
Domain mismatch and data augmentation in speech emotion recognition
- Dimitra Emmanouilidou ,
- Hannes Gamper ,
- Midia Yousefi
SMM24, Interspeech Workshop on Speech, Music and Mind 2024 |
Published by ISCA
Large, pretrained model architectures have demonstrated potential in a wide range of audio recognition and classification tasks. These architectures are increasingly being used in Speech Emotion Recognition (SER) as well, an area that continues to grapple with the scarcity of data, and especially of labeled data for training. This study is motivated by the limited research available on the robustness and generalization capabilities of these models for SER and considers applicability beyond a restricted dataset. We invoke the widely adopted net- work architecture CNN14 and explore its ability to generalize across different datasets. Our analysis demonstrates a potential domain gap between datasets after analyzing the acoustic properties of each one. We bridge this gap with the introduction of acoustic and data variability, by invoking seven suitable augmentation methods. Our approach leads to up to 8% improvement for unseen datasets. However, bridging the acoustic mismatch seems to play a minor role only: an infelicitous finding involving partially scrambled (swapped) annotation labels hints to deeper domain mismatches during multi-dataset learning scenarios. Findings in this work are applicable to any large or pretrained network and contribute to the ongoing research on the robustness and generalization of SER models.
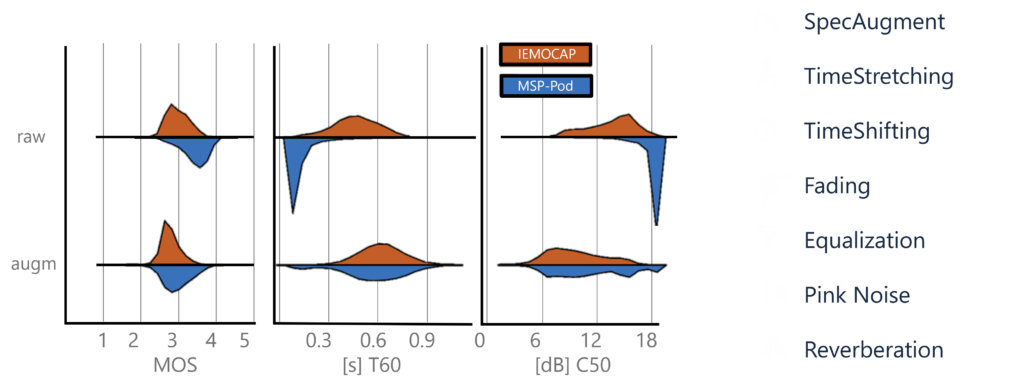
Figure: Distribution of estimated mean opinion score (MOS), reverberation time (T60), and clarity (C50) for IEMOCAP and MSP-Podcast, with and without data augmentation. Each statistical distribution shown is averaged over 10,000 random samples. Notice how the application of the selected augmentations (row augm.) bridges the distribution gap across datasets.
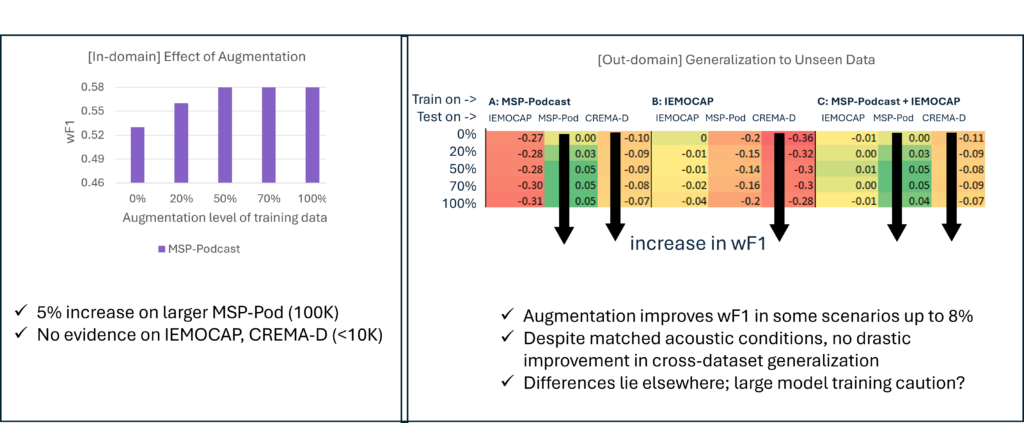
Figure: Effect of augmentations. Overall, the addition of augmentation seems to allow for performance improvement within a dataset and on unseen dataset scenarios, but it doesn’t seem to drastically improve cross-dataset generalization. The domain mismatches seem more intricate, and may go beyond acoustic conditions. Effect on baseline scenarios, Table 1: increasing amounts of augmentation improve wF1 by up to 5% for the large dataset MSP-Podcast, but the effect is not apparent for the smaller or less varied sets of IEMOCAP and CREMA-D. Effect on unseen data, Figure 2: the figure summarizes relative wF1 change at various rates of data augmentation during training (rows), and across datasets (columns). See Section 5 on interpreting relative wF1. Testing on unseen CREMA-D benefits from augmentation by as much as 3% column A, and 8% column B: from -0.36 wF1 drop to -0.28 drop. This is also evident in joint training column C. We further notice deterioration on unseen IEMOCAP column A, despite having bridged acoustic differences with augmentation.
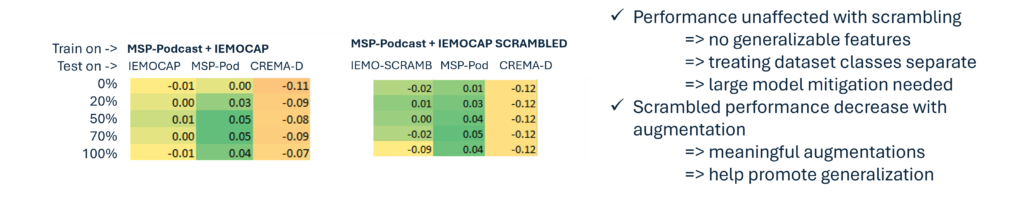
Figure: We introduce label scrambling only on IEMOCAP. We swap class labels Angry <-> Happy, and Sad<->Neutral. We then create a joined training scenario and add MSP-Podcast in training, together with the SCRAMBLED IEMOCAP. The assumption is, now that the acoustic conditions are matched between datasets, if the CNN14 model captures good/generalizable emotional features, then label scrambling should significantly confuse the model. The tables show before (left) and after (scrambling), where we see no particular effect in performance. The depicted table values correspond to relative change in wF1, relative compared to the baseline scenario when we train on the same dataset as the one we test on.