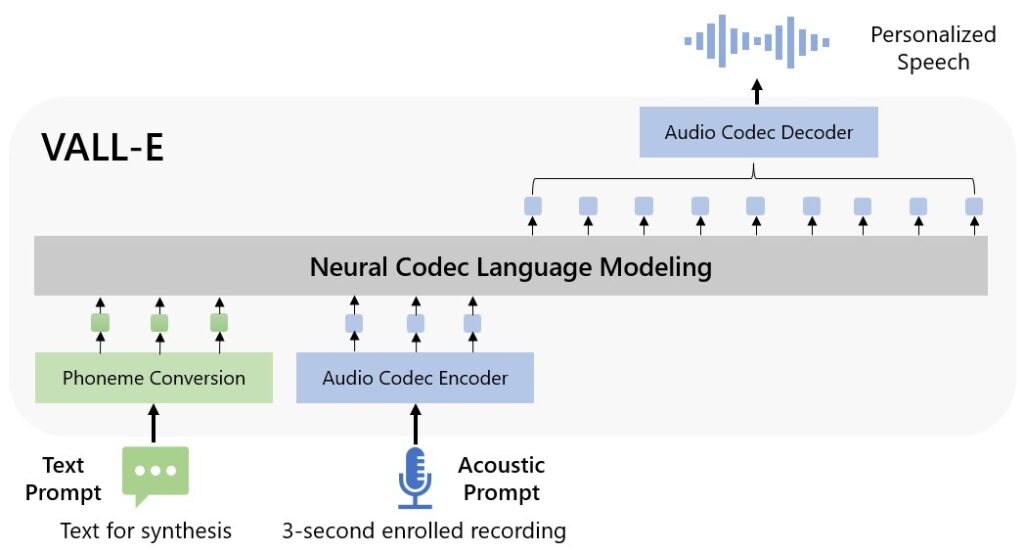
VALL-E is a language modeling approach for text-to-speech synthesis (TTS). Specifically, we train a neural codec language model (called VALL-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. VALL-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that VALL-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find VALL-E could preserve the speaker’s emotion and acoustic environment of the acoustic prompt in synthesis.
This page is for research demonstration purposes only.
Model Overview
Unlike the previous pipeline (e.g., phoneme → mel-spectrogram → waveform), the pipeline of VALL-E is phoneme → discrete code → waveform. VALL-E generates the discrete audio codec codes based on phoneme and acoustic code prompts, corresponding to the target content and the speaker’s voice. VALL-E directly enables various speech synthesis applications, such as zero-shot TTS, speech editing, and content creation combined with other generative AI models like GPT.
Zero-shot TTS for LibriSpeech and VCTK dataset
-
Text Ground Truth Reconstruction (Encodec) Reconstruction (Vocos) Speaker Prompt (Prefix/Ref) Baseline Samples (YourTTS) VALL-E Samples
(Encodec)VALL-E Samples
(Vocos)They moved thereafter cautiously about the hut groping before and about them to find something to show that Warrenton had fulfilled his mission And lay me down in thy cold bed and leave my shining lot Number ten fresh nelly is waiting on you good night husband Yea his honourable worship is within but he hath a godly minister or two with him and likewise a leech Instead of shoes the old man wore boots with turnover tops and his blue coat had wide cuffs of gold braid The army found the people in poverty and left them in comparative wealth Thus did this humane and right minded father comfort his unhappy daughter and her mother embracing her again did all she could to soothe her feelings He was in deep converse with the clerk and entered the hall holding him by the arm
-
Text Ground Truth Reconstruction (Encodec) Reconstruction (Vocos) Speaker Prompt (3s_5s_10s) Baseline Samples (YourTTS) VALL-E Samples
(Encodec)VALL-E Samples
(Vocos)We have to reduce the number of plastic bags So what is the campaign about My life has changed a lot Nothing is yet confirmed I could hardly move for the next couple of days His son has been travelling with the Tartan Army for years Her husband was very concerned that it might be fatal We’ve made a couple of albums
Synthesis of diversity
-
Text Speaker Prompt VALL-E Sample1 VALL-E Sample2 Because we do not need it. I must do something about it. He has not been named. Number ten, fresh nelly is waiting on you, good night husband.
Acoustic environment maintenance
-
Text Ground Truth Reconstruction (Encodec) Reconstruction (Vocos) Speaker Prompt (3-second) Baseline Samples (YourTTS) VALL-E Samples
(Encodec)VALL-E Samples
(Vocos)Yeah really Well they were saying it was snowing in southern Florida yesterday I think it’s like you know um more convenient too Everything is run by computer but you got to know how to think before you can do a computer Then out in LA you guys got a whole other ballgame with California to worry about
Speaker emotion maintenance
-
Text Emotion Speaker Prompt (3-second) Baseline Samples (YourTTS) VALL-E Samples
(Encodec)VALL-E Samples
(Vocos)We have to reduce the number of plastic bags. Anger Sleepy Neutral Amused Disgusted
Ethics Statement
VALL-E could synthesize speech that maintains speaker identity and could be used for educational learning, entertainment, journalistic, self-authored content, accessibility features, interactive voice response systems, translation, chatbot, and so on. While VALL-E can speak in a voice like the voice talent, the similarity, and naturalness depend on the length and quality of the speech prompt, the background noise, as well as other factors. It may carry potential risks in the misuse of the model, such as spoofing voice identification or impersonating a specific speaker. We conducted the experiments under the assumption that the user agrees to be the target speaker in speech synthesis. If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model. If you suspect that VALL-E is being used in a manner that is abusive or illegal or infringes on your rights or the rights of other people, you can report it at the Report Abuse Portal.